Tensorflow2.0学习(19):Embedding——电影评论的情感分析
概述
- 将电影中评论中的某个句子的所有词变成对应的维度的embedding向量,然后将多个句子组合成batch送入神经网络,标签是句子所代表的正面或者负面的标签。
实战
- 前面同上一篇
- 对句子进行paddding
# 设置句子的长度,长度高于500的会被截断,长度低于500的会被补全
max_length = 500
train_data = keras.preprocessing.sequence.pad_sequences(
train_data,
# 填充值
value = word_index['' ],
# padding可取“post”和“pre”,post将padding放在句子后面,pre将放前面
padding = 'post',
maxlen = max_length)
test_data = keras.preprocessing.sequence.pad_sequences(
test_data,
value = word_index['' ],
padding = 'post',
maxlen = max_length)
print(train_data[0])
[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941
4 173 36 256 5 25 100 43 838 112 50 670 2 9
35 480 284 5 150 4 172 112 167 2 336 385 39 4
172 4536 1111 17 546 38 13 447 4 192 50 16 6 147
2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16
43 530 38 76 15 13 1247 4 22 17 515 17 12 16
626 18 2 5 62 386 12 8 316 8 106 5 4 2223
5244 16 480 66 3785 33 4 130 12 16 38 619 5 25
124 51 36 135 48 25 1415 33 6 22 12 215 28 77
52 5 14 407 16 82 2 8 4 107 117 5952 15 256
4 2 7 3766 5 723 36 71 43 530 476 26 400 317
46 7 4 2 1029 13 104 88 4 381 15 297 98 32
2071 56 26 141 6 194 7486 18 4 226 22 21 134 476
26 480 5 144 30 5535 18 51 36 28 224 92 25 104
4 226 65 16 38 1334 88 12 16 283 5 16 4472 113
103 32 15 16 5345 19 178 32 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
- 构建模型:每个句子都有500个词,每个词对应一个16维的向量,也就是每个句子对应的是50016的矩阵。组合成batch后就是128500*16的三维矩阵
# 将每个词变成长度为16的embedding向量
embedding_dim = 16
batch_size = 128
model = keras.models.Sequential([
# keras.layers.Embedding要做的几件事:
# 1.定义矩阵:[vocab_size, embedding_dim]
# 2.对于每一个句子/样本,如:[1,2,3,4...],都会取矩阵中查找对应的向量,最后变成成
# max_length * embeddding_dim的矩阵
# 3.最后输出的大小为一个三维矩阵:batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
# 对输出做合并
# 将三维矩阵变为:batch_size * embedding_dim
keras.layers.GlobalAveragePooling1D(),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation = 'sigmoid'),
])
model.summary()
model.compile(optimizer = 'adam', loss = 'binary_crossentropy',
metrics = ['accuracy'])
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 500, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 64) 1088
_________________________________________________________________
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 161,153
Trainable params: 161,153
Non-trainable params: 0
_________________________________________________________________
- 训练模型
history = model.fit(train_data,
train_labels,
epochs=30,
batch_size=batch_size,
validation_split=0.2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/30
20000/20000 [==============================] - 2s 110us/sample - loss: 0.6814 - accuracy: 0.6095 - val_loss: 0.6336 - val_accuracy: 0.7728
Epoch 2/30
20000/20000 [==============================] - 2s 85us/sample - loss: 0.5103 - accuracy: 0.8185 - val_loss: 0.4055 - val_accuracy: 0.8582
Epoch 3/30
20000/20000 [==============================] - 2s 85us/sample - loss: 0.3320 - accuracy: 0.8803 - val_loss: 0.3267 - val_accuracy: 0.8752
Epoch 4/30
20000/20000 [==============================] - 2s 85us/sample - loss: 0.2643 - accuracy: 0.9018 - val_loss: 0.2995 - val_accuracy: 0.8844
Epoch 5/30
20000/20000 [==============================] - 2s 116us/sample - loss: 0.2262 - accuracy: 0.9184 - val_loss: 0.2861 - val_accuracy: 0.8874
Epoch 6/30
20000/20000 [==============================] - 2s 118us/sample - loss: 0.2012 - accuracy: 0.9275 - val_loss: 0.2843 - val_accuracy: 0.8880
Epoch 7/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.1781 - accuracy: 0.9369 - val_loss: 0.2846 - val_accuracy: 0.8930
Epoch 8/30
20000/20000 [==============================] - 2s 116us/sample - loss: 0.1617 - accuracy: 0.9424 - val_loss: 0.2810 - val_accuracy: 0.8974
Epoch 9/30
20000/20000 [==============================] - 2s 118us/sample - loss: 0.1450 - accuracy: 0.9506 - val_loss: 0.2866 - val_accuracy: 0.8974
Epoch 10/30
20000/20000 [==============================] - 2s 116us/sample - loss: 0.1310 - accuracy: 0.9568 - val_loss: 0.2964 - val_accuracy: 0.8958
Epoch 11/30
20000/20000 [==============================] - 2s 114us/sample - loss: 0.1216 - accuracy: 0.9596 - val_loss: 0.3066 - val_accuracy: 0.8944
Epoch 12/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.1098 - accuracy: 0.9641 - val_loss: 0.3213 - val_accuracy: 0.8894
Epoch 13/30
20000/20000 [==============================] - 2s 111us/sample - loss: 0.0995 - accuracy: 0.9675 - val_loss: 0.3489 - val_accuracy: 0.8824
Epoch 14/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.0940 - accuracy: 0.9700 - val_loss: 0.3454 - val_accuracy: 0.8882
Epoch 15/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.0824 - accuracy: 0.9748 - val_loss: 0.3564 - val_accuracy: 0.8888
Epoch 16/30
20000/20000 [==============================] - 2s 112us/sample - loss: 0.0772 - accuracy: 0.9767 - val_loss: 0.3715 - val_accuracy: 0.8882
Epoch 17/30
20000/20000 [==============================] - 2s 114us/sample - loss: 0.0680 - accuracy: 0.9805 - val_loss: 0.3920 - val_accuracy: 0.8868
Epoch 18/30
20000/20000 [==============================] - 2s 113us/sample - loss: 0.0612 - accuracy: 0.9832 - val_loss: 0.4075 - val_accuracy: 0.8860
Epoch 19/30
20000/20000 [==============================] - 2s 116us/sample - loss: 0.0546 - accuracy: 0.9856 - val_loss: 0.4345 - val_accuracy: 0.8816
Epoch 20/30
20000/20000 [==============================] - 2s 113us/sample - loss: 0.0526 - accuracy: 0.9862 - val_loss: 0.4513 - val_accuracy: 0.8822
Epoch 21/30
20000/20000 [==============================] - 2s 113us/sample - loss: 0.0448 - accuracy: 0.9886 - val_loss: 0.4642 - val_accuracy: 0.8844
Epoch 22/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.0401 - accuracy: 0.9903 - val_loss: 0.4846 - val_accuracy: 0.8824
Epoch 23/30
20000/20000 [==============================] - 2s 113us/sample - loss: 0.0349 - accuracy: 0.9922 - val_loss: 0.5072 - val_accuracy: 0.8806
Epoch 24/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.0307 - accuracy: 0.9936 - val_loss: 0.5297 - val_accuracy: 0.8798
Epoch 25/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.0275 - accuracy: 0.9949 - val_loss: 0.5534 - val_accuracy: 0.8790
Epoch 26/30
20000/20000 [==============================] - 2s 115us/sample - loss: 0.0239 - accuracy: 0.9954 - val_loss: 0.5783 - val_accuracy: 0.8802
Epoch 27/30
20000/20000 [==============================] - 2s 122us/sample - loss: 0.0209 - accuracy: 0.9962 - val_loss: 0.6157 - val_accuracy: 0.8778
Epoch 28/30
20000/20000 [==============================] - 2s 125us/sample - loss: 0.0195 - accuracy: 0.9966 - val_loss: 0.6278 - val_accuracy: 0.8780
Epoch 29/30
20000/20000 [==============================] - 2s 114us/sample - loss: 0.0170 - accuracy: 0.9973 - val_loss: 0.6506 - val_accuracy: 0.8762
Epoch 30/30
20000/20000 [==============================] - 2s 116us/sample - loss: 0.0150 - accuracy: 0.9980 - val_loss: 0.6712 - val_accuracy: 0.8756
def plot_learning_curves(history, label, epochs, min_value, max_value):
data = {}
data[label] = history.history[label]
data['val_' + label] = history.history['val_' + label]
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
plot_learning_curves(history, 'accuracy', 30, 0, 1)
plot_learning_curves(history, 'loss', 30, 0, 1)

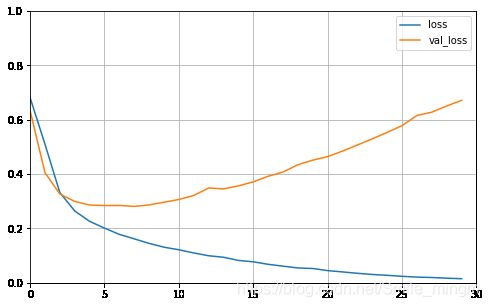
可以看出验证集存在过拟合。
- 测试
model.evaluate(
test_data, test_labels,
batch_size = batch_size)
25000/25000 [==============================] - 0s 10us/sample - loss: 0.7317 - accuracy: 0.8566
[0.7316589960098266, 0.85664]