机器学习:NLP(自然语言处理)基础,相似度分析,KNN情感分类
文章目录
- 文本相似度分析
- 1.把评论翻译成机器看的懂的语言
- 1).分词(把句子拆分成词语)
- 2).制作词袋模型(bag-of-word: 可以理解成装着所有词的袋子)
- 3).用词袋模型制作语料库(corpus:把每一个句子都用词袋表示)
- 4).把评论变成词向量(可选的)
- 2.使用机器看的懂得算法轮询去比较每一条和所有评论的相似程度
- TF-IDF
- TF公式:
- IDF公式:
- 案例代码:
- 情感分析
文本相似度分析
文本相似度分析:从海量数据(文章,评论)中,把相似的数据挑选出来
步骤:
- 把评论翻译成机器看的懂的语言
- 使用机器看的懂得算法轮询去比较每一条和所有评论的相似程度
- 把相似的评论挑出来
1.把评论翻译成机器看的懂的语言
1).分词(把句子拆分成词语)
距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较为简单.

[‘距离’, ‘川沙’, ‘公路’, ‘较近’, ‘,’, ‘但是’, ‘公交’, ‘指示’, ‘不’, ‘对’, ‘,’, ‘如果’, ‘是’, ‘"’, ‘蔡陆线’, ‘"’, ‘的话’, ‘,’, ‘会’, ‘非常’, ‘麻烦’, ‘.’, ‘建议’, ‘用’, ‘别的’, ‘路线’, ‘.’, ‘房间’, ‘较为简单’, ‘.’]
2).制作词袋模型(bag-of-word: 可以理解成装着所有词的袋子)
[‘距离’, ‘川沙’, ‘公路’, ‘较近’, ‘,’, ‘但是’, ‘公交’, ‘指示’, ‘不’, ‘对’, ‘,’, ‘如果’, ‘是’, ‘"’, ‘蔡陆线’, ‘"’, ‘的话’, ‘,’, ‘会’, ‘非常’, ‘麻烦’, ‘.’, ‘建议’, ‘用’, ‘别的’, ‘路线’, ‘.’, ‘房间’, ‘较为简单’, ‘.’]

{’"’: 0, ‘,’: 1, ‘.’: 2, ‘不’: 3, ‘会’: 4, ‘但是’: 5, ‘公交’: 6, ‘公路’: 7, ‘别的’: 8, ‘如果’: 9, ‘对’: 10, ‘川沙’: 11, ‘建议’: 12, ‘房间’: 13, ‘指示’: 14, ‘是’: 15, ‘用’: 16, ‘的话’: 17, ‘蔡陆线’: 18, ‘距离’: 19, ‘路线’: 20}
数字表示词语的编号(index)
3).用词袋模型制作语料库(corpus:把每一个句子都用词袋表示)
语料库的两种表现形式
1.第一种: String类型
["a b c",
"b c d"]
2.第二种,词袋类型
[[(0,1), (1,1), (2,1), (3,0)],
[(0,0), (1,1), (2,1), (3,1)]]
如果新得到一组数据,可以把它用两种形式加入到语料库中
1. String类型
"c d e",
2. 词袋类型
[(0,0), (1,0),(2,1),(3,1),(unknow,1)]
[‘距离’, ‘川沙’, ‘公路’, ‘较近’, ‘,’, ‘但是’, ‘公交’, ‘指示’, ‘不’, ‘对’, ‘,’, ‘如果’, ‘是’, ‘"’, ‘蔡陆线’, ‘"’, ‘的话’, ‘,’, ‘会’, ‘非常’, ‘麻烦’, ‘.’, ‘建议’, ‘用’, ‘别的’, ‘路线’, ‘.’, ‘房间’, ‘较为简单’, ‘.’]

[(0, 2), (1, 3), (2, 3), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1), (24, 1)]
元组第一个元素为词语的编号(index),第二个为在本句中出现的次数
4).把评论变成词向量(可选的)
[(0, 2), (1, 3), (2, 3), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1), (24, 1)]

[2,3,3,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
省略编号,按顺序表示词语出现的次数
2.使用机器看的懂得算法轮询去比较每一条和所有评论的相似程度
TF-IDF
Corpus = [“我喜欢来中国旅游,中国很好玩”,
“这辆车在中国很受欢迎,我的工作就是在中国出售这辆车”,
“我喜欢喝茶和吃苹果”,
“这份工作是在科学杂志上发几篇论文”]
如何用TF-IDF寻找关键词:
- 不考虑停用词(就是没什么意义的词),找出一句话中出现次数最多的单词,来代表这句话,这个就叫做词频(TF – Term Frequency),相应的权重值就会增高
- 如果一个词在所有句子中都出现过,那么这个词就不能代表某句话,这个就叫做逆文本频率(IDF – Inverse Document Frequency)相应的权重值就会降低
- TF-IDF = TF * IDF
TF公式:

其中 ni,j是该词在一份文件(或评论)中出现的次数,分母则是一份文件(或评论)中所有词汇出现的次数总和
即:

IDF公式:


即:

分母之所以要加1,是为了避免分母为0
案例代码:
判断一句话和样本文档中每句话的相似度
文件:

执行结果(测试文本和前十句话的相似度从高到底排序):

# encoding=utf-8
"""
Date:2019-07-27 12:01
User:LiYu
Email:[email protected]
"""
import csv
import jieba
from gensim import corpora, models, similarities
count = 0
a = []
wordListTop10 = []
with open('./ChnSentiCorp_htl_all.csv', 'r') as f:
lines = csv.reader(f)
next(lines)
for line in lines:
if count == 10:
break
segList = list(jieba.cut(line[1])) # 分词
wordListTop10.append(segList)
count += 1
# print('/'.join(segList))
# print(a[0])
# for i in wordListTop10:
# print(i)
"""
制作词袋模型(bag_of_word (bow))
"""
# 制作字典
dictionary = corpora.Dictionary(wordListTop10)
# # 可以通过token2id得到特征数字
# print(dictionary)
# print(dictionary.keys())
# print(dictionary.token2id)
# print(dictionary.token2id.keys())
# # for i, j in dictionary.items():
# # print(i, j)
# 制作数字向量类型的语料库(doc2bow)----> 将字符串转换成数字向量类型的词袋模型
# 源文件不做处理是一个字符串类型的语料库
corpus = [dictionary.doc2bow(doc) for doc in wordListTop10]
# print(corpus)
def semblance(text, corpus):
# 分词
dic_text_list = list(jieba.cut(text))
# 制作测试文本的词袋
doc_text_vec = dictionary.doc2bow(dic_text_list)
# 获取语料库每个文档中每个词的tfidf值
tfidf = models.TfidfModel(corpus)
# print(tfidf[corpus[0]])
# 对每个文档,分析要测试文档的相似度
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))
sim = index[tfidf[doc_text_vec]]
# print("sim:", sim)
sim_sorted = sorted(enumerate(sim), key=lambda x: -x[1])
print(sim_sorted)
if __name__ == '__main__':
text = '商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!'
semblance(text, corpus)
情感分析
情感分类是指根据文本所表达的含义和情感信息将文本划分成褒扬或者贬义的两种或几种类型,是对文本作者情感倾向、观点或者态度的划分。
如何做情感分类呢?
要聊到一个东西叫做:分类
分类就是把已知的信息分到准备好的类别中
需要做的准备:分好类的数据集
当我们有了一定量的数据积累之后,最简单的想法就是:新来的数据集和哪个已知的数据相似,我们就认为他属于哪个类别
方法: 逻辑回归和KNN
本文我们用Python实现一下KNN算法,逻辑回归后文再讨论
# encoding=utf-8
"""
Date:2019-07-28 10:23
User:LiYu
Email:[email protected]
"""
import csv
import jieba
from gensim import corpora, models, similarities
from numpy import *
wordList = []
labels = []
count = 0
# 制作样本数据(样本数据数字化)
with open('./ChnSentiCorp_htl_all.csv', 'r') as f:
lines = csv.reader(f)
next(lines)
for line in lines:
if count == 100:
break
segList = list(jieba.cut(line[1])) # 分词
wordList.append(segList)
labels.append(line[0])
count += 1
# 制作字典
dictionary = corpora.Dictionary(wordList)
corpus = [dictionary.doc2bow(doc) for doc in wordList]
allWordNum = len(dictionary.token2id)
print(allWordNum)
groupList = [[0 for i in range(allWordNum)] for j in range(len(wordList))]
for i in range(len(corpus)):
for j in corpus[i]:
groupList[i][j[0]] = j[1]
# print(groupList[i])
# print(corpus)
# for i in range(len(groupList)):
# print(len(groupList[i]))
groupArray = array(groupList)
print(groupArray)
print(labels, len(labels))
def classify(inX, dataSet, labels, k):
# shape:输出数组的格式
dataSetSize = dataSet.shape[0] # (6,2)
# tile复制数组 e.g. [0,1], tile([0,1], (3,1)) -> [[0,1],[0,1],[0,1]]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # [[x1 - x2][y1 - y2]...]
print(diffMat)
sqDiffMat = diffMat ** 2 # [[x1 - x2]**2 [y1 - y2]**2...]
print(sqDiffMat)
# axis表示需要加和的维度
sqDistances = sqDiffMat.sum(axis=1) # (x1 - y1)**2 + (x2 - y2)**2....
print(sqDistances)
distances = sqDistances ** 0.5 # 开根号
print(distances)
# sortedDistIndicies 是一个排好序的index
sortedDistIndicies = distances.argsort() # 排序
print(sortedDistIndicies)
classCount = {}
for i in range(k): # 取距离最接近的前k个
voteIlabel = labels[sortedDistIndicies[i]]
print(voteIlabel)
# get是一个字典dict的方法,它的作用是返回key对应的value值,如果没有的话,返回默认值,就是下一行的0
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
print(classCount)
# sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
sortedClassCount = sorted(classCount.items(), key=lambda d: float(d[1]), reverse=True)
print(sortedClassCount)
return sortedClassCount
if __name__ == '__main__':
# text = '酒店环境差,饭也太难吃了,不推荐!'
text = '差评!!!'
textGroupList = [0 for i in range(allWordNum)]
textCorpus = dictionary.doc2bow(jieba.cut(text))
for i in textCorpus:
textGroupList[i[0]] = i[1]
result = classify(textGroupList, groupArray, labels, 3)
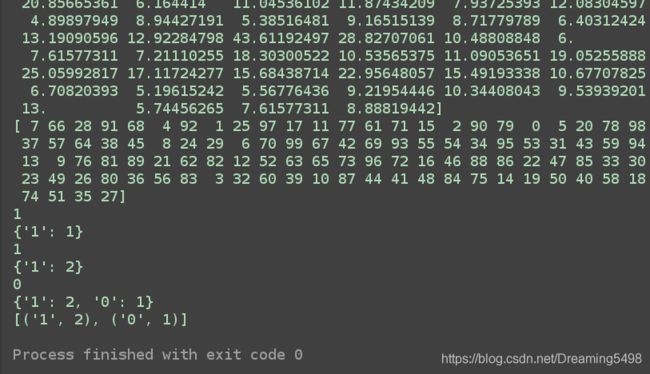
由于数据样本太少,结果并不准确,但是算法我们还是的实现了,后续再继续讨论优化的问题
对KNN感兴趣可以看一下这篇文章:https://blog.csdn.net/eeeee123456/article/details/79927128