图解:什么是B树(心中有 B树,做人要谦虚)?

B-树是一种平衡的多路查找树,注意:B树就是B-树,"-"是个连字符号,不是减号 。在大多数的平衡查找树(Self-balancing search trees),比如 AVL 树 和红黑树,都假设所有的数据放在主存当中。那为什么要使用 B-树呢(或者说为啥要有 B-树呢)?要解释清楚这一点,我们假设我们的数据量达到了亿级别,主存当中根本存储不下,我们只能以块的形式从磁盘读取数据,与主存的访问时间相比,磁盘的 I/O 操作相当耗时,而提出 B-树的主要目的就是减少磁盘的 I/O 操作。大多数平衡树的操作(查找、插入、删除,最大值、最小值等等)需要 次磁盘访问操作,其中 是树的高度。但是对于 B-树而言,树的高度将不再是 (其中 是树中的结点个数),而是一个我们可控的高度 (通过调整 B-树中结点所包含的键【你也可以叫做数据库中的索引,本质上就是在磁盘上的一个位置信息】的数目,使得 B-树的高度保持一个较小的值)。一般而言,B-树的结点所包含的键的数目和磁盘块大小一样,从数个到数千个不等。由于B-树的高度 h 可控(一般远小于 ),所以与 AVL 树和红黑树相比,B-树的磁盘访问时间将极大地降低。
我们之前谈过红黑树与AVL树相比较,红黑树更好一些,这里我们将红黑树与B-树进行比较,并以一个例子对第一段的内容进行解释。
假设我们现在有 838,8608 条记录,对于红黑树而言,树的高度 ,也就是说如果要查找到叶子结点需要 23 次磁盘 I/O 操作;但是 B-树,情况就不同了,假设每一个结点可以包含 8 个键(当然真实情况下没有这么平均,有的结点包含的键可能比8多一些,有些比 8 少一些),那么整颗树的高度将最多 8 ( ) 层,也就意味着磁盘查找一个叶子结点上的键的磁盘访问时间只有 8 次,这就是 B-树提出来的原因所在。
B 树的特性
所有的叶子结点都出现在同一层上,并且不带信息(可以看做是外部结点或查找失败的结点,实际上这些结点不存在,指向这些结点的指针为空)。
每个结点包含的关键字个数有上界和下界。用一个被称为 B-树的 最小度数 的固定整数 来表示这些界 ,其中 取决于磁盘块的大小:
a.除根结点以外的每个结点必须至少有 个关键字。因此,除了根结点以外的每个内部结点有 t 个孩子。如果树非空,根结点至少有一个关键字。
b. 每个结点至多包含 个关键字。
一个包含 个关键字的结点有 个孩子;
一个结点中的所有关键字升序排列,两个关键字 和 之间的孩子结点的所有关键字 key 在 的范围之内。
与二叉排序树不同, B-树的搜索是从根结点开始,根据结点的孩子树做多路分支选择,而二叉排序树做的是二路分支选择,每一次判断都会进行一次磁盘 I/O操作。
与其他平很二叉树类似,B-树查找、插入和删除操作的时间复杂度为 量级。
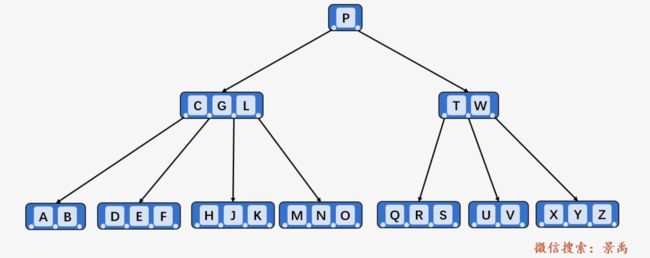
上图就是一颗典型的 B-树,其中最小度数 ,根结点至少包含一个关键字 P ,根结点以外的每个结点至少有 t - 1 = 1 个,每个结点最多包含 2t - 1= 3 个关键字;包含三个 1 关键字 P 的根结点有 1 + 1 = 2 个孩子结点,包含 3 个关键字的结点 (C、G、L) 包含有 4 个孩子。同一个结点中的所有关键字升序排列,比如结点 (D、E、F) 的内部结点就是升序排列,且均位于其父结点中的关键字 C 和 G 之间。所有的叶结点均为空。
B-树的查找
B-树的查找操作与二叉排序树(BST)极为类似,只不多 B-树中的每个结点包含多个关键字。假设待查找的关键字为 k ,我们从根结点开始,递归向下进行查找。对每一个访问的非叶子结点,如果结点包含待查找的关键字 k ,则返回结点指针;否则,我们递归到该结点的恰当子代(该子代结点中的关键字均在比 k 更大的关键字之前)。如果抵达了叶子结点且没有找到 k 则返回 null .
B-树查找操作演示
我们以查找关键字 F 为例进行说明。
第一步:访问根结点 P ,发现关键字 F 小于 P ,则查找结点 P 的左孩子。
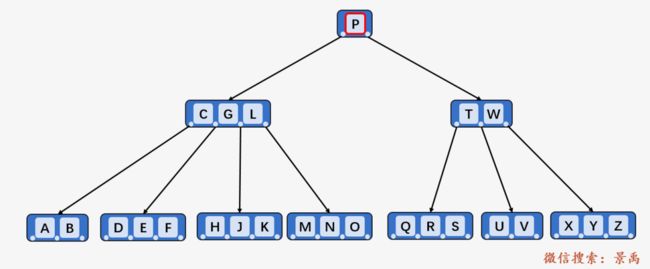
第二步:访问结点 P 的左子结点 [C、G、L] ,对于一个结点中包含多个关键字时,顺序进行访问,首先与关键字 C 进行比较,发现比 C 大;然后与关键字 G 进行比较,发现比 G 小,则说明待查找关键字 F 位于关键字 C 和关键字 G 之间的子代中。
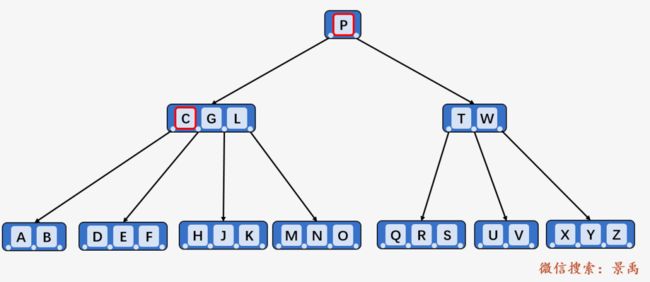
第三步:访问关键字 C 和关键字 G 之间的子代,该子代结点包含三个关键字 [D、E、F] ,进行顺序遍历,比较关键字 D 和 F ,F 比 D 大
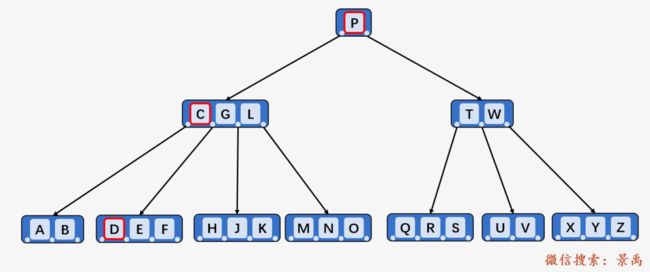
顺序访问关键字 E ,F 比 E 大:
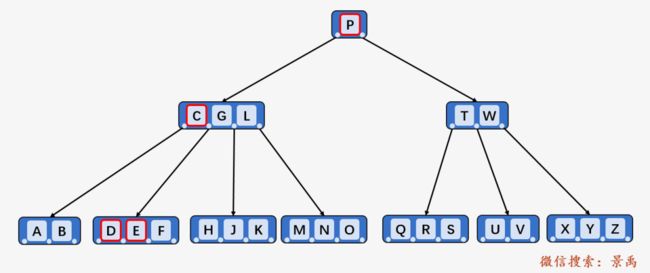
顺序访问关键字 F ,发现与待查找关键字相同,查找成功。则返回结点 [D、E、F] 的指针。
在此处我们顺带一起看一下 B-树中结点的一个定义:
int *keys; // 存储关键字的数组
int t; // 最小度 (定义一个结点包含关键字的个数 t-1 <= num <= 2t -1)
BTreeNode **C; // 存储孩子结点指针的数组
int n; // 记录当前结点包含的关键字的个数
bool leaf; // 叶子结点的一个标记,如果是叶子结点则为true,否则false
这是一个结点所最关键的几个属性,我们对 B-树中结点的完整定义为:
class BTreeNode
{
int *keys; // 存储关键字的数组
int t; // 最小度 (定义一个结点包含关键字的个数 t-1 <= num <= 2t -1)
BTreeNode **C; // 存储孩子结点指针的数组
int n; // 记录当前结点包含的关键字的个数
bool leaf; // 叶子结点的一个标记,如果是叶子结点则为true,否则false
public:
BTreeNode(int _t, bool _leaf);
//
void traverse();
// 查找一个关键字
BTreeNode *search(int k); // 如果没有出现,则返回 NULL
// 设置友元,以便访问BTreeNode类中的私有成员
friend class BTree;
};
// B-树
class BTree
{
BTreeNode *root; //指向B-树根节点的指针
int t; // 最小度
public:
// 构造器(初始化一棵树为空树)
BTree(int _t)
{ root = NULL; t = _t; }
// 进行中序遍历
void traverse()
{ if (root != NULL) root->traverse(); }
// B-树中查找一个关键字 k
BTreeNode* search(int k)
{ return (root == NULL)? NULL : root->search(k); }
};
这里面可能涉及一些 C++ 的基础,不过你学算法,不必在意,只需要关注一个 B-树结点最重要的几个属性定义。
B-树的查找操作的实现
// B-树查找操作的实现
BTreeNode *BTreeNode::search(int k)
{
// 找到第一个大于等于待查找关键字 k 的关键字
int i = 0;
while (i < n && k > keys[i])
i++;
// 如果找到的第一个关键字等于 k , 返回结点指针
if (keys[i] == k)
return this;
// 如果没有找到关键 k 且当前结点为叶子结点则返回NULL
if (leaf == true)
return NULL;
// 递归访问恰当的子代
return C[i]->search(k);
}
B-树的中序遍历
B-树的中序遍历与二叉树的中序遍历也很相似,我们从最左边的孩子结点开始,递归地打印最左边的孩子结点,然后对剩余的孩子和关键字重复相同的过程。最后,递归打印最右边的孩子.
对于这个图的中序遍历结果为:

**一定要注意,本应该是26个字母,但是这里缺少了字母 I ** ,之后我们看插入操作时可以将其插入。
中序遍历实现代码
void BTreeNode::traverse()
{
// 有 n 个关键字和 n+1 个孩子
// 遍历 n 个关键字和前 n 个孩子
int i;
for (i = 0; i < n; i++)
{
// 如果当前结点不是叶子结点, 在打印 key[i] 之前,
// 先遍历以 C[i] 为根的子树.
if (leaf == false)
C[i]->traverse();
cout << " " << keys[i];
}
// 打印以最后一个孩子为根的子树
if (leaf == false)
C[i]->traverse();
}
B-树的插入操作
一个新插入的关键字 k 总是被插入到叶子结点。与二叉排序树的插入操作类似,我们从根结点开始,向下遍历直到叶子结点,到达叶子结点,将关键字 k 插入到相应的叶子结点。与 BST 不同的是,我们通过最小度定义了一个结点可以包含关键字的个数的一个取值范围,所以在插入一个关键字时,就需要确认插入关键字之后结点是否超出结点本身最大可容纳的关键字个数。
如果判断在插入一个关键字 k 之前,一个结点是否有可供当前结点插入的空间呢?
我们可以使用一个称为 splitChild() 的操作实现,即拆分一个结点的孩子。下图中, x 的孩子结点 y 被拆分成了两个结点 y 和 z 。拆分操作将一个关键 上移,并以上移的关键 对结点 y 进行拆分,拆分成包含关键字 [G、H] 的结点 y 和包含关键字 [J、K] 的结点 z . 这一过程又称之为 B-树的生长,区别于 BST 的向下生长。
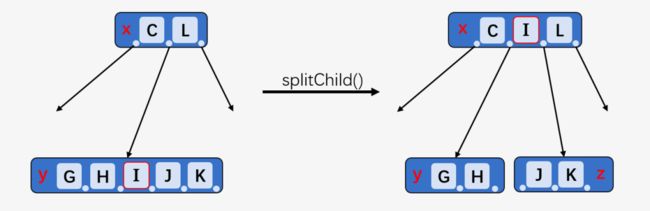
综上,B-树在插入一个新的关键字 k 时,我们从根结点一直访问到叶子结点,在遍历一个结点之前,首先检查这个结点是否已经满了,即包含了 2t - 1 个关键字,如果结点已满,则将其拆分并创建新的空间。插入操作的伪代码描述如下:
插入操作伪码
初始化
x作为根结点当
x不是叶子结点,执行如下操作:
找到
x的下一个要被访问的孩子结点y如果
y没有满,则将结点y作为新的x如果
y已经满了,拆分y,结点x的指针指向结点y的两部分。如果k比y中间的关键字小, 则将y的第一部分作为新的x,否则将y的第二部分作为新的x,当将y拆分后,将y中的一个关键字移动到它的父结点x当中。
当 x 是叶子结点时,第二步结束;由于我们已经提前查分了所有结点,x 必定至少有一个额外的关键字空间,进行简单的插入即可。
事实上 B-树的插入操作是一种主动插入算法,因为在插入新的关键字之前,我们会将所有已满的结点进行拆分,提前拆分的好处就是,我们不必进行回溯,遍历结点两次。如果我们不事先拆分一个已满的结点,而仅仅在插入新的关键字时才拆分它,那么最终可能需要再次从根结点出发遍历所有结点,比如在我们到达叶子结点时,将叶结点进行拆分,并将其中的一个关键字上移导致父结点分裂(因为上移导致父结点超出可存储的关键字的个数),父结点的分裂后,新的关键字继续上移,将可能导致新的父结点分裂,从而出现大量的回溯操作。但是 B-树这种主动插入算法中,就不会发生级联效应。当然,这种主动插入的缺点也很明显,我们可能进行很多不必要的拆分操作。
插入操作案例
我们以在上图中插入关键字 I 为例进行说明。其中最小度 t = 2 ,一个结点最多可存储 2t - 1 = 3 个结点。
第一步:访问根结点,发现插入关键字 I 小于 P , 但根结点未满,不分裂,直接访问其第一个孩子结点。
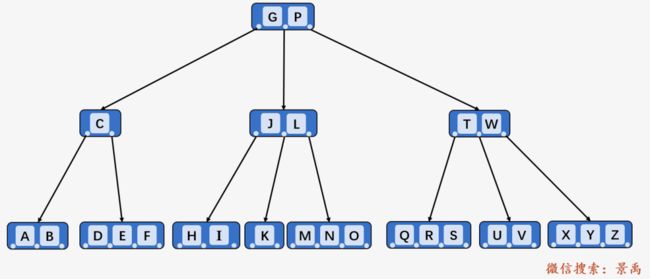
第二步:访问结点 P 的第一个孩子结点 [C、G、L] ,发现第一个孩子结点已满,将第一个孩子结点分裂为两个:
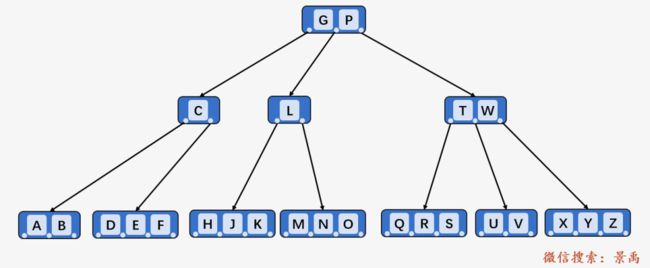
第三步:将结点 I 插入到结点 L 的第一个左孩子当中,发现 L 的第一个左孩子 [H、J、K] 已满,则将其分裂为两个。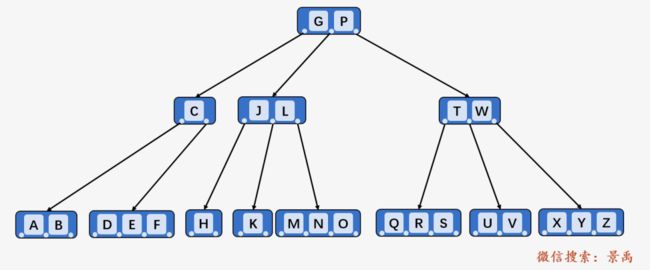
第四步:将结点 I 插入到结点 J 的第一个孩子当中,发现 L 的第一个孩子结点 [H] 未满且为叶子结点,则将 I 直接插入。
插入操作代码实现:
关于 B-树插入操作的实现稍微复杂一些,里面涉及到每一个结点内部指针的移动,同时涉及到父结点中相应指针的移动,不过对照着图和代码中的注释,我相信你可以看懂。
// B-树中插入一个新的结点 k 主函数
void BTree::insert(int k)
{
// 如果树为空树
if (root == NULL)
{
// 为根结点分配空间
root = new BTreeNode(t, true);
root->keys[0] = k; //插入结点 k
root->n = 1; // 更新根结点高寒的关键字的个数为 1
}
else
{
// 当根结点已满,则对B-树进行生长操作
if (root->n == 2*t-1)
{
// 为新的根结点分配空间
BTreeNode *s = new BTreeNode(t, false);
// 将旧的根结点作为新的根结点的孩子
s->C[0] = root;
// 将旧的根结点分裂为两个,并将一个关键字上移到新的根结点
s->splitChild(0, root);
// 新的根结点有两个孩子结点
//确定哪一个孩子将拥有新插入的关键字
int i = 0;
if (s->keys[0] < k)
i++;
s->C[i]->insertNonFull(k);
// 新的根结点更新为 s
root = s;
}
else //根结点未满,调用insertNonFull()函数进行插入
root->insertNonFull(k);
}
}
// 将关键字 k 插入到一个未满的结点中
void BTreeNode::insertNonFull(int k)
{
// 初始化 i 为结点中的最后一个关键字的位置
int i = n-1;
// 如果当前结点是叶子结点
if (leaf == true)
{
// 下面的循环做两件事:
// a) 找到新插入的关键字位置并插入
// b) 移动所有大于关键字 k 的向后移动一个位置
while (i >= 0 && keys[i] > k)
{
keys[i+1] = keys[i];
i--;
}
// 插入新的关键字,结点包含的关键字个数加 1
keys[i+1] = k;
n = n+1;
}
else
{
//找到第一个大于关键字 k 的关键字 keys[i] 的孩子结点
while (i >= 0 && keys[i] > k)
i--;
// 检查孩子结点是否已满
if (C[i+1]->n == 2*t-1)
{
// 如果已满,则进行分裂操作
splitChild(i+1, C[i+1]);
// 分裂后,C[i] 中间的关键字上移到父结点,
// C[i] 分裂称为两个孩子结点
// 找到新插入关键字应该插入的结点位置
if (keys[i+1] < k)
i++;
}
C[i+1]->insertNonFull(k);
}
}
// 结点 y 已满,则分裂结点 y
void BTreeNode::splitChild(int i, BTreeNode *y)
{
// 创建一个新的结点存储 t - 1 个关键字
BTreeNode *z = new BTreeNode(y->t, y->leaf);
z->n = t - 1;
//将结点 y 的后 t -1 个关键字拷贝到 z 中
for (int j = 0; j < t-1; j++)
z->keys[j] = y->keys[j+t];
// 如果 y 不是叶子结点,拷贝 y 的后 t 个孩子结点到 z中
if (y->leaf == false)
{
for (int j = 0; j < t; j++)
z->C[j] = y->C[j+t];
}
//将 y 所包含的关键字的个数设置为 t -1
//因为已满则为2t -1 ,结点 z 中包含 t - 1 个
//一个关键字需要上移
//所以 y 中包含的关键字变为 2t-1 - (t-1) -1
y->n = t - 1;
// 给当前结点的指针分配新的空间,
//因为有新的关键字加入,父结点将多一个孩子。
for (int j = n; j >= i+1; j--)
C[j+1] = C[j];
// 当前结点的下一个孩子设置为z
C[i+1] = z;
//将所有父结点中比上移的关键字大的关键字后移
//找到上移结点的关键字的位置
for (int j = n-1; j >= i; j--)
keys[j+1] = keys[j];
// 拷贝 y 的中间关键字到其父结点中
keys[i] = y->keys[t-1];
//当前结点包含的关键字个数加 1
n = n + 1;
}
B-树的删除操作
B-树的删除操作相比于插入操作更为复杂,如果仅仅只是删除叶子结点中的关键字,也非常简单,但是如果删除的是内部节点的,就不得不对结点的孩子进行重新排列。
与 B-树的插入操作类似,我们必须确保删除操作不违背 B-树的特性。正如插入操作中每一个结点所包含的关键字的个数不能超过 2t -1 一样,删除操作要保证每一个结点包含的关键字的个数不少于 t -1 个(除根结点允许包含比 t -1 少的关键字的个数。
接下来一一横扫删除操作中可能出现的所有情况。
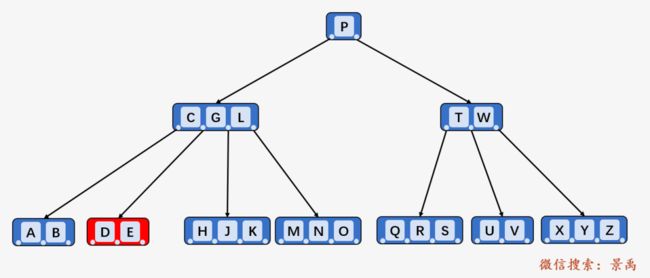
初始的 B-树 如图所示,其中最小度 t = 3 每一个结点最多可包含 5 个关键字,至少包含 2个关键字(根结点除外)。
1. 待删除的关键字 k 在结点 x 中,且 x 是叶子结点,删除关键字k
删除 B-树中的关键字 F
2. 待删除的关键字 k 在结点 x 中,且 x 是内部结点,分一下三种情况
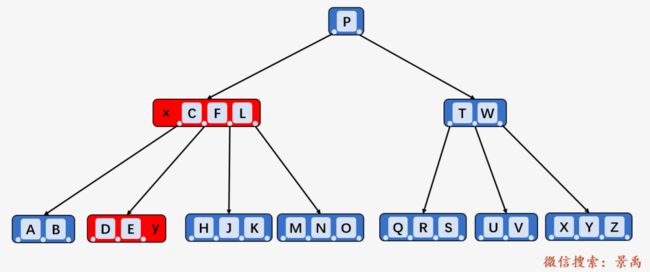
情况一:如果位于结点 x 中的关键字 k 之前的第一个孩子结点 y 至少有 t 个关键字,则在孩子结点 y 中找到 k 的前驱结点 ,递归地删除关键字 ,并将结点 x 中的关键字 k 替换为 .
删除 B-树中的关键字 G ,G 的前一个孩子结点 y 为 [D、E、F] ,包含 3个关键字,满足情况一,关键字 G 的直接前驱为关键 F ,删除 F ,然后将 G 替换为 F .
情况二:y 所包含的关键字少于 t 个关键字,则检查结点 x 中关键字 k 的后一个孩子结点 z 包含的关键字的个数,如果 z 包含的关键字的个数至少为 t 个,则在 z 中找到关键字 k 的直接后继 ,然后删除 ,并将关键 k 替换为 .
删除 B-树中的关键字 C , y 中包含的关键字的个数为 2 个,小于 t = 3 ,结点 [C、G、L] 中的 关键字 C 的后一个孩子 z 为 [D、E、F] 包含 3 个关键字,关键字 C 的直接后继为 D ,删除 D ,然后将 C 替换为 D .
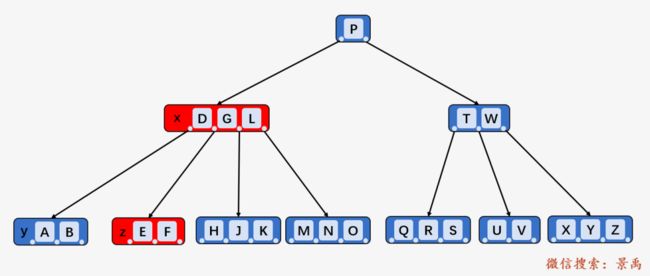
情况三:如果 y 和 z 都只包含 t -1 个关键字,合并关键字 k 和所有 z 中的关键字到 结点 y 中,结点 x 将失去关键字 k 和孩子结点 z,y 此时包含 2t -1 个关键字,释放结点 z 的空间并递归地从结点 y 中删除关键字 k.
为了说明这种情况,我们将用下图进行说明。
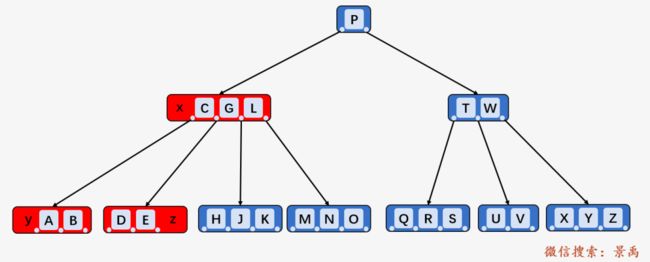
删除关键字 C , 结点 y 包含 2 个关键字 ,结点 z 包含 2 个关键字,均等于 t - 1 = 2 个, 合并关键字 C 和结点 z 中的所有关键字到结点 y 当中:
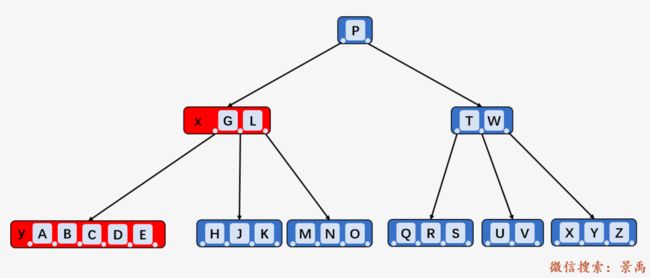
此时结点 y 为叶子结点,直接删除关键字 C
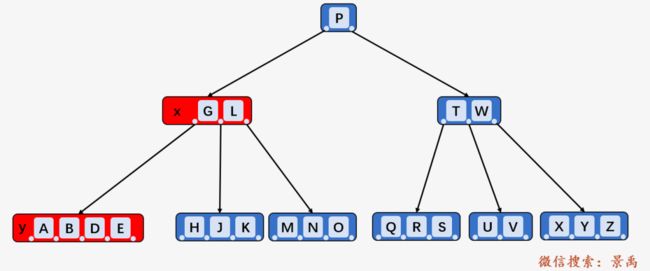
3. 如果关键字 k 不在当前在内部结点 x 中,则确定必包含 k 的子树的根结点 x.c(i) (如果 k 确实在 B-树中)。如果 x.c(i) 只有 t - 1 个关键字,必须执行下面两种情况进行处理:(看到这里一头雾水)
首先我们得确认什么是当前内部结点 x ,什么是 x.c(i) ,如下图所示, P 现在不是根结点,而是完整 B-树的一个子树的根结点:
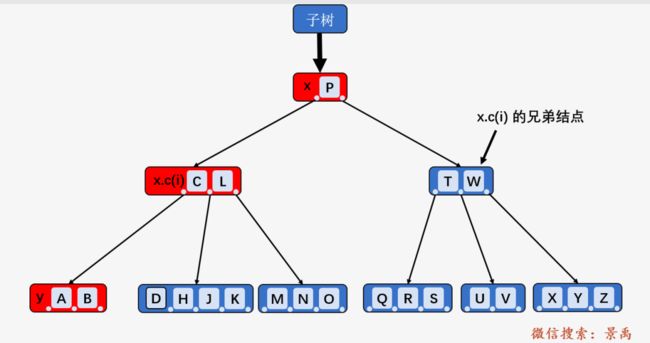
情况二:如果 x.c(i) 及 x.c(i) 的所有相邻兄弟都只包含 t - 1 个关键字,则将 x.c(i) 与 一个兄弟合并,即将 x 的一个关键字移动至新合并的结点,使之成为该结点的中间关键字,将合并后的结点作为新的 x 结点 .(依旧一头雾水)
不要惊奇,为什么情况二放前面,而情况一放后面,原因是这样有助于你的理解。
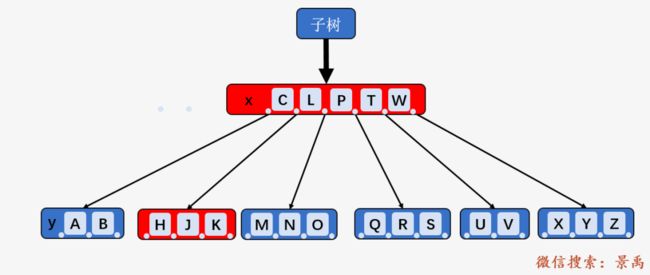
情况二上面的图标明了相应的 x 及 x.c(i) ,我们以删除关键字 D 为例,此时当前内部结点 x 不包含关键字 D , 确定是第三种情况,我们可以确认关键 D 一定在结点 x 的第一个孩子结点所在的子树中,结点 x 的第一个孩子结点所在子树的跟结点为 x.c(i) 即 [G、L] . 其中 结点 [G、L] 及其相邻的兄弟结点 [T、W] 都只包含 2 个结点(即 t - 1) ,则将 [G、L] 与 [T、W] 合并,并将结点 x 当中仅有的关键字 P 合并到新结点中;然后将合并后的结点作为新的 x 结点,递归删除关键字 D ,发现D 此时在叶子结点 y 中,直接删除,就是 1. 的情况。(此时清晰了很多)
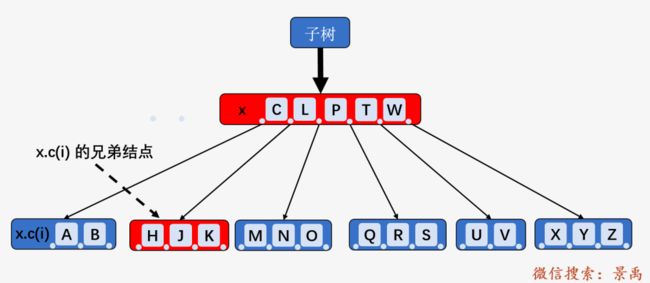
情况一:x.c(i) 仅包含 t - 1 个关键字且 x.c(i) 的一个兄弟结点包含至少 t 个关键字,则将 x 的某一个关键字下移到 x.c(i) 中,将 x.c(i) 的相邻的左兄弟或右兄弟结点中的一个关键字上移到 x 当中,将该兄弟结点中相应的孩子指针移到 x.c(i) 中,使得 x.c(i) 增加一个额外的关键字。(一头雾水)
为了去掉 “一头雾水“,我们在上面情况二删除后的结果上继续进行说明:
 )
)
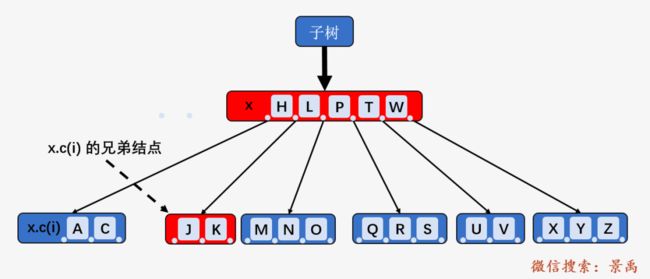
我们以删除结点 [A、B] 中的结点 B 为例,上图中 x.c(i) 包含 2 个关键字,即 t - 1 个关键字, x.c(i) 的一个兄弟结点 [H、J、K] 包含 3 个关键字(满足至少 t 个关键字的要求),则将兄弟结点 [H、J、K] 中的关键字 H 向上移动到 x 中, 将 x 中的关键字 C 下移到 x.c(i) 中;删除关键字 B .
到这里,B-树的所有主要操作就结束了,关于 B-树查找、遍历、插入和删除的完整工程代码我就再不放在文中了,需要的朋友后台回复 「 B-tree」就可以获得。
二叉树与B-树的比较
B-树是一颗中序遍历结果有序的多路平衡树。不同于二叉树,B-树中的结点可以有多个孩子结点,二叉树只能有两个孩子结点。B-树的高度为 (其中 M 是B-树的阶,也就是一个结点可以最多包含关键字的个数,N 为结点个数)。每一次更新高度自动调整。B-树中的结点内的关键字按照从左到右升序排列。B-树中插入一个结点或者关键字相比于二叉树也更加复杂。
二叉树是一颗典型的普通树。与 B-树不同,二叉树中的结点最多可以有两个孩子结点。二叉树最顶端的根结点仅包含一个左子树和右子树。与 B-树相同,中序遍历结果有序,但是二叉树的前序遍历结果和后序遍历结果同样可以有序,二叉树中结点的插入和删除操作简单。
| N | B-Tree | Binary Tree |
|---|---|---|
| 1 | B-树中,一个结点最多可以包含 M 个孩子结点 |
二叉树中,一个结点最多包含 2 个孩子结点 |
| 2 | B-树是一颗中序遍历结果有序的有序树 | 二叉树不是排序树,可以按照前、中、后序遍历进行排序 |
| 3 | B-树的高度为 | 二叉树的高度为 |
| 4 | B-树从磁盘中加载数据 | 二叉树从RAM中加载数据 |
| 5 | B-树应用于DBMS(代码索引等) | 二叉树用在赫夫曼编码,代码优化等 |
| 6 | B-树中插入一个结点或关键字更复杂 | 二叉树插入树简单 |
祝你学习愉快,文章可能稍微长了点儿,多点儿耐心好好看看!加油呀!!!下次我们一起看看B+
推荐阅读:
图解:什么是红黑树?(上篇)
图解:什么是红黑树?(中篇)
作者:景禹,一个追求极致的共享主义者,想带你一起拥有更美好的生活,化作你的一把伞。

