KMP算法-Python版
KMP算法-Python版
传统法:
从左到右一个个匹配,如果这个过程中有某个字符不匹配,就跳回去,将模式串向右移动一位。这有什么难的?
我们可以这样初始化:

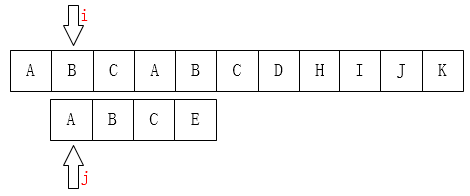
之后我们只需要比较i指针指向的字符和j指针指向的字符是否一致。如果一致就都向后移动,如果不一致,如下图:

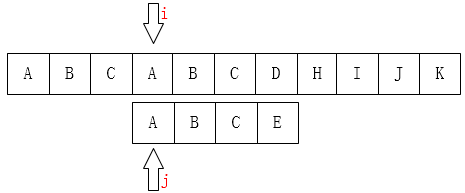
A和E不相等,那就把i指针移回第1位(假设下标从0开始),j移动到模式串的第0位,然后又重新开始这个步骤:
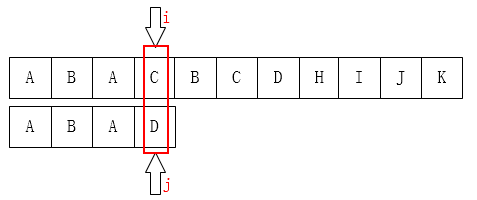
因为主串匹配失败的位置前面除了第一个A之外再也没有A了,我们为什么能知道主串前面只有一个A?因为我们已经知道前面三个字符都是匹配的!(这很重要)。移动过去肯定也是不匹配的!有一个想法,i可以不动,我们只需要移动j即可,如下图:
KMP算法。其思想:“利用已知部分匹配这个有效信息,保持i指针不回溯,通过修改j指针,让模式串尽量地移动到有效的位置。”



当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。
如果用数学公式来表示:P[0 ~ k-1] == P[j-k ~ j-1]

当T[i] != P[j]时
有T[i-j ~ i-1] == P[0 ~ j-1]
由P[0 ~ k-1] == P[j-k ~ j-1]
必然:T[i-k ~ i-1] == P[0 ~ k-1]
next[j]的值(也就是k)表示,当P[j] != T[i]时,j指针的下一步移动位置。
先来看第一个:当j为0时,如果这时候不匹配,

像上图这种情况,j已经在最左边了,不可能再移动了,这时候要应该是i指针后移。所以在代码中才会有next[0] = -1;这个初始化。
当j为1

显然,j指针一定是后移到0位置的。因为它前面也就只有这一个位置
下面这个是最重要的,请看如下图:


请仔细对比这两个图。
我们发现一个规律:
当P[k] == P[j]时,
有next[j+1] == next[j] + 1
其实这个是可以证明的:
因为在P[j]之前已经有P[0 ~ k-1] == p[j-k ~ j-1]。(next[j] == k)
这时候现有P[k] == P[j],我们是不是可以得到P[0 ~ k-1] + P[k] == p[j-k ~ j-1] + P[j]。
即:P[0 ~ k] == P[j-k ~ j],即next[j+1] == k + 1 == next[j] + 1。
这里的公式不是很好懂,还是看图会容易理解些。
那如果P[k] != P[j]呢?比如下图所示:

像这种情况,如果你从代码上看应该是这一句:k = next[k];如下图:

k = next[k],像上边的例子,我们已经不可能找到[ A,B,A,B ]这个最长的后缀串了,但我们还是可能找到[ A,B ]、[ B ]这样的前缀串的。所以这个过程像不像在定位[ A,B,A,C ]这个串,当C和主串不一样了(也就是k位置不一样了),把指针移动到next[k]。
def KMP(A,P):#O(M+N)
i = 0#主串的位置
j = 0#模式串的位置
nextArray = getNext(P)
while i < len(A) and j < len(P):
if j == -1 or A[i] == P[j]:
i += 1
j += 1
else:#i不回溯
j = nextArray[j]#j回到指定位置
if j == len(P):
return i-j
else:
return -1
def getNext(P):
nextArray = [0 for i in range(len(P))]
nextArray[0] = -1
j = 0
k = -1
while j < len(P)-1:
if k == -1 or P[j] == P[k]:
j += 1
k += 1
if P[j] == P[k]:#两个字符相等跳过
nextArray[j] = nextArray[k]
else:
nextArray[j] = k
else:
k = nextArray[k]
return nextArray
if __name__ == '__main__':
A = "ABACBCDHI"
P = "CD"
res = KMP(A,P)
print(res)