Spark Streaming源码解读之Driver中的ReceiverTracker详解
本篇博文的目标是:
Driver的ReceiverTracker接收到数据之后,下一步对数据是如何进行管理
一:ReceiverTracker的架构设计
1. Driver在Executor启动Receiver方式,每个Receiver都封装成一个Task,此时一个Job中就一个Task,而Task中就一条数据,也就是Receiver数据。由此,多少个Job也就可以启动多少个Receiver.
2. ReceiverTracker在启动Receiver的时候他有ReceiverSupervisor,其实现是ReceiverSupervisorImpl, ReceiverSupervisor本身启动的时候会启动Receiver,Receiver不断的接收数据,通过BlockGenerator将数据转换成Block。定时器会不断的把Block数据通过BlockManager或者WAL进行存储,数据存储之后ReceiverSupervisorImpl会把存储后的数据的元数据Metadate汇报给ReceiverTracker,其实是汇报给ReceiverTracker中的RPC实体ReceiverTrackerEndpoint.
ReceiverSupervisorImpl会将元数据汇报给ReceiverTracker,那么接收到之后,下一步就对数据进行管理。
- 通过receivedBlockHandler写数据
private val receivedBlockHandler: ReceivedBlockHandler = {
if (WriteAheadLogUtils.enableReceiverLog(env.conf)) {
if (checkpointDirOption.isEmpty) {
throw new SparkException(
"Cannot enable receiver write-ahead log without checkpoint directory set. " +
"Please use streamingContext.checkpoint() to set the checkpoint directory. " +
"See documentation for more details.")
}
//WAL
new WriteAheadLogBasedBlockHandler(env.blockManager, receiver.streamId,
receiver.storageLevel, env.conf, hadoopConf, checkpointDirOption.get)
} else {
//BlockManager
new BlockManagerBasedBlockHandler(env.blockManager, receiver.storageLevel)
}
}
2. PushAndReportBlock存储Block数据,且把信息汇报给Driver。
/** Store block and report it to driver */
def pushAndReportBlock(
receivedBlock: ReceivedBlock,
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
) {
val blockId = blockIdOption.getOrElse(nextBlockId)
val time = System.currentTimeMillis
val blockStoreResult = receivedBlockHandler.storeBlock(blockId, receivedBlock)
logDebug(s"Pushed block $blockId in ${(System.currentTimeMillis - time)} ms")
val numRecords = blockStoreResult.numRecords
val blockInfo = ReceivedBlockInfo(streamId, numRecords, metadataOption, blockStoreResult)
trackerEndpoint.askWithRetry[Boolean](AddBlock(blockInfo))
logDebug(s"Reported block $blockId")
}
3. 此时trackerEndpoint是ReceiverTrackerEndpoint
/** Remote RpcEndpointRef for the ReceiverTracker */
private val trackerEndpoint = RpcUtils.makeDriverRef("ReceiverTracker", env.conf, env.rpcEnv)
4. ReceivedBlockInfo:封装Block的存储信息。
/** Information about blocks received by the receiver */
private[streaming] case class ReceivedBlockInfo(
streamId: Int, //block属于哪个接收的流
numRecords: Option[Long],//多少条记录
metadataOption: Option[Any],//元数据信息
blockStoreResult: ReceivedBlockStoreResult
) {
require(numRecords.isEmpty || numRecords.get >= 0, "numRecords must not be negative")
@volatile private var _isBlockIdValid = true
def blockId: StreamBlockId = blockStoreResult.blockId
def walRecordHandleOption: Option[WriteAheadLogRecordHandle] = {
blockStoreResult match {
case walStoreResult: WriteAheadLogBasedStoreResult => Some(walStoreResult.walRecordHandle)
case _ => None
}
}
/** Is the block ID valid, that is, is the block present in the Spark executors. */
def isBlockIdValid(): Boolean = _isBlockIdValid
/**
* Set the block ID as invalid. This is useful when it is known that the block is not present
* in the Spark executors.
*/
def setBlockIdInvalid(): Unit = {
_isBlockIdValid = false
}
}
5. ReceivedBlockStoreResult:
/** Trait that represents the metadata related to storage of blocks */
private[streaming] trait ReceivedBlockStoreResult {
// Any implementation of this trait will store a block id
def blockId: StreamBlockId
// Any implementation of this trait will have to return the number of records
def numRecords: Option[Long]
}
ReceiverTracker的源码源码遍历
1. 下面的消息是完成Receiver和ReceiverTracker之间通信的。
/**
* Messages used by the NetworkReceiver and the ReceiverTracker to communicate
* with each other.
*/
//这里使用sealed意思是ReceiverTrackerMessage包含所有的消息。
private[streaming] sealed trait ReceiverTrackerMessage
private[streaming] case class RegisterReceiver(
streamId: Int,
typ: String,
host: String,
executorId: String,
receiverEndpoint: RpcEndpointRef
) extends ReceiverTrackerMessage
private[streaming] case class AddBlock(receivedBlockInfo: ReceivedBlockInfo)
extends ReceiverTrackerMessage
private[streaming] case class ReportError(streamId: Int, message: String, error: String)
private[streaming] case class DeregisterReceiver(streamId: Int, msg: String, error: String)
extends ReceiverTrackerMessage
2. Driver和ReceiverTrackerEndpoint之间的交流通过ReceiverTrackerLocalMessage。
/**
* Messages used by the driver and ReceiverTrackerEndpoint to communicate locally.
*/
private[streaming] sealed trait ReceiverTrackerLocalMessage
3. ReceiverTrackerLocalMessage中的子类
/**
* This message will trigger ReceiverTrackerEndpoint to restart a Spark job for the receiver.
*/
//从起Receiver
private[streaming] case class RestartReceiver(receiver: Receiver[_])
extends ReceiverTrackerLocalMessage
/**
* This message is sent to ReceiverTrackerEndpoint when we start to launch Spark jobs for receivers
* at the first time.
*/
//启动Receiver的集合
private[streaming] case class StartAllReceivers(receiver: Seq[Receiver[_]])
extends ReceiverTrackerLocalMessage
/**
* This message will trigger ReceiverTrackerEndpoint to send stop signals to all registered
* receivers.
*/
//程序结束的时候会发出停止所有Receiver的信息。
private[streaming] case object StopAllReceivers extends ReceiverTrackerLocalMessage
/**
* A message used by ReceiverTracker to ask all receiver's ids still stored in
* ReceiverTrackerEndpoint.
*/
//正在存信息的是ReceiverTrackerEndpoint
private[streaming] case object AllReceiverIds extends ReceiverTrackerLocalMessage
// UpdateReceiverRateLimit实例可能会有几个,因此在程序运行的时候需要限流。
private[streaming] case class UpdateReceiverRateLimit(streamUID: Int, newRate: Long)
extends ReceiverTrackerLocalMessage
4. ReceiverTracker:管理Receiver的启动,Receiver的执行,回收,执行过程中接收数据的管理。DStreamGraph中会有成员记录所有的数据流来源,免得每次都去检索。
/**
* This class manages the execution of the receivers of ReceiverInputDStreams. Instance of
* this class must be created after all input streams have been added and StreamingContext.start()
* has been called because it needs the final set of input streams at the time of instantiation.
*
* @param skipReceiverLaunch Do not launch the receiver. This is useful for testing.
*/
private[streaming]
class ReceiverTracker(ssc: StreamingContext, skipReceiverLaunch: Boolean = false) extends Logging {
//所有的InputStream都会交给graph
private val receiverInputStreams = ssc.graph.getReceiverInputStreams()
private val receiverInputStreamIds = receiverInputStreams.map { _.id }
private val receivedBlockTracker = new ReceivedBlockTracker(
ssc.sparkContext.conf,
ssc.sparkContext.hadoopConfiguration,
receiverInputStreamIds,
ssc.scheduler.clock,
ssc.isCheckpointPresent,
Option(ssc.checkpointDir)
)
private val listenerBus = ssc.scheduler.listenerBus
ReceiverTracker中的receiverAndReply:
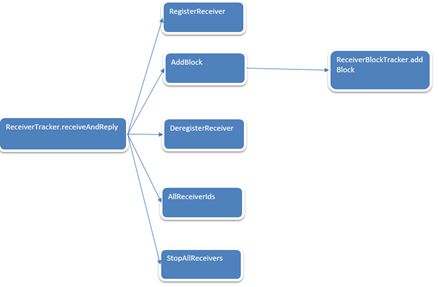
- ReceiverTrackerEndpoint接收消息,并回复addBlock消息。
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// Remote messages
case RegisterReceiver(streamId, typ, host, executorId, receiverEndpoint) =>
val successful =
registerReceiver(streamId, typ, host, executorId, receiverEndpoint, context.senderAddress)
context.reply(successful)
case AddBlock(receivedBlockInfo) =>
if (WriteAheadLogUtils.isBatchingEnabled(ssc.conf, isDriver = true)) {
walBatchingThreadPool.execute(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
if (active) {
context.reply(addBlock(receivedBlockInfo))
} else {
throw new IllegalStateException("ReceiverTracker RpcEndpoint shut down.")
}
}
})
} else {
context.reply(addBlock(receivedBlockInfo))
}
case DeregisterReceiver(streamId, message, error) =>
deregisterReceiver(streamId, message, error)
context.reply(true)
// Local messages
//查看是否有活跃的Receiver
case AllReceiverIds =>
context.reply(receiverTrackingInfos.filter(_._2.state != ReceiverState.INACTIVE).keys.toSeq)
//停止所有Receivers
case StopAllReceivers =>
assert(isTrackerStopping || isTrackerStopped)
stopReceivers()
context.reply(true)
}
2. addBlock源码如下:
/** Add new blocks for the given stream */
private def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = {
receivedBlockTracker.addBlock(receivedBlockInfo)
}
3. ReceiverBlockTracker的addBlock源码如下:把具体的一个Receiver汇报上来的数据的元数据信息写入streamIdToUnallocatedBlockQueues中。
/** Add received block. This event will get written to the write ahead log (if enabled). */
def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = {
try {
val writeResult = writeToLog(BlockAdditionEvent(receivedBlockInfo))
if (writeResult) {
synchronized {
getReceivedBlockQueue(receivedBlockInfo.streamId) += receivedBlockInfo
}
logDebug(s"Stream ${receivedBlockInfo.streamId} received " +
s"block ${receivedBlockInfo.blockStoreResult.blockId}")
} else {
logDebug(s"Failed to acknowledge stream ${receivedBlockInfo.streamId} receiving " +
s"block ${receivedBlockInfo.blockStoreResult.blockId} in the Write Ahead Log.")
}
writeResult
} catch {
case NonFatal(e) =>
logError(s"Error adding block $receivedBlockInfo", e)
false
}
}
其中getReceivedBlockQueue是ReceivedBlockQueue类型。
/** Get the queue of received blocks belonging to a particular stream */
private def getReceivedBlockQueue(streamId: Int): ReceivedBlockQueue = {
streamIdToUnallocatedBlockQueues.getOrElseUpdate(streamId, new ReceivedBlockQueue)
}
4. 其中HashMap中第一个参数是StreamId,第二个参数ReceivedBlockQueue是StreamId对应接收到的Receiver.
private val streamIdToUnallocatedBlockQueues = new mutable.HashMap[Int, ReceivedBlockQueue]5. WritetToLog源码如下:
/** Write an update to the tracker to the write ahead log */
private def writeToLog(record: ReceivedBlockTrackerLogEvent): Boolean = {
if (isWriteAheadLogEnabled) { //先判断是否可以写入到log中。
logTrace(s"Writing record: $record")
try {
//write方法将数据写入 writeAheadLogOption.get.write(ByteBuffer.wrap(Utils.serialize(record)),
clock.getTimeMillis())
true
} catch {
case NonFatal(e) =>
logWarning(s"Exception thrown while writing record: $record to the WriteAheadLog.", e)
false
}
} else {
true
}
}
ReceiverBlockTracker源码分析:
1. 保持跟踪所有接收到的Block。并且根据需要把他们分配给batches.
假设提供checkpoint的话,ReceiverBlockTracker中的信息包括receiver接收到的block数据和分配的信息。Driver如果失败的话,就读取checkpoint中的信息。
/**
* Class that keep track of all the received blocks, and allocate them to batches
* when required. All actions taken by this class can be saved to a write ahead log
* (if a checkpoint directory has been provided), so that the state of the tracker
* (received blocks and block-to-batch allocations) can be recovered after driver failure.
*
* Note that when any instance of this class is created with a checkpoint directory,
* it will try reading events from logs in the directory.
*/
private[streaming] class ReceivedBlockTracker(
2. ReceivedBlockTracker通过调用allocateBlocksToBatch方法把接收到的数据分配给当前执行的Batch Duractions作业。
allocateBlocksToBatch被JobGenerator调用的。
/**
* Allocate all unallocated blocks to the given batch.
* This event will get written to the write ahead log (if enabled).
*/
def allocateBlocksToBatch(batchTime: Time): Unit = synchronized {
if (lastAllocatedBatchTime == null || batchTime > lastAllocatedBatchTime) {
val streamIdToBlocks = streamIds.map { streamId =>
(streamId, getReceivedBlockQueue(streamId).dequeueAll(x => true))
}.toMap
val allocatedBlocks = AllocatedBlocks(streamIdToBlocks)
if (writeToLog(BatchAllocationEvent(batchTime, allocatedBlocks))) {
// allocatedBlocks是接收到数据
// batchTime 是时间
timeToAllocatedBlocks.put(batchTime, allocatedBlocks)
//每次分配的时候都会更新时间
lastAllocatedBatchTime = batchTime
} else {
logInfo(s"Possibly processed batch $batchTime need to be processed again in WAL recovery")
}
} else {
// This situation occurs when:
// 1. WAL is ended with BatchAllocationEvent, but without BatchCleanupEvent,
// possibly processed batch job or half-processed batch job need to be processed again,
// so the batchTime will be equal to lastAllocatedBatchTime.
// 2. Slow checkpointing makes recovered batch time older than WAL recovered
// lastAllocatedBatchTime.
// This situation will only occurs in recovery time.
logInfo(s"Possibly processed batch $batchTime need to be processed again in WAL recovery")
}
}
JobGenerator中的generateJob
/** Generate jobs and perform checkpoint for the given `time`. */
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
//
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
3. AllocatedBlocks源码如下:
/** Class representing the blocks of all the streams allocated to a batch */
private[streaming]
case class AllocatedBlocks(streamIdToAllocatedBlocks: Map[Int, Seq[ReceivedBlockInfo]]) {
def getBlocksOfStream(streamId: Int): Seq[ReceivedBlockInfo] = {
streamIdToAllocatedBlocks.getOrElse(streamId, Seq.empty)
}
}
ReceiverTracker的receive方法架构如下:
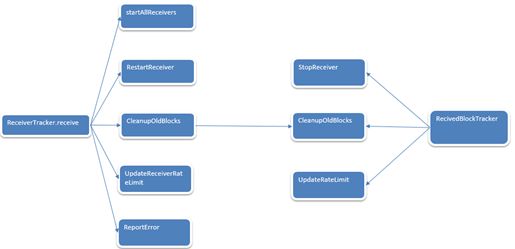
4. ReceiverTracker中receive源码如下:
override def receive: PartialFunction[Any, Unit] = {
// Local messages
//启动所有的receivers,在ReceiverTracker刚启动的时候会给自己发消息,通过//schedulingPolicy来触发消息。
case StartAllReceivers(receivers) =>
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors)
for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
//当Executor帮我们分配Receiver或者Receiver失效,然后给自己发消息触发Receiver重新分发。
case RestartReceiver(receiver) =>
// Old scheduled executors minus the ones that are not active any more
val oldScheduledExecutors = getStoredScheduledExecutors(receiver.streamId)
val scheduledLocations = if (oldScheduledExecutors.nonEmpty) {
// Try global scheduling again
oldScheduledExecutors
} else {
val oldReceiverInfo = receiverTrackingInfos(receiver.streamId)
// Clear "scheduledLocations" to indicate we are going to do local scheduling
val newReceiverInfo = oldReceiverInfo.copy(
state = ReceiverState.INACTIVE, scheduledLocations = None)
receiverTrackingInfos(receiver.streamId) = newReceiverInfo
schedulingPolicy.rescheduleReceiver(
receiver.streamId,
receiver.preferredLocation,
receiverTrackingInfos,
getExecutors)
}
// Assume there is one receiver restarting at one time, so we don't need to update
// receiverTrackingInfos
startReceiver(receiver, scheduledLocations)
//当我们快要完成数据计算的时候,会发送此消息,将所有的Receiver交给我们
case c: CleanupOldBlocks =>
receiverTrackingInfos.values.flatMap(_.endpoint).foreach(_.send(c))
// ReceiverTracker可以动态的调整Receiver接收的RateLimit
case UpdateReceiverRateLimit(streamUID, newRate) =>
for (info <- receiverTrackingInfos.get(streamUID); eP <- info.endpoint) {
eP.send(UpdateRateLimit(newRate))
}
// Remote messages
//
case ReportError(streamId, message, error) =>
reportError(streamId, message, error)
}
5. 在ReceiverSupervisorImpl的receive方法中就接收到了ReceiverTracker的CleanupOldBlocks消息。
/** RpcEndpointRef for receiving messages from the ReceiverTracker in the driver */
private val endpoint = env.rpcEnv.setupEndpoint(
"Receiver-" + streamId + "-" + System.currentTimeMillis(), new ThreadSafeRpcEndpoint {
override val rpcEnv: RpcEnv = env.rpcEnv
override def receive: PartialFunction[Any, Unit] = {
case StopReceiver =>
logInfo("Received stop signal")
ReceiverSupervisorImpl.this.stop("Stopped by driver", None)
case CleanupOldBlocks(threshTime) =>
logDebug("Received delete old batch signal")
//根据时间就clean Old Block
cleanupOldBlocks(threshTime)
//
case UpdateRateLimit(eps) =>
logInfo(s"Received a new rate limit: $eps.")
registeredBlockGenerators.foreach { bg =>
bg.updateRate(eps)
}
}
})
6. RateLimiter中的updateRate源码如下:
/**
* Set the rate limit to `newRate`. The new rate will not exceed the maximum rate configured by
* {{{spark.streaming.receiver.maxRate}}}, even if `newRate` is higher than that.
*
* @param newRate A new rate in events per second. It has no effect if it's 0 or negative.
*/
private[receiver] def updateRate(newRate: Long): Unit =
if (newRate > 0) {
if (maxRateLimit > 0) {
rateLimiter.setRate(newRate.min(maxRateLimit))
} else {
rateLimiter.setRate(newRate)
}
}
}
7. 其中setRate源码如下:
/**
* Updates the stable rate of this {@code RateLimiter}, that is, the
* {@code permitsPerSecond} argument provided in the factory method that
* constructed the {@code RateLimiter}. Currently throttled threads will not
* be awakened as a result of this invocation, thus they do not observe the new rate;
* only subsequent requests will.
*
* Note though that, since each request repays (by waiting, if necessary) the cost
* of the previous request, this means that the very next request
* after an invocation to {@code setRate} will not be affected by the new rate;
* it will pay the cost of the previous request, which is in terms of the previous rate.
*
*
The behavior of the {@code RateLimiter} is not modified in any other way,
* e.g. if the {@code RateLimiter} was configured with a warmup period of 20 seconds,
* it still has a warmup period of 20 seconds after this method invocation.
*
* @param permitsPerSecond the new stable rate of this {@code RateLimiter}.
*/
public final void setRate(double permitsPerSecond) {
Preconditions.checkArgument(permitsPerSecond > 0.0
&& !Double.isNaN(permitsPerSecond), "rate must be positive");
synchronized (mutex) {
resync(readSafeMicros());
double stableIntervalMicros = TimeUnit.SECONDS.toMicros(1L) / permitsPerSecond;
this.stableIntervalMicros = stableIntervalMicros;
doSetRate(permitsPerSecond, stableIntervalMicros);
}
}
ReceiverTracker中receiveAndReply中StopAllReceivers流程如下:
1. stopReceivers源码如下:
/** Send stop signal to the receivers. */
private def stopReceivers() {
receiverTrackingInfos.values.flatMap(_.endpoint).foreach
//给ReceiverSupervisorImpl发送消息。
{ _.send(StopReceiver) }
logInfo("Sent stop signal to all " + receiverTrackingInfos.size + " receivers")
}
}
2. 在ReceiverSupervisorImpl中receive接收到了此消息。
/** RpcEndpointRef for receiving messages from the ReceiverTracker in the driver */
private val endpoint = env.rpcEnv.setupEndpoint(
"Receiver-" + streamId + "-" + System.currentTimeMillis(), new ThreadSafeRpcEndpoint {
override val rpcEnv: RpcEnv = env.rpcEnv
override def receive: PartialFunction[Any, Unit] = {
case StopReceiver =>
logInfo("Received stop signal")
ReceiverSupervisorImpl.this.stop("Stopped by driver", None)
case CleanupOldBlocks(threshTime) =>
logDebug("Received delete old batch signal")
cleanupOldBlocks(threshTime)
case UpdateRateLimit(eps) =>
logInfo(s"Received a new rate limit: $eps.")
registeredBlockGenerators.foreach { bg =>
bg.updateRate(eps)
}
}
})
3. stop函数在ReceiverSupervisor中实现的。
/** Mark the supervisor and the receiver for stopping */
def stop(message: String, error: Option[Throwable]) {
stoppingError = error.orNull
stopReceiver(message, error)
onStop(message, error)
futureExecutionContext.shutdownNow()
stopLatch.countDown()
}
4. stopReceiver源码如下:
/** Stop receiver */
def stopReceiver(message: String, error: Option[Throwable]): Unit = synchronized {
try {
logInfo("Stopping receiver with message: " + message + ": " + error.getOrElse(""))
receiverState match {
case Initialized =>
logWarning("Skip stopping receiver because it has not yet stared")
case Started =>
receiverState = Stopped
receiver.onStop()
logInfo("Called receiver onStop")
onReceiverStop(message, error)
case Stopped =>
logWarning("Receiver has been stopped")
}
} catch {
case NonFatal(t) =>
logError("Error stopping receiver " + streamId + t.getStackTraceString)
}
}
5. 最终调用onStop方法
/**
* This method is called by the system when the receiver is stopped. All resources
* (threads, buffers, etc.) setup in `onStart()` must be cleaned up in this method.
*/
def onStop()
6. onReceiverStop方法在子类ReceiverSupervisorImpl中会有具体实现。
override protected def onReceiverStop(message: String, error: Option[Throwable]) {
logInfo("Deregistering receiver " + streamId)
val errorString = error.map(Throwables.getStackTraceAsString).getOrElse("")
//告诉Driver端也就是ReceiverTracker调用DeregisterReceiver
trackerEndpoint.askWithRetry[Boolean](DeregisterReceiver(streamId, message, errorString))
logInfo("Stopped receiver " + streamId)
}
7. onStop方法在ReceiverSupervisorImpl中实现如下:
override protected def onStop(message: String, error: Option[Throwable]) {
registeredBlockGenerators.foreach { _.stop() }
//停止消息循环
env.rpcEnv.stop(endpoint)
}
StopAllReceivers全流程如下:

总结:
Receiver接收到数据之后合并存储数据后,ReceiverSupervisorImpl会把数据汇报给ReceiverTracker, ReceiverTracker接收到元数据,其内部汇报的是RPC通信体,接收到数据之后,内部有ReceivedBlockTracker会管理数据的分配,JobGenerator会将每个Batch,每次工作的时候会根据元数据信息从ReceiverTracker中获取相应的元数据信息生成RDD。
ReceiverBlockTracker中 allocateBlocksToBatch专门管理Block元数据信息,作为一个内部的管理对象。
门面设计模式:
ReceiverTracker和ReceivedBlockTracker的关系是:具体干活的是ReceivedBlockTracker,但是外部代表是ReceiverTracker。
private type ReceivedBlockQueue = mutable.Queue[ReceivedBlockInfo]
//为每个Receiver单独维护一个Queue
// streamIdToUnallocatedBlockQueues里面封装的是所有汇报上来的数据,但是没有被分配的数据。
private val streamIdToUnallocatedBlockQueues = new mutable.HashMap[Int, ReceivedBlockQueue]
//维护的是已经分配到Batch的元数据信息。
private val timeToAllocatedBlocks = new mutable.HashMap[Time, AllocatedBlocks]
private val writeAheadLogOption = createWriteAheadLog()
private var lastAllocatedBatchTime: Time = null
JobGenerator在计算基于Batch的Job的时候,我们的DStreamGraph生成RDD的DAG的时候会调用此方法。
/** Get the blocks allocated to the given batch. */
//此方法就会生成RDD。
def getBlocksOfBatch(batchTime: Time): Map[Int, Seq[ReceivedBlockInfo]] = synchronized {
timeToAllocatedBlocks.get(batchTime).map { _.streamIdToAllocatedBlocks }.getOrElse(Map.empty)
}
当一个Batch计算完的时候,他会把已经使用的数据块的数据信息清理掉。
/**
* Clean up block information of old batches. If waitForCompletion is true, this method
* returns only after the files are cleaned up.
*/
def cleanupOldBatches(cleanupThreshTime: Time, waitForCompletion: Boolean): Unit = synchronized {
require(cleanupThreshTime.milliseconds < clock.getTimeMillis())
val timesToCleanup = timeToAllocatedBlocks.keys.filter { _ < cleanupThreshTime }.toSeq
logInfo("Deleting batches " + timesToCleanup)
if (writeToLog(BatchCleanupEvent(timesToCleanup))) {
timeToAllocatedBlocks --= timesToCleanup
writeAheadLogOption.foreach(_.clean(cleanupThreshTime.milliseconds, waitForCompletion))
} else {
logWarning("Failed to acknowledge batch clean up in the Write Ahead Log.")
}
}