Spark Streaming之:Flume监控目录下文件内容变化,然后Spark Streaming实时监听Flume,然后从其上拉取数据,并计算出结果
1、安装flume
2、到Spark-Streaming官网下载poll方式的Sink
3、将sink放入到flume的lib包里面
4、先启动flume(多个),然后在启动Streaming程序
下载spark-flume
http://spark.apache.org/documentation.html
到Spark-1.6.2中
http://spark.apache.org/docs/1.6.2/,

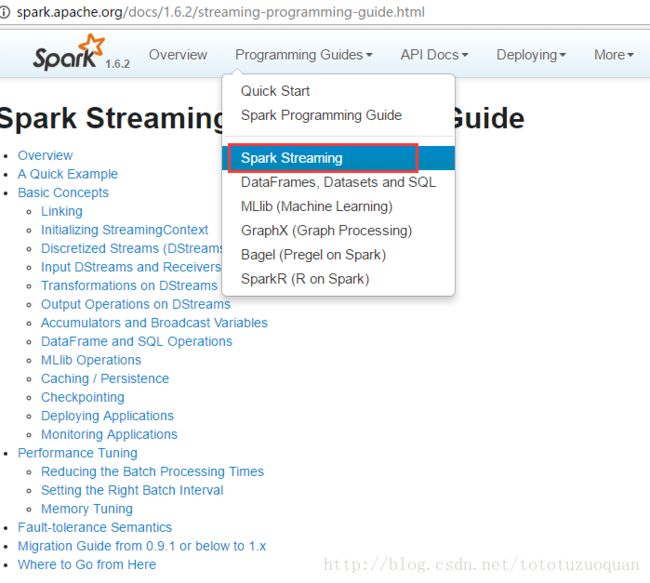
搜一下flume
最后在安装的flume中加入:commons-lang3-3.3.2.jar、scala-library-2.10.5.jar、spark-streaming-flume-sink_2.10-1.6.1.jar,效果如右侧:
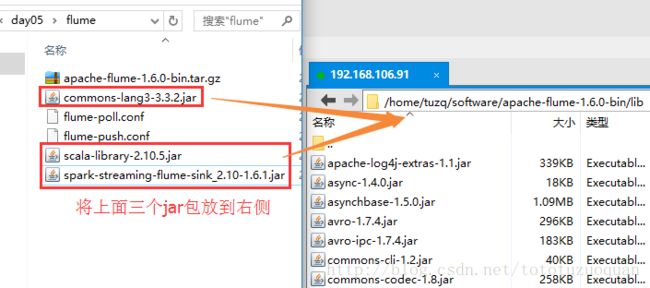
同步到集群中的其它的flume中:
[root@hadoop1 lib]# pwd
/home/tuzq/software/apache-flume-1.6.0-bin/lib
[root@hadoop1 lib]# scp -r * root@hadoop2:$PWD
[root@hadoop1 lib]# scp -r * root@hadoop3:$PWD
[root@hadoop1 lib]# scp -r * root@hadoop4:$PWD
[root@hadoop1 lib]# scp -r * root@hadoop5:$PWD编写flume的配置文件:
[root@hadoop1 agentconf]# pwd
/home/tuzq/software/apache-flume-1.6.0-bin/agentconf
[root@hadoop1 agentconf]# vim flume-poll.conf其中flume-poll.conf的内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/tuzq/software/flumedata
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
#表示从这里拉数据
a1.sinks.k1.hostname = hadoop1
a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume.
[root@hadoop1 apache-flume-1.6.0-bin]# cd /home/tuzq/software/apache-flume-1.6.0-bin
[root@hadoop1 apache-flume-1.6.0-bin]# bin/flume-ng agent -n a1 -c agentconf/ -f agentconf/flume-poll.conf -Dflume.root.logger=WARN,console启动后的效果如下:

这样,一直启动Flume
然后编写从Flume中读取数据的程序。
pom文件的内容如下:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>cn.toto.sparkgroupId>
<artifactId>bigdataartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>1.7maven.compiler.source>
<maven.compiler.target>1.7maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.10.6scala.version>
<spark.version>1.6.2spark.version>
<hadoop.version>2.6.4hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-compilerartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-reflectartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-flume_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka_2.10artifactId>
<version>${spark.version}version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-make:transitivearg>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.18.1version>
<configuration>
<useFile>falseuseFile>
<disableXmlReport>truedisableXmlReport>
<includes>
<include>**/*Test.*include>
<include>**/*Suite.*include>
includes>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.toto.spark.FlumeStreamingWordCountmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>编写代码:
package cn.toto.spark
import java.net.InetSocketAddress
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by toto on 2017/7/13.
*/
object FlumeStreamingWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("FlumeStreamingWordCount").setMaster("local[2]")
//创建StreamingContext并设置产生批次的间隔时间
val ssc = new StreamingContext(conf,Seconds(15))
//从Socket端口中创建RDD,这里的SocketAddress可以传递多个
val flumeStream: ReceiverInputDStream[SparkFlumeEvent] =
FlumeUtils.createPollingStream(ssc, Array(new InetSocketAddress("hadoop1", 8888)),
StorageLevel.MEMORY_AND_DISK)
//去取Flume中的数据
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" "))
val wordAndOne : DStream[(String,Int)] = words.map((_,1))
val result : DStream[(String,Int)] = wordAndOne.reduceByKey(_+_)
//打印
result.print()
//开启程序
ssc.start()
//等待结束
ssc.awaitTermination()
}
}启动程序。然后往Flume监控的flumedata目录下放入文件,如:
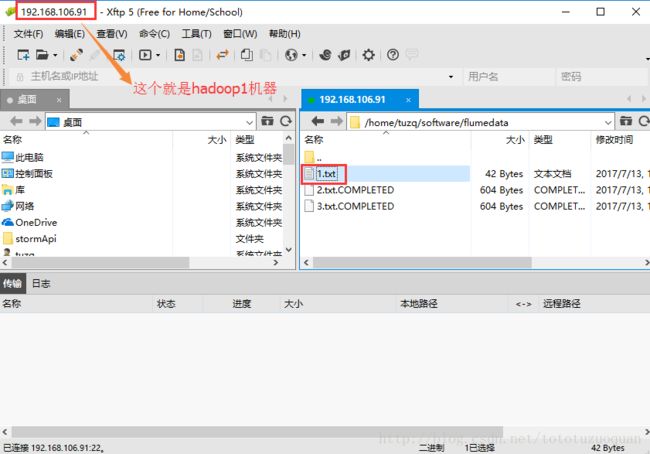
其中1.txt的内容如下:

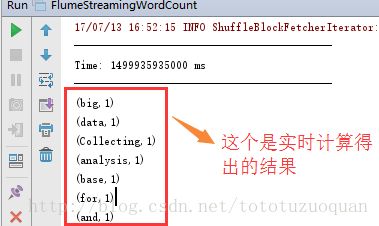
最后在IDEA的控制台中观察结果: