Hive 分区表
Hive 分区表创建
hive> CREATE TABLE t3(id int,name string,age int) PARTITIONED BY (Year INT, Month INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
OK
Time taken: 0.147 seconds查看表的结构信息
hive> desc t3;
OK
id int
name string
age int
year int
month int
# Partition Information
# col_name data_type comment
year int
month int
Time taken: 0.106 seconds, Fetched: 11 row(s)//添加分区,创建目录
hive> alter table t3 add partition (year=2014, month=12);
OK
Time taken: 0.24 seconds
hive> show partitions t3;
OK
year=2014/month=12
Time taken: 0.183 seconds, Fetched: 1 row(s)往分区表插入数据,可以看到insert 语句会执行MR操作 ,效率非常慢,所有通常会使用load 操作.
hive> insert into t3 partition (year=2014,month=12) (id,name,age) values(1,'ssss',12);
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20180830111614_afbf7e7e-604c-49c7-bd65-dcdf4066de6c
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
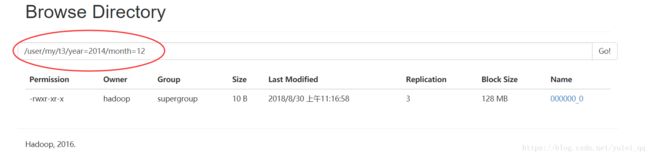
可以使用load 文件将本地文件载入到hive 表中 ,该语句会在hdfs 文件系统中自动创建目录.
hive>load data local inpath '/home/hadoop/student.txt' into table t3 partition(year=2014,month=11);
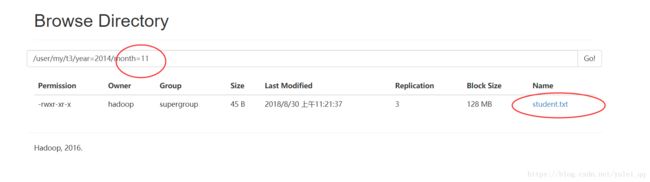
查询分区表内容:
hive> select * from t3 where year=2014 and month=11;
OK
1 tom 12 2014 11
2 hameimei 13 2014 11
3 lilei 14 2014 11
4 mayun 25 2014 11
Time taken: 0.273 seconds, Fetched: 4 row(s)动态分区:
首先创建一个分区表t2
CREATE external TABLE IF NOT EXISTS t2(id int,name string,age int)
COMMENT 'xx'
PARTITIONED BY (year int, month int )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE ; 然后使用如下SQL实现动态分区.
INSERT OVERWRITE TABLE t2
PARTITION (year,month)
SELECT m.id,m.name,m.age,m.year,m.month
FROM t3 m;
hive> INSERT OVERWRITE TABLE t2
> PARTITION (year,month)
> SELECT m.id,m.name,m.age,m.year,m.month
> FROM t3 m;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20180830150223_1979cd0a-8433-4820-b01b-39821fec9a15
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1535543680929_0008, Tracking URL = http://s201:8088/proxy/application_1535543680929_0008/
Kill Command = /soft/hadoop/b个人理解的动态分区是指不用在给表插入数据时,把分区值给写死。比如如下这样的
INSERT OVERWRITE TABLE t2
PARTITION (year=2012,month=11)
SELECT m.id,m.name,m.age
FROM t3 m where year=2012 and month=11;