1.数据集成需考虑的问题
a.模式集成和对象匹配
b.冗余。原因一:能够用一个或一组属性导出,原因二:属性或维命名的不一致。
2.属性冗余的相关分析检测
a.数值属性计算相关系数
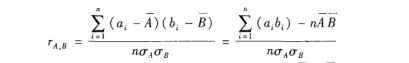
说明:n为元祖个数,ai,bi分别为元祖i中属性A,B的值。-A,-B分别为A和B的均值,然后是A,B的标准差,然后是AB叉积(即,对于每个元祖,属性A乘以B)的和。注意应有:-1<=r<=1,如果r大于0,则A,B是正相关的。意味着A的值随B的值得增加而增加,该值越大,相关性越强。r=0表示不想关。r<0,AB负相关,意味着一个属性阻止另一个属性的出现。
另外:两个属性相关并不意味着一个导致另外一个。
b.分类(离散)数据通过x2,卡方检验。
设A有r个值,B有c个值,则A的r个值与B的c个值构成一个表的列和行。令(Ai,Bi)表示A取值ai,B取值bi的事件。
![]()
其中,Oij是联合事件(Ai,Bj)的观测频度(即实际计数),而eij是(Ai,Bj)的期望频度,可以用下式计算:
![]()
其中,N是数据元祖的个数,count(A=ai)是A具有值ai的元祖个数,count(B=bj)是B具有值bj的元祖个数。
3.元祖级冗余检测重复
不一致通常出现在各种不同的副本之间,在于输入的错误和更新了数据的部分出现,而未更新所有的出现。
4.数据值冲突的检测和处理
不同数据源属性的表示,比例,单位,编码不一致。不同数据源相同名字属性的表示意义可能不同。
5.数据变换涉及的内容(数据准备)
a.光滑:去噪声
b.聚集(不同于聚类):汇总和聚集更多的是对现有的数据进行综合计算得到新的属性值(例如:求年收入)。
c.数据泛化:使用概念分层,用高的概念替换原始数据。例如,国家替换街道,青年替换数值年龄等。
d.属性构造。构建新的属性添加到属性集中,以帮助挖掘过程,类似于聚集,但不仅仅是汇总,而且目的不同。