GraphX简介及GraphFrames测试
目录
概观
架构
存储
图的构造
GraphFrames
安装
测试
参考
概观
GraphX是Spark中用于图和图计算的组件,GraphX通过扩展Spark RDD引入了一个新的图抽象数据结构,一个将有效信息放入顶点和边的有向多重图。如同Spark的每一个模块一样,它们都有一个基于RDD的便于自己计算的抽象数据结构(如SQL的DataFrame,Streaming的DStream)。为了方便与图计算,GraphX公开了一系列基本运算(InDegress,OutDegress,subgraph等等 ),也有许多用于图计算算法工具包(PageRank,TriangleCount,ConnectedComponents等等算法)。
相对于其他分布式图计算框架,Graphx最大的贡献,也是大多数开发喜欢它的原因是,在Spark之上提供了一站式解决方案,可以方便且高效地完成图计算的一整套流水作业;即在实际开发中,可以使用核心模块来完成海量数据的清洗与与分析阶段,SQL模块来打通与数据仓库的通道,Streaming打造实时流处理通道,基于GraphX图计算算法来对网页中复杂的业务关系进行计算,最后使用MLLib以及SparkR来完成数据挖掘算法处理。
架构
Spark的每一个模块,都有自己的抽象数据结构,GraphX的核心抽象是弹性分布式属性图(resilient distribute property graph),一种点和边都带有属性的有向多重图。它同时拥有Table和Graph两种视图,而只需一种物理存储,这两种操作符都有自己独有的操作符,从而获得灵活的操作和较高的执行效率。
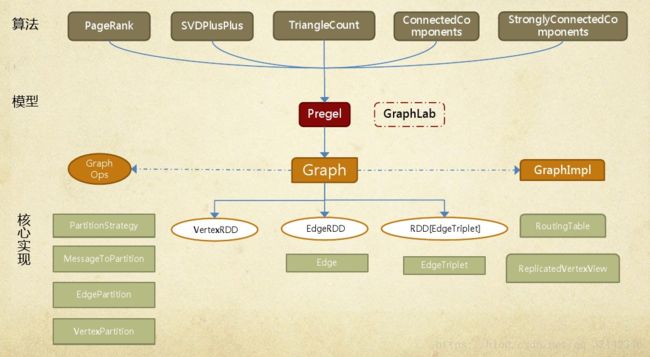
GraphX的整体架构可以分为三个部分:
- 存储层和原语层:Graph类是图计算的核心类,内部含有VertexRDD、EdgeRDD和RDD[EdgeTriplet]引用。GraphImpl是Graph类的子类,实现了图操作。
- 接口层:在底层RDD的基础之上实现Pragel模型,BSP模式的计算接口。
- 算法层:基于Pregel接口实现了常用的图算法。包含:PageRank、SVDPlusPlus、TriangleCount、ConnectedComponents、StronglyConnectedConponents等算法。
存储
与RDD一样,Spark中图是不可变的,分布式的和容错的
- 通过生成具有所需更改的新图来完成对图的值或结构的更改。
- 原始图形的大部分(即未受影响的结构,属性和索引)在新图形中重复使用,从而降低了此固有功能数据结构的成本。
- 使用一系列顶点分区启发法将图形划分为执行程序。与RDD一样,图形的每个分区都可以在发生故障时在不同的机器上重新创建。
GraphX采用顶点切割方法进行分布式图分区:
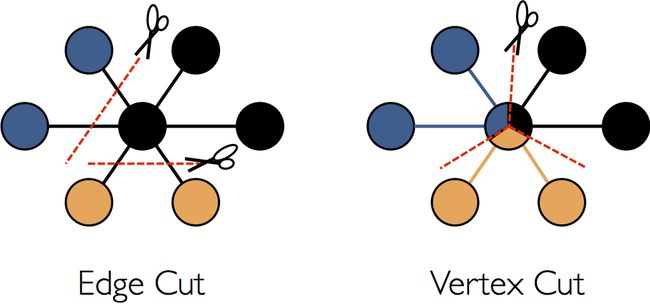
GraphX不是沿着边缘分割图形,而是沿着顶点划分图形,这样好处在于边上没有冗余的数据,而且对于某个点与它的邻居的交互操作,只要满足交换律和结合律即可。不过点分割这样做的代价是有的顶点的属性可能要冗余存储多份,更新点数据时要有数据同步开销(真实事件联系数远大于顶点数)。
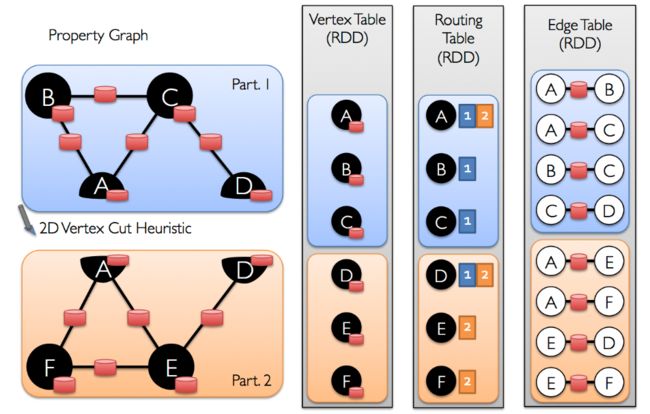
一旦顶点的边缘被分割,有效图形并行计算的关键挑战就是有效地将顶点属性与边缘连接起来。因为真实世界的图形通常具有比顶点更多的边缘,所以我们将顶点属性移动到边缘。因为并非所有分区都包含与所有顶点相邻的边,所以GraphX内部维持了一个路由表(routing table),这样当广播点的边的所在区时就可以通过路由表映射,将需要的顶点属性传输到边分区。
图的构造
逻辑上,属性图对应于编码每个顶点和边的属性的一对类型集(RDD)。因此,图类包含访问图的顶点和边类VertexRDD[VD]和EdgeRDD[ED]延伸:
class Graph[VD, ED] {
val vertices: VertexRDD[VD]
val edges: EdgeRDD[ED]
}
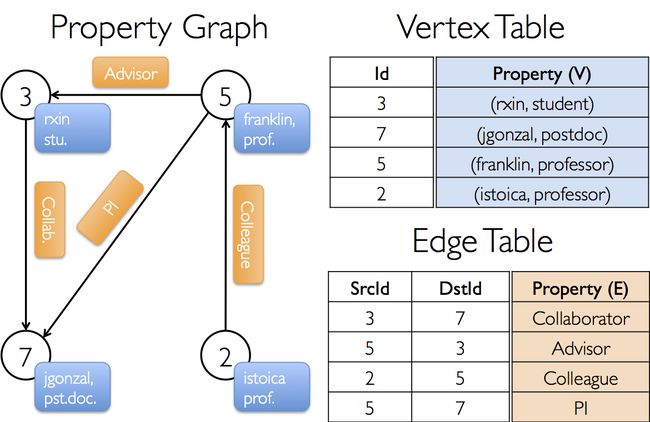
使用Graph类构造图的一个例子
// Assume the SparkContext has already been constructed
val sc: SparkContext
// Create an RDD for the vertices
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Array((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "prof")), (2L, ("istoica", "prof"))))
// Create an RDD for edges
val relationships: RDD[Edge[String]] =
sc.parallelize(Array(Edge(3L, 7L, "collab"), Edge(5L, 3L, "advisor"),
Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi")))
// Define a default user in case there are relationship with missing user
val defaultUser = ("John Doe", "Missing")
// Build the initial Graph
val graph = Graph(users, relationships, defaultUser)除了VertexRDD和EdgeRDD外,GraphX还定义了RDD[EdgeTriplet[VD, ED]],在逻辑上表示连接顶点和边缘属性

GraphFrames
GraphFrames,该类库是构建在Spark DataFrames之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。GraphX基于RDD API,不支持Python API; 但GraphFrame基于DataFrame,并且支持Python API。
目前GraphFrames还未集成到Spark中,而是作为单独的项目存在。GraphFrames遵循与Spark相同的代码质量标准,并且它是针对大量Spark版本进行交叉编译和发布的。
与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,有下面几方面的优势:
1、统一的 API: 为Python、Java和Scala三种语言提供了统一的接口,这是Python和Java首次能够使用GraphX的全部算法。
2、强大的查询功能:GraphFrames使得用户可以构建与Spark SQL以及DataFrame类似的查询语句。
3、图的存储和读取:GraphFrames与DataFrame的数据源完全兼容,支持以Parquet、JSON以及CSV等格式完成图的存储或读取。
在GraphFrames中图的顶点(Vertex)和边(Edge)都是以DataFrame形式存储的,所以一个图的所有信息都能够完整保存。
4、GraphFrames可以实现与GraphX的完美集成。两者之间相互转换时不会丢失任何数据。
val graph = Graph(...)
val graphFrame =GraphFrame.fromGraphX(graph)安装
环境是mac OS 12
1. 用pip安装 graphFrames
pip install graphframes
2. 在https://spark-packages.org/package/graphframes/graphframes下载对应版本的jar包
放在pyspark/jars下,比如... /miniconda3/lib/python3.6/site-packages/pyspark/jars/
测试
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from graphframes import *
spark = SparkSession.builder \
.master("local") \
.appName("graphframe test") \
.getOrCreate()
def create_transport_graph():
node_fields = [
StructField("id", StringType(), True),
StructField("latitude", FloatType(), True),
StructField("longitude", FloatType(), True),
StructField("population", IntegerType(), True)
]
nodes = spark.read.csv("data/transport-nodes.csv", header=True,
schema=StructType(node_fields))
rels = spark.read.csv("data/transport-relationships.csv", header=True)
reversed_rels = (rels.withColumn("newSrc", rels.dst)
.withColumn("newDst", rels.src)
.drop("dst", "src")
.withColumnRenamed("newSrc", "src")
.withColumnRenamed("newDst", "dst")
.select("src", "dst", "relationship", "cost"))
relationships = rels.union(reversed_rels)
return GraphFrame(nodes, relationships)
# 生成图
g = create_transport_graph()
# 顶点筛选
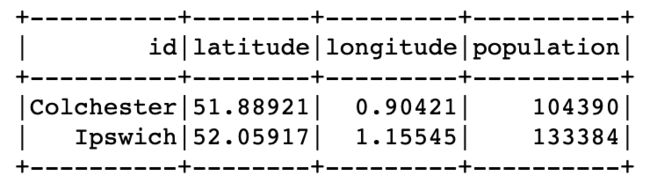
g.vertices.filter("population > 100000 and population < 300000").sort("population").show()
# 计算BFS
from_expr = "id='Den Haag'"
to_expr = "population > 100000 and population < 300000 and id <> 'Den Haag'"
result = g.bfs(from_expr, to_expr)
columns = [column for column in result.columns if not column.startswith("e")]
result.select(columns).show()
# 计算PageRank
pr = g.pageRank(maxIter=10)
pr.vertices.show()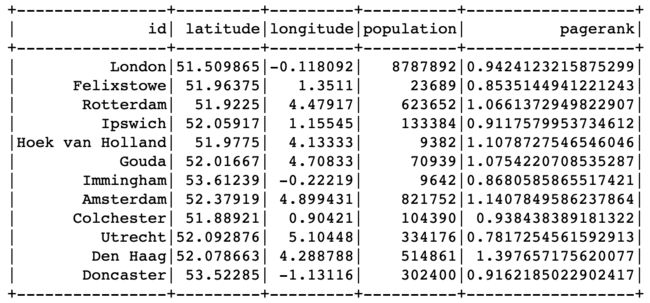
测试用到的数据
transport-nodes.csv
id,latitude,longitude,population
"Amsterdam",52.379189,4.899431,821752
"Utrecht",52.092876,5.104480,334176
"Den Haag",52.078663,4.288788,514861
"Immingham",53.61239,-0.22219,9642
"Doncaster",53.52285,-1.13116,302400
"Hoek van Holland",51.9775,4.13333,9382
"Felixstowe",51.96375,1.3511,23689
"Ipswich",52.05917,1.15545,133384
"Colchester",51.88921,0.90421,104390
"London",51.509865,-0.118092,8787892
"Rotterdam",51.9225,4.47917,623652
"Gouda",52.01667,4.70833,70939transport-relationships.csv
src,dst,relationship,cost
"Amsterdam","Utrecht","EROAD",46
"Amsterdam","Den Haag","EROAD",59
"Den Haag","Rotterdam","EROAD",26
"Amsterdam","Immingham","EROAD",369
"Immingham","Doncaster","EROAD",74
"Doncaster","London","EROAD",277
"Hoek van Holland","Den Haag","EROAD",27
"Felixstowe","Hoek van Holland","EROAD",207
"Ipswich","Felixstowe","EROAD",22
"Colchester","Ipswich","EROAD",32
"London","Colchester","EROAD",106
"Gouda","Rotterdam","EROAD",25
"Gouda","Utrecht","EROAD",35
"Den Haag","Gouda","EROAD",32
"Hoek van Holland","Rotterdam","EROAD",33
参考
1. Spark GraphX 官方文档 http://spark.apache.org/docs/latest/graphx-programming-guide.html
2.Spark GraphX图计算框架原理概述 https://blog.csdn.net/qq_37142346/article/details/82016770
3.GraphFrames初探 https://www.jianshu.com/p/d612fd2f4310
4.neo4j 官方电子书 Graph_Algorithms_Neo4j https://neo4j.com/graph-algorithms-book