SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines 论文学习
SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines 论文学习
- 论文阅读总结
- Translation
- Abstract
- 1 Introduction
- 2 Related Work
- 3 SiamFC++: Fully Convolutional Siamese Tracker for Object Tracking
- Siamese-based Feature Extraction and Matching
- Application of Design Guidelines in Head Network
- 4 Experiments
- Implementation Details
- From SiamFC towards SiamFC++
- Quality Assessment Choice
- Results on Several Benchmarks
- Comparison with Trackers that Do not Apply Our Guidelines
- 5 Conclusions
论文阅读总结
-
Research Objective
作者是针对视觉目标追踪问题进行研究的。 -
Problem Statement
视觉目标追踪问题要求对给定目标同时有效地执行分类和准确的目标边界框回归。之前已经提出了很多目标边界框估计方法,但是很少有方法考虑到视觉目标追踪问题本身的特性。本文就是针对视觉目标追踪问题本身的特性提出了4个通用追踪器设计的准则。 -
Method(s)
- 提出了4个通用追踪器准则:G1,分别进行分类和目标状态分支;G2,无歧义的分类得分;G3,无先验知识的追踪;G4,估计质量得分;
- 对SiamFC进行改进,使其满足提出的通用追踪器准则,设计了SiamFC++。SiamFC++相对于SiamFC改进的核心是,增加了边界框回归分支和质量估计分支,注意这里的边界框回归分支和SiamRPN系列方法依据anchor进行回归不同,这里是直接回归分类中心位置到地面真实边界框的上下左右四条边的距离。通过增加这两个分支,可以满足提出了4个通用追踪器准则 ,达到了目前的SOTA效果。
-
Evaluation
论文在OTB2015、VOT2018、LaSOT、GOT-10k、TrackingNet五个具有挑战性的追踪基准上进行测试,证明了SiamFC++的追踪能力和泛化能力。
另外,这篇论文的消融实验做的非常有说服力,把每增加一个组件所产生的增益都计算出来了,可以借鉴。 -
Conclusion
在本文中,作者通过分析视觉跟踪任务的独特特征和以前跟踪器的缺陷,提出了一套用于跟踪器设计中目标状态估计的准则。 遵循这些准则,论文提出了一种为分类和目标状态估计(G1)提供有效方法的方法,给出了不含歧义的分类评分(G2),没有先验知识的跟踪(G3),并且明确估计质量(G4)。 论文通过广泛的消融研究验证了提出的准则的有效性。 而且,论文证明了基于这些准则的跟踪器可以在五个具有挑战性的基准上达到SOTA,同时仍以90 FPS的速度运行。 -
Notes
(1) 单目标追踪论文阅读系列(二)——《SiamFC++(AAAI 2020)》
Translation
Abstract
视觉跟踪问题要求对给定目标同时有效地执行鲁棒的分类和准确的目标状态估计。以前的方法已经提出了各种目标状态估计的方法,但是很少有方法考虑到视觉跟踪问题本身的特殊性。在仔细分析的基础上,我们提出了一套针对高性能通用对象跟踪器设计的目标状态估计实用指南。遵循这些准则,我们通过引入分类和目标状态估计分支(G1),无歧义的分类得分(G2),无先验知识的跟踪(G3)和估计质量得分(G4),设计了全卷积孪生跟踪器++(SiamFC ++)。广泛的分析和消融研究证明了我们提出的指南的有效性。毫不吹嘘,我们的SiamFC ++跟踪器在五个具有挑战性的基准(OTB2015,VOT2018,LaSOT,GOT-10k,TrackingNet)上实现了最先进的性能,证明了跟踪器的跟踪能力和泛化能力。特别是,在大规模TrackingNet数据集上,SiamFC ++在以超过90 FPS的速度运行时达到了75.4的前所未有的AUC分数,这远远超出了实时要求。
1 Introduction
通用视觉跟踪的目的是在给定非常有限的信息(通常仅是第一帧的注释)的情况下,在视频序列中定位运动对象。 作为计算机视觉各个领域的基本构建块,该任务伴随着多种应用,例如基于无人机的监视(Mueller,Smith和Ghanem 2016)和监视系统(Kokkeby等人,2015)。 通用对象跟踪的一个独特特征是不允许有关对象及其周围环境的先验知识(例如,对象的类别)(Huang,Zhao和Huang 2018)。
跟踪问题可以视为分类任务和估计任务的组合(Danelljan等人2019)。第一项任务旨在通过分类为目标提供可靠的粗略定位。然后,第二项任务是估计准确的目标状态,目标状态通常由边界框表示。尽管现代跟踪器已经取得了重大进展,但令人惊讶的是,他们用于第二项任务的方法(即目标状态估计)差异很大。基于目标状态估计这个方面,先前的方法可以大致分为三类。第一类包括判别相关滤波器(DCF)(Henriques等人2014; Bolme等人2010)和SiamFC(Bertinetto等人2016),采用了暴力的多尺度测试(Danelljan等人2019),这样做非常不准确,而且效率低下(Li等人2018a)。而且,目标的尺度和长宽比率在相邻帧中以固定速率变化这一假设通常并不现实。对于第二类,ATOM(Danelljan et al.2019)通过梯度递增迭代地优化多个初始边界框以估计目标边界框(Jiang等人2018),这在准确性上产生了重大改进。但是,这种目标估计方法不仅带来沉重的计算负担,而且带来许多其他需要仔细调整的超参数(例如,初始box的数量,初始box的分布)。第三类是SiamRPN跟踪器系列(Li等人2018a; Zhu等人2018; Li等人2019),通过引入区域提议网络(RPN)来执行准确而有效的目标状态估计(Ren等人2015) )。但是,预定义的anchor设置不仅引入了模糊的相似性评分,严重破坏了鲁棒性(请参见第4节),而且还需要数据分布的先验信息,这显然与通用对象跟踪的目标背道而驰(Huang,Zhao,和Huang 2018)。
(在读过论文后面之后,其实本文方法的核心是将基于anchor的追踪框预测直接变成 基于对中心到地面真实边界框上下左右四个边的距离的预测上来。之前应用anchor的目标是为了解决SiamFC在追踪的过程中,只能进行目标的中心位置的定位,而对于边界框的尺寸和长宽比却没有办法,这一问题。但是如果能直接回归中心到地面真实边界框的距离的话,就可以直接解决这一问题了。这一个变化,直接满足了G1、G2和G3。添加回归质量评估G4主要是为了提高位置回归的准确性。)
基于上述分析,我们为高性能通用对象跟踪器设计提出了一套准则:
- G1: 分开进行分类和状态估计。跟踪器应执行两个子任务:分类和状态估计。 没有强大的分类器,追踪器就无法将目标与背景或干扰因素区分开,这严重阻碍了目标的鲁棒性(Zhu et al.2018)。 没有准确的状态估算结果,跟踪器的准确性将受到根本限制(Danelljan等人2019)。 这些暴力的多尺度测试方法由于效率低下和准确性低而很大程度上忽略了状态估计的任务。
- G2:无歧义评分。分类分数应该直接表示目标存在的置信度分数,即在“视野”中,即对应像素的子窗口,而不是诸如anchor box之类的预定义设置。 对于一个负例,对象与锚点之间的匹配(例如,基于锚点的RPN分支)容易产生假阳性结果,从而导致跟踪失败(更多信息请参见第4节)。(基于anchor的孪生追踪方法评分的歧义主要体现在在搜索图像的一个位置上,打了很多anchor,根据anchor的得分来选择追踪预测anchor,这个过程是歧义的)
- G3:无先验信息。跟踪方法应该没有像尺度/长宽比分布这样的先验知识,这是通用对象跟踪的目标提出的(Huang,Zhao和Huang 2018)。 现有方法广泛依赖于数据分布的先验知识,这阻碍了泛化能力。
- G4:估计质量评估。如之前的研究(Jiang等,2018; Tian等,2019)所示,将分类置信度用于边界框选择将直接导致性能下降。 与先前关于对象检测和跟踪的许多研究一样,应该使用与分类无关的估计质量评分(Jiang等人2018; Tian等人2019; Danelljan等人2019)。 第二个分支(例如ATOM和DiMP)的惊人准确性很大程度上取决于此准则。 尽管其他人仍然忽略了它,但仍有进一步提高状态估计准确性的空间。(估计质量的评估,其实是对回归结果质量的评估,我感觉是用于最终的预测追踪框的选取。)
根据上述准则,我们基于全卷积孪生跟踪器(Bertinetto等人,2016年)设计了SiamFC ++方法,由于其全卷积性质,特征图的每个像素直接对应于搜索图像上的每个变换子窗口 。 我们与分类头(G1)并行添加一个回归头,以进行准确的目标估计。 由于预先定义的anchor设置已删除,因此有关目标尺度和长宽比分布的匹配歧义(G2)和先验知识(G3)也已删除。 最后,在G4之后,将评估质量评估分支添加到具有高质量的优先边界框。
我们的贡献可以概括为三个方面:
(1)通过识别跟踪的独特特征,我们为现代跟踪器设计设计了一套实用的目标状态估计准则。
(2)我们根据提出的准则设计了一个简单但功能强大的SiamFC ++跟踪器。 大量的实验和综合分析证明了我们提出的指南的有效性。
(3)我们的方法在五个具有挑战性的基准上获得了最新的结果。 据我们所知,我们的SiamFC ++是第一个在大型TrackingNet数据集(Muller等人,2018年)上以90 FPS运行时AUC得分达到75.4的跟踪器。
2 Related Work
Tracking Framework
现代跟踪器可以通过其目标状态估计的方式大致分为三个分支。
其中一些方法,包括DCF(Henriques等人,2014; Bolme等人,2010)和SiamFC(Bertinetto等人,2016),使用多尺度测试来估算目标尺度。 具体地,通过将搜索图像重新缩放为多个比例并组装一个小批量的缩放图像,该算法选择与最高分类得分相对应的比例作为当前帧中的预测目标比例。 该方法从根本上受到限制,因为边界框估计本质上是一项艰巨的任务,需要对对象的姿势有一个高层次的理解(Danelljan等人2019)。
受DCF和IoU-Net(Jiang等人2018)的启发,ATOM(Danelljan等人2019)通过顺序地执行分类和估计来跟踪目标。 对通过分类获得的目标的粗略初始位置进行迭代完善,以进行准确的追踪框估计。 每帧边界框的多次随机初始化以及迭代完善中的多次反向传播大大降低了ATOM的速度。 该方法在准确性上产生了显着的改进,但是也带来了沉重的计算负担。 此外,ATOM引入了许多其他需要仔细调整的超参数。
另一个名为SiamRPN的分支机构及其后续工作(Li等人2018a; Zhu等人2018; Li等人2019)在孪生网络后附加了区域提议网络,从而实现了前所未有的准确性。 RPN回归预定义锚框和目标位置之间的位置偏移和大小差异。 但是,RPN结构更适合于需要高召回率的对象检测,而在视觉跟踪中,仅应跟踪一个对象。 而且,锚框和物体之间的模棱两可的匹配严重地阻碍了跟踪器的鲁棒性(请参见第4节)。 最后,锚设置不符合通用对象跟踪的精神,需要预先定义的描述其形状的超参数。
Detection Framework
视觉跟踪任务具有许多独特的特征,它与对象检测仍有很多共同点,这使得两个任务都可以从彼此受益。例如,首先在Faster-RCNN中设计的RPN结构(Ren等人,2015)在SiamRPN中的应用达到了惊人的准确性(Li等人,2018a)。继承于Faster-RCNN(Ren等人,2015),大多数最先进的现代检测器(基于锚的检测器)都采用了RPN结构和锚点的设置(Ren等人,2015; Liu等人 2016; Li等人2018b)。基于锚点的检测器将称为锚点的预定义提议分类为正例或负例,并通过额外的偏移量回归来完善对边界框位置的预测。但是,锚点框引入的超参数(例如锚定框的尺度/比率)已对最终精度产生很大影响,并且需要启发式调整(Cai和Vasconcelos 2018; Tian等人2019)。研究人员尝试了多种方法来设计anchor-free的检测器,例如预测物体中心附近的点处的边界框(Redmon等人2016; Huang等人2015),或者检测并组合边界框的一对角点(Law and Deng 218)。在本文中,我们表明,受(Huang等人2015; Yu等人2016; Tian等人2019)启发,基于精心设计的目标状态估计准则的简单技术路线可以实现最先进的跟踪性能。

3 SiamFC++: Fully Convolutional Siamese Tracker for Object Tracking
在本节中,我们将详细描述我们的Fully Convolutional Siamese tracker ++框架。 我们的SiamFC ++基于SiamFC,并根据提出的准则逐步完善。 如图2所示,SiamFC ++框架由用于特征提取的孪生子网络和用于分类和回归的区域提议子网络组成。
Siamese-based Feature Extraction and Matching
对象跟踪任务可以看作是一个相似性学习问题(Li et al.2018a)。 具体来说,是对孪生网络进行离线训练并对其进行在线评估,以便在较大的搜索图像中定位模板图像。 孪生网络由两个分支组成。 模板分支将第一帧中的目标图像块作为输入(表示为 z z z),而搜索分支将当前帧作为搜索图像输入(表示为 x x x)。 在两个分支之间共享参数的孪生主干对输入 z z z和 x x x执行相同的变换,以将它们嵌入到公共特征空间中以用于后续任务。在嵌入空间中执行模板图像与搜索图像之间的互相关 ϕ \phi ϕ:
f i ( z , x ) = ψ i ( ϕ ( z ) ) ⋆ ψ i ( ϕ ( x ) ) , i ∈ { cls, reg } f_{i}(z, x)=\psi_{i}(\phi(z)) \star \psi_{i}(\phi(x)), i \in\{\text { cls, reg }\} fi(z,x)=ψi(ϕ(z))⋆ψi(ϕ(x)),i∈{ cls, reg }
其中 ⋆ \star ⋆表示互相关运算, ϕ \phi ϕ表示通用特征提取的孪生主干网络, ψ i \psi_i ψi表示特定于任务的层, i i i表示子任务类型(用于分类的“ cls”,用于回归的“ reg” )。 在我们的实现中,我们在共同特征提取后对 ψ c l s \psi_{cls} ψcls和 ψ r e g ψ_{reg} ψreg使用两个卷积层,以将共同特征调整到特定任务的特征空间中。 请注意,提取的 ψ c l s \psi_{cls} ψcls和 ψ r e g ψ_{reg} ψreg特征具有相同的大小。
Application of Design Guidelines in Head Network
基于SiamFC,我们会按照提出的指南逐步完善跟踪器的每个部分。
遵循G1 (分类和和状态估计分开进行) ,我们在嵌入空间中进行互相关后设计分类头和回归头。 对于特征图中的每个像素,分类头将 ψ c l s \psi_{cls} ψcls作为输入,并将相应的图像块分类为一个正例和负例,而回归头将 ψ r e g ψ_{reg} ψreg作为输入,并输出额外的偏移量回归以优化边界框位置的预测 。 分类头和回归头的结构在图2的互相关操作之后给出。
具体而言,对于分类分支,如果特征图 ψ c l s \psi_{cls} ψcls上的一个位置 ( x , y ) (x,y) (x,y)对应的输入图像位置 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) \left(\left\lfloor\frac{s}{2}\right\rfloor+ x s,\left\lfloor\frac{s}{2}\right\rfloor+ y s\right) (⌊2s⌋+xs,⌊2s⌋+ys)落在地面真实边界框中,那个特征图的的位置 ( x , y ) (x,y) (x,y)就认为是正例。否则,特征图的的位置 ( x , y ) (x,y) (x,y)就是负例。这里的 s s s是主干网络的总步幅(这篇论文中 s = 8 s=8 s=8)。对于特征图 ψ r e g \psi_{reg} ψreg上的每个位置 ( x , y ) (x,y) (x,y)的回归任务,最后一层预测特征图 ψ r e g \psi_{reg} ψreg上的每个位置 ( x , y ) (x,y) (x,y)对于的输入图像位置 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) \left(\left\lfloor\frac{s}{2}\right\rfloor+ x s,\left\lfloor\frac{s}{2}\right\rfloor+ y s\right) (⌊2s⌋+xs,⌊2s⌋+ys)到地面真实边界框上下左右四个边的距离,将这个距离表示为一个4维的向量 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) \boldsymbol{t}^{*}=\left(l^{*}, t^{*}, r^{*}, b^{*}\right) t∗=(l∗,t∗,r∗,b∗)。因此,对于位置 ( x , y ) (x,y) (x,y)的回归任务可以形式化为: l ∗ = ( ⌊ s 2 ⌋ + x s ) − x 0 , t ∗ = ( ⌊ s 2 ⌋ + y s ) − y 0 r ∗ = x 1 − ( ⌊ s 2 ⌋ + x s ) , b ∗ = y 1 − ( ⌊ s 2 ⌋ + y s ) \begin{aligned} &l^{*}=\left(\left\lfloor\frac{s}{2}\right\rfloor+ x s\right)-x_{0}, \quad t^{*}=\left(\left\lfloor\frac{s}{2}\right\rfloor+ y s\right)-y_{0}\\ &r^{*}=x_{1}-\left(\left\lfloor\frac{s}{2}\right\rfloor+ x s\right), \quad b^{*}=y_{1}-\left(\left\lfloor\frac{s}{2}\right\rfloor+ y s\right) \end{aligned} l∗=(⌊2s⌋+xs)−x0,t∗=(⌊2s⌋+ys)−y0r∗=x1−(⌊2s⌋+xs),b∗=y1−(⌊2s⌋+ys)其中 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)和 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)表示与 ( x , y ) 对 应 的 (x,y)对应的 (x,y)对应的地面真实边界框 B ∗ B^{*} B∗的左上角和右下角。
分类和回归头特征图上的位置 ( x , y ) (x,y) (x,y),对应于输入图像上的中心在 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) \left(\left\lfloor\frac{s}{2}\right\rfloor+ x s,\left\lfloor\frac{s}{2}\right\rfloor+ y s\right) (⌊2s⌋+xs,⌊2s⌋+ys)的一个图像块。对于准则G2 (无歧义的评分) ,我们像许多以前的追踪器一样,直接对相应的图像块进行分类,并在该位置回归目标边界框(Henriques等,2014; Bolme等,2010; Bertinetto等,2016)。换句话说,我们的SiamFC ++直接将位置视为训练样本。基于锚的追踪器(Li等人2018a; Zhu等人2018; Li等人2019)将输入图像上的位置视为多个锚点框的中心,却在同一位置输出多个分类得分并相对于这些锚定框回归目标边界框,从而导致锚定和对象之间的模棱两可的匹配。尽管(Li等人2018a; Zhu等人2018; Li等人2019)在各种基准上表现出比(Henriques等人2014; Bolme等人2010; Bertinetto等人2016)更好的表现,但我们经验上认为模棱两可的匹配可能会导致严重的问题(有关更多详细信息,请参见第4节)。以我们的每像素预测方式,最终特征图上的每个像素仅进行一次预测。因此,很明显,每个分类得分都直接表明目标位于相应像素的子窗口中,并且我们的设计在这个程度上是没有歧义的。
由于SiamFC ++直接关于位置进行分类和回归,它没有预定义的锚框,因此也没有关于目标数据分布(例如尺度/长宽比)的先验知识,完全符合G3。 (通用目标追踪器不使用先验信息。)
在以上各节中,我们尚未考虑目标状态估计的质量,而是直接使用分类得分来选择最终预测框。 这可能会导致定位精度降低,因为(Jiang et al.2018)表明分类置信度与定位精度没有很好的相关性。 根据(Luo et al.2016)中的分析,子窗口中心周围的输入像素在相应的输出特征像素上的重要性将高于其余部分。 因此,我们假设对象中心周围的特征像素将比其他像素具有更好的估计质量。根据准则G4 (状态估计质量的评估) ,我们通过与 1 × 1 1×1 1×1卷积分类头并行添加 1 × 1 1×1 1×1卷积层来添加类似于(Tian等人2019; Jiang等人2018)的简单但有效的质量评估分支,如图2的右侧。该输出应该用于估计优先级空间得分(PSS),其定义如下:
P S S ∗ = min ( l ∗ , r ∗ ) max ( l ∗ , r ∗ ) × min ( t ∗ , b ∗ ) max ( t ∗ , b ∗ ) \mathrm{PSS}^{*}=\sqrt{\frac{\min \left(l^{*}, r^{*}\right)}{\max \left(l^{*}, r^{*}\right)} \times \frac{\min \left(t^{*}, b^{*}\right)}{\max \left(t^{*}, b^{*}\right)}} PSS∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)注意,PSS不是状态估计质量评估的唯一选择。 作为变体,我们还可以预测类似于(Jiang等人2018)的预测框和地面真实框之间的IoU得分:
IoU ∗ = Intersection ( B , B ∗ ) Union ( B , B ∗ ) \operatorname{IoU}^{*}=\frac{\operatorname{Intersection}\left(B, B^{*}\right)}{\operatorname{Union}\left(B, B^{*}\right)} IoU∗=Union(B,B∗)Intersection(B,B∗)其中 B B B是预测的边界框,而 B ∗ B^{∗} B∗是其对应的地面真实边界框。
在推理的过程中,通过将PSS与相应的预测分类得分相乘,计算出用于最终预测追踪框选择的得分。 这样,远离物体中心的那些边界框将被严重地减小权重。 因此,提高了跟踪精度。
Training Objective
我们优化训练目标如下:
L ( { p x , y } , q x , y , { t x , y } ) = 1 N pos ∑ x , y L cls ( p x , y , c x , y ∗ ) + λ N pos ∑ x , y 1 { c x , y ∗ > 0 } L quality ( q x , y , q x , y ∗ ) + λ N pos ∑ x , y 1 { c x , y ∗ > 0 } L reg ( t x , y , t x , y ∗ ) \begin{array}{c} L\left(\left\{p_{x, y}\right\}, q_{x, y},\left\{\boldsymbol{t}_{x, y}\right\}\right)=\frac{1}{N_{\text {pos }}} \sum_{x, y} L_{\text {cls }}\left(p_{x, y}, c_{x, y}^{*}\right) \\ +\frac{\lambda}{N_{\text {pos }}} \sum_{x, y} \mathbf{1}_{\left\{c_{x, y}^{*}>0\right\}} L_{\text {quality }}\left(q_{x, y}, q_{x, y}^{*}\right) \\ +\frac{\lambda}{N_{\text {pos }}} \sum_{x, y} \mathbf{1}_{\left\{c_{x, y}^{*}>0\right\}} L_{\text {reg }}\left(\boldsymbol{t}_{x, y}, \boldsymbol{t}_{x, y}^{*}\right) \end{array} L({px,y},qx,y,{tx,y})=Npos 1∑x,yLcls (px,y,cx,y∗)+Npos λ∑x,y1{cx,y∗>0}Lquality (qx,y,qx,y∗)+Npos λ∑x,y1{cx,y∗>0}Lreg (tx,y,tx,y∗)其中 1 { ⋅ } 1_{\{·\}} 1{⋅}是指标函数,如果下标中的条件成立,则取1,否则将取0。 L c l s L_{cls} Lcls表示分类结果的focal loss(Lin等人,2017), L q u a l i t y L_{quality} Lquality表示用于质量评估的二进制交叉熵(BCE)损失, L r e g L_{reg} Lreg表示边界框结果的IoU损失(Yu等人2016)。 如果将 ( x , y ) (x,y) (x,y)视为正样本,则将1分配给 c x , y ∗ c^{∗}_{x,y} cx,y∗,如果是负样本,则将0赋给 c x , y ∗ c^{∗}_{x,y} cx,y∗。
4 Experiments
Implementation Details
Model settings. 在这项工作中,我们实现了两种具有不同主干架构的跟踪器版本:一种采用了先前文献(Bertinetto et al.2016)中的AlexNet的修改版本,称为SiamFC ++ - AlexNet,另一种则使用GoogLeNet( Szegedy等人,2015年),表示为SiamFC +±GoogLeNet。 以较低的计算成本,与使用ResNet-50(He等,2016)的先前方法相比,后者在跟踪基准方面可获得相同甚至更好的性能(请参见表4)。 两种网络都在ImageNet上进行了预训练(Krizhevsky,Sutskever和Hinton 2012),事实证明,这两种方法对于跟踪任务非常有效(Li等人2018a; Zhu等人2018)。 我们将发布代码以方便进一步的研究。
Training data. 我们采用ILSVRC-VID / DET(Russakovsky et al.2015),COCO(Lin et al.2014),YoutubeBB(Real et al.2017),LaSOT(Fan et al.2019)和GOT-10k(Huang,Zhao, 和Huang(2018)。 训练数据的特例会在以下各节将详细介绍特定基准。 对于视频数据集,我们通过从VID,LaSOT和GOT-10k中提取图像对,选择小于100的间隔内的帧对(Youtube-BB为5个)。 对于图像数据集(COCO / ImagenetDET),我们通过包含负对来生成训练样本(Zhu等人2018),作为训练样本的一部分,以增强区分模型干扰因素的能力。 另一种数据增强技术是,我们在搜索图像上按照均匀分布执行随机移位和缩放。
Training phase. 对于AlexNet版本,我们将从conv1到conv3的参数冻结,并微调conv4和conv5。 对于没有预训练的那些层,我们采用0.01的标准偏差的零中心高斯分布进行初始化。 我们首先使用热启动训练5轮模型,学习率从 1 0 − 7 10^{-7} 10−7线性增加到 2 × 1 0 − 3 2×10^{−3} 2×10−3,然后对其余45轮使用余弦退火学习率策略,每轮有60万个图像对。 我们选择动量为0.9的随机梯度下降(SGD)作为优化程序。
对于使用GoogLeNet实现的版本,我们冻结了第1阶段和第2阶段的参数,对第3阶段和第4阶段的参数进行了微调,将基本学习率提高到 2 × 1 0 − 2 2×10^{−2} 2×10−2,并将骨干中参数的学习率根据全局学习乘以0.1。 我们还将每轮训练的图像对数量减少到300k,将总的训练轮数减少到20轮(热启动5轮,训练15轮),并在第10轮训练中解冻主干中的参数以避免过度拟合。 对于LaSOT基准测试(Fan等人,2019年)(协议II),我们冻结了骨干中的参数,并进一步将每轮训练中的图像对数量减少到150k,以便使用相对较少数量的训练数据使训练稳定下来。
拟议中的带有AlexNet主干的跟踪器在VOT2018短期基准上以160 FPS运行,而带有GoogleNet主干的跟踪器在VOT2018短期基准上以约90 FPS运行,二者均在NVIDIA RTX 2080Ti GPU上进行了评估。
Test phase. 我们模型的输出是一组带有相应置信度得分 s s s的边界框。 根据相应框的尺度和长宽比变化以及距上一帧中预测的目标位置的距离,对分数进行惩罚。 然后,选择惩罚分最高的框并将其用于更新目标状态。(这个惩罚应该依据的是视频目标运动假设。)
From SiamFC towards SiamFC++

虽然两者均采用按像素的预测方式,但SiamFC与我们的SiamFC ++之间存在明显的性能差距。 在本小节中,我们将以SiamFC为基准对VOT2018数据集进行消融研究,旨在确定改善跟踪性能的关键组件。
结果如表1所示。具体而言,在SiamFC基准中,跟踪器仅在其网络中执行分类任务,而目标状态估计则通过多尺度测试完成。 我们通过使用额外的训练数据(第2/4行),应用更好的头部结构(第3行)并添加回归分支(第5行)以进行准确估算来逐步更新SiamFC跟踪器。 我们进一步用GoogLeNet替换了AlexNet主干(第6行),它更强大地提取了视觉特征。
跟踪性能提升的关键组成部分可以按降序列出,如下所示:回归分支(0.094),数据源的多样性(0.063/0.010),更强大的主干网络(0.026),更强大的头结构(0.020),其中每个部分所带来的 Δ \Delta ΔEAO列在括号里。 请注意,这些是SiamRPN ++在SiamFC上的额外添加的组件。 将所有其他组件添加到SiamFC中之后,我们的SiamFC ++可以以更少的计算负担实现卓越的性能。 另外,有两件事值得一提:1)第2行的鲁棒性(R)超过SiamRPN跟踪器(0.46(Li et al.2018a)); 2)第3行的R与DaSiamRPN的水平相同(0.337(Zhu et al.2018)),但使用的训练数据少于后者(没有COCO和DET)。 这些结果表明,虽然引入RPN模块和anchor设置无疑会提供更好的准确性,但追踪器的鲁棒性并没有得到改善甚至受到阻碍。 我们将此归因于它违反了我们提出的准则。
Quality Assessment Choice
在GOT-10k val子集中,对于跟踪器预测PSS,我们获得AO为77.8,对于跟踪器预测IoU,我们获得AO为78.0。我们使用的是SiamFC +±GoogLeNet进行实验。 我们最终选择本文中的PSS作为我们方法的实现方式,因为在实验过程中在整个数据集中凭经验观察到了其稳定性。
Results on Several Benchmarks
我们在几个基准上测试了跟踪器,结果汇总在表2中。
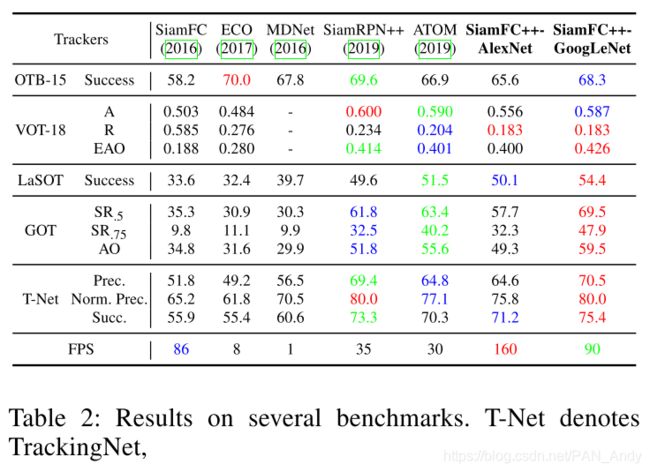
Results on OTB2015 Benchmark. 作为对象跟踪任务的最经典基准之一,OTB基准(Wu,Lim和Yang,2013年)为所有跟踪器系列提供了公平的测试。 我们在OTB2015(Wu,Lim和Yang 2013)上进行了实验,其中包含100个用于跟踪器性能评估的视频。 我们的跟踪器以0.682的成功评分与其他追踪器相比达到了的最先进水平。
Results on VOT Benchmark. VOT2018(Kristan等人,2018年)包含60个视频序列,其中包含一些具有挑战性的主题,包括快速运动、遮挡等。我们在此基准上测试跟踪器,并将结果显示在表2中。两种版本的跟踪器均达到与其他追踪器可比较的分数。 具有AlexNet骨干的跟踪器在跟踪速度时,性能远优于其他跟踪器。而具有GoogLeNet骨干的跟踪器也可得到可比的分数。 此外,相比之下,我们的跟踪器在跟踪器的鲁棒性方面具有显着优势。 据我们所知,这是第一个在VOT2018(Kristan et al.2018)基准上达到EAO 0.400的跟踪器,同时以超过100 FPS的速度运行,证明了其在实际案例中应用的潜力。
Results on LaSOT Benchmark. LaSOT(Fan等人,2019年)(大型单一对象跟踪)基准具有大量视频序列(协议I下为1400个序列,协议II下为280个序列)基准,使得跟踪器无法过度拟合基准,从而能够测试对象跟踪的真实性能。 根据协议II,在LaSOT训练集上对跟踪器进行训练并在LaSOT测试集上进行评估,提出的SiamFC ++跟踪器达到了更好的结果,即使是与在VOT2018基准测试中表现更优的方法相比。 这揭示了一个事实,即基准的规模会影响跟踪器的测试等级。
Results on GOT-10k Benchmark. 对于目标类别泛化测试,我们在GOT-10k(Huang,Zhao和Huang 2018)(Generic Object Tracking-10k)基准上训练和测试我们的SiamFC ++模型。 不仅作为一个大型数据集(训练集中有10,000个视频,验证集和测试集中有180个视频),它对于通用对象跟踪器的类别不可知的要求也提出了挑战,因为训练和测试集上没有类别交叉。 我们遵循GOT-10k的协议,仅在训练集中训练我们的跟踪器。 我们的带有AlexNet主干的跟踪器的AO达到53.5,比SiamRPN ++高1.7,而我们带有GoogLeNet主干的跟踪器得到59.5,甚至优于使用在线更新方法的ATOM。 此结果表明,即使在训练阶段无法得知目标类别的情况下,我们的跟踪器也能够满足通用的跟踪需求。
Results on TrackingNet Benchmark. 我们使用TrackingNet的测试部分中提供的511个视频评估了我们的方法(Muller等人2018)。 我们从训练数据中排除了Youtube-BB数据集,以避免数据泄漏。 如(Muller et al.2018)中所述,评估服务器基于跟踪结果计算以下三个指标:成功率,精度和归一化精度。 我们的SiamFC +±GoogLeNet在精度和成功率方面都胜过当前的最新方法(包括在线更新方法,例如(Danelljan等人2019)),而我们的轻量级版本SiamFC ++在性能和速度之间取得了平衡。 即使Youtube-BB不包含大量训练数据,也可以实现此结果,这表明我们的方法独立于大型离线训练数据的潜力。
Comparison with Trackers that Do not Apply Our Guidelines
近年来,SiamRPN家族(Li等人2018a; Zhu等人2018; Li等人2019)在视觉跟踪领域取得了巨大成功,并引起了跟踪社区的广泛关注。 在这里,我们以最先进的SiamRPN ++跟踪器为例。 尽管SiamRPN家族最近取得了成功,但我们发现SiamRPN跟踪器及其家族并未完全遵循我们提出的指南。
- (G2)SiamRPN的分类得分表示锚点和对象之间的相似性,而不是模板图像中的对象和搜索图像中的对象之间的相似性,这可能导致匹配模糊性;
- (G3)预设锚框的设计需要事先了解目标的尺寸和比例的分布;
- (G4)目标状态估计的选择未考虑估计质量。
请注意,SiamRPN系列通过回归分支而不是多尺度测试来完善区域提议,从而实现了惊人的跟踪准确性,这符合我们的准则G1。
(也就是说,SiamRPN系列的方法很容易将目标附近的对象和背景检测成待追踪目标。虽然有DaSiamRPN之类的,针对相似干扰物对孪生追踪器性能的影响作出研究,但是即使到了SiamRPN++,SiamRPN系列的追踪方法仍然遭受着鲁棒性较低问题。)
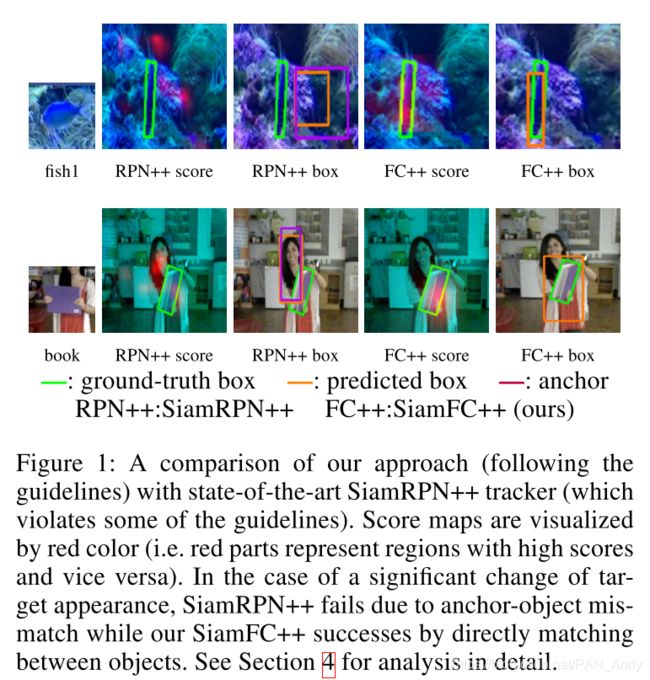
由于违反了准则G2,我们从经验上发现SiamRPN家族容易产生假阳性结果。 换句话说,在目标对象的外观变化很大的情况下,SiamRPN会对附近的对象或背景产生不合理的高分。 如图1所示,我们可以看到SiamRPN ++无法追踪目标,因为它会在平面外旋转和变形等具有挑战性的情况下为附近物体(即岩石或人脸)给出很高的分数。 我们假设SiamRPN是对目标和锚点进行匹配,而不是目标本身,这可能会导致漂移并因此影响其鲁棒性。 相反,我们提出的SiamFC ++可直接在模板对象与搜索图像中的对象之间进行匹配,从而给出准确的分数预测并成功跟踪目标。(论文中为SiamRPN系列方法鲁棒性较低给出的假设是,SiamRPN的检测实质是对搜索图像和模板图像中的锚点图像块进行匹配,而不是匹配的模板图像中的目标本身。)
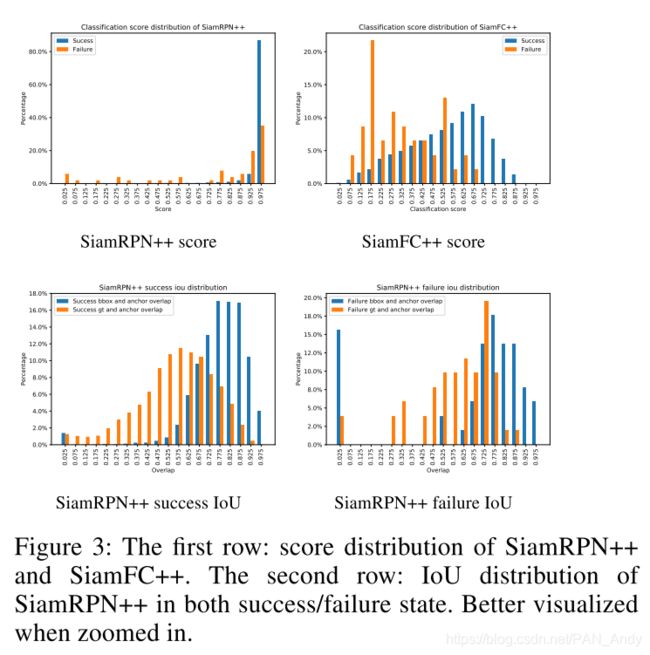
(对VOT2018数据集上的最高分统计实验,在SiamRPN++进行追踪时,无论成功与否,分类分数的分布是相同的,即使在追踪失败的情况下,也有很高的分类得分。而SiamFC++追踪成功和失败的分类分数则不同。)
为了验证我们的假设,我们在VOT2018数据集上记录了SiamRPN ++和我们提出的SiamFC ++产生的最高分。 然后,我们根据跟踪结果(例如成功或失败)将其统计拆分。 在VOT2018上,如果跟踪结果与Groundtruth框的重叠为零,则将其视为失败。 否则,它被认为是成功的。 结果在图3的第一行中显示。比较SiamRPN ++和SiamFC ++分数,我们可以看到大多数SiamRPN ++的分类分数遵循相似且高度重叠的分布(成功与否),而我们的SiamFC ++失败状态的分类分数与成功状态则显示出非常不同的模式。
导致SiamRPN ++产生歧义的另一个因素是,特征匹配过程是使用固定长宽比的图像块完成的(多个不同比率的图像块将带来不可忽略的计算成本),而匹配后的特征的每个点都被分配了不同比例的锚点。
至于违反G3的问题,SiamRPN的性能会随着锚点的尺度和长宽比的变化而变化。 如(Li等人2018a)的表3所示,尝试了三种不同的比率设置,并且当使用不同的锚设置时,SiamRPN的性能会有所不同。 因此,仅通过访问数据分布的先验知识即可获得最佳性能,这与通用对象跟踪的精神背道而驰(Huang,Zhao和Huang 2018)。
此外,在图3的第二行中,我们还绘制了成功和失败状态下输出边界框和地面实况之间以及IoU的SiamRPN ++统计IoU的直方图。 如从IoU分布所示,锚设置(违反G3)提供的先验知识会导致目标状态估计产生偏差。 具体而言,SiamRPN ++的预测框倾向于与锚框重叠,而不是与地面真实框重叠,从而导致性能下降。
对于违反G4的情况,我们可以看到,在GOT-10k基准上,SiamRPN ++的SR . 5 _{.5} .5和SR . 75 _{.75} .75分别比SiamFC ++的7.7和15.4点低。 在GOT-10k中,成功率(SR)衡量重叠超过预定阈值(即0.5或0.75)的成功跟踪帧数的百分比。 阈值越高,跟踪结果越准确。 因此,SR是评估质量的可靠指标。 SiamRPN ++的SR . 75 _{.75} .75远低于SiamFC ++的SR . 75 _{.75} .75,表明由于违反准则G4导致SiamRPN ++的估计质量较低。
5 Conclusions
在本文中,我们通过分析视觉跟踪任务的独特特征和以前跟踪器的缺陷,提出了一套用于跟踪器设计中目标状态估计的准则。 遵循这些准则,我们提出了一种为分类和目标状态估计(G1)提供有效方法的方法,给出了不含歧义的分类评分(G2),没有先验知识的跟踪(G3),并且明确估计质量(G4)。 我们通过广泛的消融研究验证了提出的指南的有效性。 而且,我们证明了基于这些准则的跟踪器可以在五个具有挑战性的基准上达到最先进的性能,同时仍以90 FPS的速度运行。