左右互搏:生成型对抗性网络的强大威力
生成型对抗性网络,简称GEN,在2014年时被发明。它与上一节介绍的VAE也就是编解码网络一样,擅长于图像构造,然而它的功能比VAE要强大不少,我们现在时常听到AI合成网络主播,类似功能的实现绝大多数都基于我们这次要探讨的对抗性网络。
生成型对抗性网络一个非常显著的特点是左右互搏。它由两个子网络构成,一个子网络叫generator,它负责构造图片或相应数据,另一个网络叫discriminator,负责判断前者构造数据的质量。如果前者构造的图像不够好,那么后者就传达一个负反馈给前者,于是前者根据反馈调整自身参数,让下一次生成的图片质量得以提升,它就是靠这种体内自循环的方式不断提升自己构造图片的能力。
举个例子,假设有个画家想伪造毕加索的名画,他一开始并不知道如何模仿毕加索的笔法,于是他按照自己的直觉对着毕加索一幅画进行临摹,然后把绘制结果交给一个与他串通好的绘画交易商,后者对毕加索的画颇有研究,看了临摹后给画家反馈说颜色用的太浅了。画家拿到反馈后再次临摹,这次他加深了颜色的深度,于是第二次临摹的质量比第一次好了一些。交易商看了后再次给他反馈说线条太粗了,于是画家根据反馈再次改进,这种循环不断进行,每一次循环画家模仿的记忆就变得更好,直到足够次数的改进后,画家模仿出的画与毕加索的真迹再也无法区分出来。
在这里画家就是generator,而交易商就是discriminator。在网络运行商,generator接收一个随机向量,然后输出对应一副图画的二维数组。discriminator接收二维数组,然后判断这二维数组是来自训练数据还是来自generator,如果generator生成的二维数组使得discriminator无法区分是来自训练数据还是generator生成的,整个流程结束,此时generator产生的图像与来自训练数据的图像已经相像得无法分辨了,对抗性生成型网络的运行流程如下:
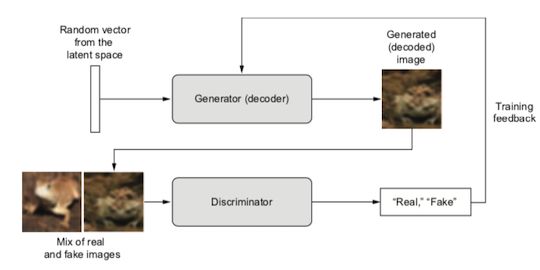
discriminator网络会输入大量训练数据进行训练,让它掌握训练数据图像特征。generator网络接收一个随机向量,然后生成一张图片给discriminator判断,如果后者判断输入图片是伪造的,它会给generator一个负反馈,然后generator根据反馈修正自身参数从而改进生成的图片质量,这个流程反复进行直到generator生成的图片被discriminator接受为止,此时generator生成的图片质量与训练discriminator所用的图片质量几乎一模一样。
我们看一个GEN用于生成图片的实例:

上图中左边是真实人物图像,右边是GAN网络生成的图像,你是否感觉到网络的构造能力非常惊人。GAN网络与其他网络不通之处在于,它训练过程非常困难,因为它是两个子网络互相联动,因此网络训练时,如果调整不好,整个网络状态会一直剧烈波动无法达到平衡态。
我们接下来将尝试开发一个形态最简单的GAN网络叫DCGAN,其中子网络generator由多个卷积层组成,而discrimator由多个反卷积层组成。我们选取数据集CIFAR10对网络进行训练,它包含50000张格式为32*32的RGB图片,我们从中间抽取出所有青蛙图片训练网络,让网络学会如何无中生有的构造出以假乱真的青蛙图片。
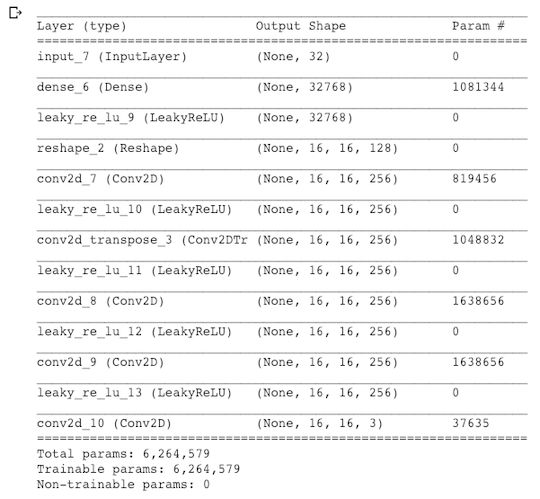
首先我们看看generator网络的实现:
import keras
from keras import layers
import numpy as np
#输入generator网络的随机向量长度
latent_dim = 32
#generator输出格式为[32, 32 , 3]的数组,它对应一张图片
height = 32
width = 32
channels = 3
generator_input = keras.Input(shape = (latent_dim, ))
x = layers.Dense(128 * 16 * 16)(generator_input)
x = layers.LeakyReLU()(x)
x = layers.Reshape((16, 16, 128))(x)
x = layers.Conv2D(256, 5, padding= 'same')(x)
#我们使用激活函数LeakyReLu而不是以前的Relu,前者有利于网络训练时趋于稳定
x = layers.LeakyReLU()(x)
#卷积网络层
x = layers.Conv2DTranspose(256, 4, strides = 2, padding = 'same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(256, 5, padding = 'same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(256, 5, padding = 'same')(x)
x = layers.LeakyReLU()(x)
#使用激活函数tanh而不是sigmoid,因为它有利于网络在训练时趋于稳定
x = layers.Conv2D(channels, 7, activation = 'tanh', padding = 'same')(x)
generator = keras.models.Model(generator_input, x)
generator.summary()
上面代码运行后结果如下:
接下来我们看看discriminator网络的实现:
#generator的输出就是discriminator的输入
discriminator_input = layers.Input(shape=(height, width, channels))
x = layers.Conv2D(128, 3)(discriminator_input)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128, 4, strides = 2)(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128, 4, strides = 2)(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128, 4, strides = 2)(x)
x = layers.LeakyReLU()(x)
x = layers.Flatten()(x)
#增加Dropout有利于网络训练时趋于稳定
x = layers.Dropout(0.4)(x)
x = layers.Dense(1, activation = 'sigmoid')(x)
discriminator = keras.models.Model(discriminator_input, x)
discriminator.summary()
discriminator_optimizer = keras.optimizers.RMSprop(lr = 0.0008,
#因为网络训练时状态变化很剧烈,因此我们限定参数变化范围减少状态摇摆
clipvalue = 1.0,
#学习率也要不断变化以适应网络状态的改变
decay = 1e-8
)
#discriminator判断generator构造的图片是否为真
discriminator.compile(optimizer = discriminator_optimizer,
loss = 'binary_crossentropy')
上面构造了discriminator网络,然后我们需要把两个网络连接成一个整体。网络训练的目的就是不断改进generator,让它生成的图片能骗过discriminator。两者连接成整体的代码如下:
'''
我们把generator和discriminator连成一个整体,在对整体进行训练时,
只更改generator网络的参数,discriminator的参数保持不变
'''
discriminator.trainable = False
gan_input = keras.Input(shape = (latent_dim, ))
#将两个网络衔接在一起
gan_output = discriminator(generator(gan_input))
gan = keras.models.Model(gan_input, gan_output)
gan_optimizer = keras.optimizers.RMSprop(lr = 0.0004, clipvalue = 1.0,
decay = 1e-8)
gan.compile(optimizer = gan_optimizer, loss = 'binary_crossentropy')
接着我们准备启动训练流程。训练流程分几步走,首先随机生成一个含有32个元素的一维向量,使用该向量输入generator网络,让它生成[32, 32 3]的二维数组;将生成的二维数组与来自训练图片对应的二维数组混合在一起;把混合的数据用于训练discriminator网络,其中来自训练数据的图片数组对应标签为True,来自generator产生的二维数组对应的标签为False;再次产生一个含有32个元素的一维向量,让generator产生对应的二维数组;让discriminator网络判断该二维数组是否为来自训练数据的图片,generator根据反馈修正参数改进二维数组的生成质量,这个过程一直持续到discriminator返回True为止。
我们看看相应代码:
import os
from keras.preprocessing import image
(x_train, y_train), (_, _) = keras.datasets.cifar10.load_data()
#选出所有青蛙图片
x_train = x_train[y_train.flatten() == 6]
x_train = x_train.reshape((x_train.shape[0], ) +
(height, width, channels)).astype('float32') / 255.
iterations = 10000
batch_size = 20
save_dir = '/content/gdrive/My Drive/gen_imgs'
start = 0
for step in range(iterations):
random_latent_vectors = np.random.normal(size = (batch_size, latent_dim))
#让generator产生对应图片的二维数组
generated_images = generator.predict(random_latent_vectors)
stop = start + batch_size
real_images = x_train[start : stop]
combined_images = np.concatenate([generated_images, real_images])
labels = np.concatenate([np.ones((batch_size, 1)), np.zeros((batch_size, 1))])
#这是一个让网络训练趋于稳定的小技巧,就是将给标签添加随机化噪音
labels += 0.05 * np.random.random(labels.shape)
#先训练discriminator识别真假图片
d_loss = discriminator.train_on_batch(combined_images, labels)
random_latent_vectors = np.random.normal(size = (batch_size, latent_dim))
misleading_targets = np.zeros((batch_size, 1))
#根据discriminator的反馈让generator改进自身参数
a_loss = gan.train_on_batch(random_latent_vectors, misleading_targets)
start += batch_size
if start > len(x_train) - batch_size:
start = 0
if step % 100 == 0:
gan.save_weights('gan.h5')
print('discriminator loss: ', d_loss)
print('adversarial loss: ', a_loss)
img = image.array_to_img(generated_images[0] * 255. , scale = False)
img.save(os.path.join(save_dir, 'generated_frog' + str(step) + '.png'))
img = image.array_to_img(real_images[0] * 255., scale = False)
img.save(os.path.join(save_dir, 'real_frog' + str(step) + '.png'))
在没有GPU加持的情况下,上面代码的训练会较为缓慢,当网络训练成果后,我们看看网络构造的图片和来自训练数据集的图片有何区别:
![]()
![]()
由于我们生成的图片很小不好观察,但把两只图片放在一起对比一下,上面图片是网络生成的青蛙图片,下边图片是来自训练数据集的图片,我们不难体会到,网络生成的图片跟来自训练数据集的图片几乎看不出区别来。
最近看到一则新闻说,搜狗与央视合作,使用人工智能合成新闻主播名叫小萌,她的原型来自于央视的一名主持人,这名AI合成主持人已经做到人眼看不出她是虚拟的,不论是举手投足还是细微表情的展现上,都与真人无异,我想搜狗所用的技术,应该就是我们今天谈到的生成型对抗性网络。
生成型对抗性网络是我们接触的所有类型网络中最为复杂的一种。它在训练过程中,只要参数稍微不对,整个网络就不能收敛,GAN网络的训练和开发几乎没有什么原理来指导,出现异常情况时,要靠开发者自身的经验和直觉去处理或调整,这里只能作为抛砖引玉之用,有兴趣的读者可以自行加大探索的力度。
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:

更多内容,请点击进入csdn学院