终于有一本可以让初学者全面了解分布式系统设计的书啦
今天,对于在IT行业从事技术工作的人,无论是工程师、架构师还是管理者,也无论从事的工作是否与分布式相关,都应该了解分布式技术,因为总有一天,你会遇到它、接触它、使用它、理解它、完善它。
然而,分布式技术涉及的方面(存储、计算、框架、中间件等)是如此之多,且迄今为止尚未见到一本书对其进行概括和梳理,要想对分布式技术有全面的了解,特别是对初学者而言,何其难哉!
如今初学者再不用学习分布式技术而发愁了,刚好有这样一本适用初学者的《分布式系统设计实践》出版,作者李庆旭 。
【京东购买】【当当购买】
本书试图对近年来涌现出的各种主流分布式技术做一个简要介绍,以使不太熟悉这个领域的读者能了解其概貌、原理和根源。
本书共分为以下6部分。
第一部分对典型的分布式系统的组成及其中每个组件的功能进行简要介绍,以使读者对分布式系统有一个总体了解。
第二部分介绍分布式系统的前端经常使用的Web框架、反向代理及负载均衡技术。
第三部分对分布式系统中经常使用的各种中间件技术逐一进行介绍,包括分布式同步服务中间件、关系型数据库访问中间件、分布式服务调用中间件、分布式消息服务中间件和分布式跟踪服务中间件。
第四部分介绍分布式文件系统、各种NoSQL数据库技术(基于键值对的NoSQL技术、基于列的NoSQL技术、基于文档的NoSQL技术、基于图的NoSQL技术)和NewSQL数据库系统。
第五部分对业界在构建大型分布式系统的过程中的主要经验加以总结,使后来者避免重蹈覆辙。
第六部分介绍业界几个知名的大型分布式系统的主要设计思想和架构,包括谷歌搜索系统、淘宝网、阿里云和领英的社交应用。此外,还会探讨和思考分布式系统实现中的一些问题。
主体目录
- 第一部分 分布式系统概述 免费
- 第1章 分布式系统概述 免费
- 第二部分 分布式系统的前端构造技术 免费
- 第2章 Web框架的实现原理
- 第3章 反向代理与负载均衡
- 第三部分 分布式中间件
- 第4章 分布式同步服务中间件
- 第5章 关系型数据库访问中间件
- 第6章 分布式服务调用中间件
- 第7章 分布式消息服务中间件
- 第8章 分布式跟踪服务中间件
- 第四部分 分布式存储技术
- 第9章 分布式文件系统
- 第10章 基于键值对的NoSQL数据库
- 第11章 基于列的NoSQL数据库
- 第12章 基于文档的NoSQL数据库
- 第13章 其他NoSQL数据库
- 第14章 NewSQL数据库
- 第五部分 分布式系统的构建思想
- 第15章 云化
- 第16章 分布式系统的构建思想
- 第六部分 大型分布式系统案例研究及分析
- 第17章 大型分布式系统案例研究
- 第18章 关于分布式系统设计的思考
适合读者群
本书适合业界的架构师、工程师、项目经理,以及大中专院校的高年级本科生和研究生使用和参考。
样章试读:
第1章 分布式系统概述
1999年8月6日,CNN报道了一起eBay网站的事故:从7:30开始,整个网站崩溃,一直持续了9个多小时。下午5:30后,技术人员开始进行系统恢复,但搜索功能依然不能使用。
2011年4月21日至22日,亚马逊EC2(Elastic Computer Cloud)服务出现大面积事故,导致数以千计的初创公司受到影响,而且造成大约11小时的历史数据永久性丢失。
2013年4月27日,《大掌门》游戏的开发商玩蟹科技CEO叶凯在微博上吐槽,“我们在阿里云上用了20多台机器。半年时间,出现过1次所有机器全部断电,2次多个硬盘突然只读,3次硬盘I/O突然变满……”。
2013年12月28日,春运第一天,铁道部首次推出了网上订票系统,但很快就出现许多用户无法访问、响应缓慢甚至串号等事故。
2017年9月17日,谷歌的网盘服务Drive出现故障,成千上万用户受到影响。
上面的这几起事故,当时都闹得沸沸扬扬,不仅给受影响的用户带来了很大的损失,也极大地影响了厂商的形象。事实上,几乎每一家互联网公司的后台系统都曾经不止一次地经历过这样或那样的尴尬时刻。可以这样说,几乎每一家互联网公司的后台架构都是在发现问题、解决问题的循环中发展起来的。
即便是执分布式系统技术牛耳的谷歌,在2017年9月,也出现过分布式系统的故障。可见,开发并维护一个成功的分布式系统是多么不易!
最早得到广泛应用的分布式系统是诞生于20世纪70年代的以太网。尽管分布式系统存在的历史已经有近半个世纪,然而其大规模的发展和应用则是2000年以后的事情。
21世纪以来,随着雅虎、谷歌、亚马逊、eBay、Facebook、Twitter等众多互联网公司的崛起,其用户量以及要处理的数据量迅速增长,远远超过了传统的计算机系统能够处理的范围,因此,以谷歌为代表的互联网公司提出了许多新技术(如HDFS、Bigtable、MapReduce等)。以BAT为代表的中国互联网公司,也在21世纪整体崛起,在初期借鉴美国公司技术的基础上,他们也自行开发了许多新的技术(如淘宝的管理海量小文件的分布式存储系统TFS、阿里巴巴开源的分布式调用框架Dubbo、阿里巴巴开源的数据库中间件Cobar等)。
为了解决分布式系统中的各种各样的问题,各大互联网公司开发了各种各样的技术,当然,这也促进了当今分布式系统技术领域的飞速发展。为了存储大量的网站索引,谷歌设计了GFS分布式文件存储系统和基于列存储的Bigtable NoSQL数据库系统;为了计算PageRank算法中的页面rank值,谷歌又设计了MapReduce分布式计算系统;为了方便其分布式系统中不同主机间的协调,谷歌还设计了Chubby分布式锁系统;为了解决不同语言实现的组件间的通信问题,Facebook设计了Thrift;为了解决大量消息的快速传递问题,领英设计了Kafka……这个列表可以很长很长。
为了“压榨”分布式系统中每个组件的性能,人们已经不再仅仅满足于在程序库(如网络编程库Netty、内存管理库TCMalloc等)、程序框架(如Spring)等“略显浅薄”的地方提高,而是已经渗透到了硬件(如谷歌为其计算中心专门设计了计算机)、网络(如SDN)、操作系统(如各大互联网公司定制的Linux内核)、语言(如谷歌设计的Go语言)、数据库系统(如各种NoSQL系统)、算法(如人工智能领域的突飞猛进)等各种计算机基础领域。
毫无疑问,我们处于计算机技术发展最为迅猛的时代。在这个如火如荼的时代里,许多尘封多年的计算机技术(如人工智能、分布式系统、移动计算、虚拟计算等),一改往日不温不火的模样,在互联网这片广袤的土地上如日中天,发展迅速。
今天的计算机领域,已经与20年前大为不同。20年前,只需要对操作系统、数据库、网络、编译等领域有深刻的理解,再熟练掌握几门计算机语言,了解一些常见的软件架构(客户服务器架构、管道架构、分层架构等)和软件工程(主要是瀑布模型)的知识,基本上就能胜任大多数软件开发工作了。而今天,仅了解这些基础知识已经远远不够,因为在近20年内,人类创造了太多的新技术,而这些新技术又大都起源并服务于分布式计算领域。
1.1 分布式系统的组成
一个大型的分布式系统虽然非常复杂,但其设计目标却往往是非常简单的,例如,京东和淘宝这样的电商,其设计目标是卖东西;谷歌和百度这样的搜索引擎,其设计目标是帮助大家在网上找相关的内容;Facebook和微信这样的社交应用,其设计目标是方便大家相互联系并分享自己生活中的点点滴滴。
如前文所述,之所以需要有分布式系统,最根本的原因还是单机的计算和存储能力不能满足系统的需要。但要把成百上千台计算机组织成一个有机的系统,绝非易事。在人类社会中,其实也一样,找到1000个人容易,但要把这1000个人组织成一只能战斗的军队可就没那么简单了。
一个典型的分布式系统如图1-1所示。
- 分布式系统大都有一个Web前端,用户可以通过浏览器随时随地访问,当然,前端也可以是运行在Windows/Linux上的桌面程序或者运行在手机上的应用。
- 分布式系统还要有后端支撑。分布式系统的后端大都是基于Linux的集群[1]。之所以采用Linux,一是因为开源操作系统成本低,二是因为开源软件可以定制。
- 就像人类社会需要有一定的组织和管理一样,为了组成一个集群,在单机的操作系统之上,还需要集群管理系统。在集群管理系统中,一个非常重要的组件是分布式协调组件,用来协调不同机器之间的工作。这些协调系统大都基于一些著名的分布式一致性协议(如Paxos、Raft等)。有些超大型的后端还拥有专门的集群操作系统,这些系统不仅有分布式协调功能,还有资源的分配与管理功能。
- 为了满足大规模数据的存储需要[2],需要有能够存储海量数据的后端存储系统。
- 为了满足大规模数据的计算需要[3],还需要有能够分析海量数据的后端计算系统。
图1-1 一个典型的分布式系统
- 在分布式系统中,有很多共性的功能,例如能够支持分库分表的数据库访问中间件、用来异步化的消息中间件、用来开发不同组件的分布式系统调用中间件、用来监控各个组件状态的分布式跟踪中间件等。事实上,前面所列举的每一种中间件,也都是一个复杂的分布式系统。
本章下面的内容先就后端最重要的分布式协调组件、后端存储系统和后端计算系统做一个概要的介绍。
1.2 分布式协调组件
分布式系统之所以存在,最根本的原因是数据量或计算量超过了单机的处理能力,因此不得不求助于水平扩展[4],而为了协调多个节点的动作,则不得不引入分布式协调组件。
在单机操作系统中,几个相互合作的进程(如生产者/消费者模型中的生产者进程和消费者进程),如果需要进行协调,就得借助于一些进程间通信机制,如共享内存、信号量、事件等。分布式协调组件提供的功能,本质上就是分布式环境中的进程间通信机制。
也许,有人会觉得这有何难,用一个数据库不就解决了吗?如代码清单1-1所示,将分布式锁信息保存在一张数据库表中(假如表名叫LOCK_TABLE),增加一个锁就是向LOCK_TABLE表中添加一新行(假如该行ID为MYCLOCK1),要获得该锁,只需要将MYCLOCK1行的某个字段(如LOCK_STATUS)置为1;要释放该锁,只需要将此字段置为0。利用数据库本身的事务支持,这个问题不就解决了吗?
代码清单1-1 利用数据库实现分布式锁
1. ' 获得锁2. START TRANSACTION;3. UPDATE LOCK_TABLE4. SET LOCK_STATUS = 1, LOCK_OWNER="process1"5. WHERE ID="MYCLOCK1" AND LOCK_STATUS=0;6. COMMIT;7. 调用者检查LOCK_OWNER字段是否为"process1",即可获知是否加锁成功8. ' 释放锁9. START TRANSACTION;10. UPDATE LOCK_TABLE11. SET LOCK_STATUS = 0, LOCK_OWNER=""12. WHERE ID="MYCLOCK1" AND LOCK_STATUS=1 AND LOCK_OWNER="process1";13. COMMIT;
然而,事情远没有那么简单。在分布式环境中,节点/网络故障为常态,如果采用代码清单1-1所示的方案,假如数据库所在的节点宕机了,整个系统就会陷入混乱。因此,这种有单点故障的方案肯定是不可取的。
分布式协调组件对外提供的是一种分布式同步服务。为了获得健壮性,一个协调组件内部也是由多个节点组成的,节点[5]之间通过一些分布式一致性协议(如Paxos、Raft)来协调彼此的状态。如果一个节点崩溃了,其他节点就自动接管过来,继续对外提供服务,好像什么都没有发生过一样。
另外,为了应用程序的方便,分布式协调组件经常还会允许在其上存放少量的信息(如主服务器的名称),这些信息也是由分布式一致性协议来维护其一致性的。
1.3 分布式存储系统
与单机系统类似,分布式系统的存储也分为两个层次:第一个层次是文件级的,即分布式文件系统,如GFS(Google File System)、HDFS(Hadoop Distributed File System)、TFS(Taobao File System)等;第二个层次是在文件系统之上的进一步抽象,即数据库系统。不过,分布式系统下的数据库远比单机的关系型数据库复杂,因为数据被存储在多个节点上,如何保证其一致性就成了关键,所以,分布式系统下的数据库采用的大都是最终一致性[6],而非满足ACID[7]属性的强一致性。
由于对一致性支持的不同,传统的ACID理论就不再适用了,于是,Eric Brewer提出了一种新的CAP[8]理论。CAP理论听起来高大上,但实际上并没有那么复杂。它的意思是,在分布式系统里,没有办法同时达到一致性、可用性和网络分区可容忍性,只能在三者中择其二。
不过,要注意CAP中的C和A与ACID中的C和A的含义是不同的(如表1-1所示),网络分区可容忍性的含义较为晦涩,是指一个分布式系统中是否允许出现多个网络分区。换言之,如果网络断了,一个系统中的多个节点被分成了多个孤岛,这允许吗?如果允许,就满足网络分区可容忍性,否则就不满足。
表1-1 CAP与ACID中的C和A的不同
| 属性 | CAP | ACID |
|---|---|---|
| C | 英文是consistency,指数据不同副本(replica)之间的一致性 | 英文也是consistency,但指数据库的内容处于一致的状态,如主键与外键的一致性 |
| A | 英文是availability,指系统的可用性 | 英文是atomicity,指事务的原子性 |
对于CAP理论,其实很好理解。我们可以想一想,如果需要满足网络分区可容忍性,即允许孤岛的存在,那么当孤岛产生时,只能要么继续提供服务(即满足可用性),要么停止服务(即满足一致性),其他的情况也类似。然而,在分布式系统中,由于孤岛的不可避免性,因此实际的系统只能在一致性和可用性中选择其一,即只能是满足一致性和网络分区可容忍性或者满足可用性和网络分区可容忍性的系统。
采用最终一致性的数据库系统,统称为NoSQL(Not only SQL)系统。根据数据模型的不同,NoSQL系统又分为以下几大类:
- 基于键值对的(如Memcached、Redis等);
- 基于列存储的(如谷歌的Bigtable、Apache HBase、Apache Cassandra等);
- 基于文档的(如MongoDB、CouchDB等);
- 基于图的(如Neo4j、OrientDB等)。
近几年,还涌现出一类称为NewSQL的系统(如谷歌的Megastore、谷歌的Spanner、阿里巴巴的OceanBase和PingCAP TiDB),号称既满足关系型数据库的ACID属性,又可以如NoSQL系统那般水平伸缩。然而,这些系统本质上还是满足最终一致性的NoSQL系统,只不过,它们将可用性和一致性处理得非常好,在外界看来,似乎同时满足了可用性和一致性,实则只是在实现上做了“手脚”,将不一致性“隐藏”起来,并将其“默默”地消化掉。
例如,谷歌Megastore将同一数据的不同分区存放在不同的数据中心中,在每个数据中心内部,属于同一个分区的数据存放在同一个Bigtable中。借助于Bigtable对单行数据读写的事务支持,Megastore支持同一个分区内的ACID属性,但对于跨分区(即跨数据中心)的事务,则通过两阶段提交实现,因此,也是最终一致的。
再如阿里巴巴的OceanBase,它将数据分为两部分,一部分是较早的数据(称为基准数据),另一部分是最新的数据(称为增量数据),基准数据与增量数据分开存储,读写请求都由一个专门的合并服务器(Merge Server)来处理。合并服务器解析用户的SQL请求,然后生成相应的命令发给存储基准数据和增量数据的服务器,再合并它们返回的结果;此外,后台还定期将增量数据合并到基准数据中[9]。OceanBase定期将更新服务器(Update Server)上的增量数据合并到各个数据块服务器(Chunk Server)中。因此,OceanBase也是最终一致的,但通过合并服务器把暂时的不一致隐藏起来了。
因此,本质上,只有两种数据库系统,即满足ACID属性的RDBMS和满足最终一致性的NoSQL系统。所谓的NewSQL,只不过是披着SQL系统外衣(即SQL支持和ACID属性)的NoSQL系统而已。
1.4 分布式计算系统
分布式存储系统只解决了大数据的存储问题,并没有解决大数据的计算问题。当计算量远远超过了单机的处理能力后,该怎么办呢?一种方式是各自开发专属的分布式计算框架,但这些计算框架很难做到通用和共享。因此,在不同公司或同一公司的不同团队中,存在着各种各样的分布式计算框架,造成了很大的浪费,而且框架的质量也良莠不齐。
1.4.1 批处理分布式计算系统
谷歌公司于2004年发表的MapReduce论文几近完美地解决了这个问题。MapReduce通过下面两个看似简单却包含了深刻智慧的函数,轻而易举地解决了一大类大数据计算问题。
{-:-}map (<K1, V1>) → list(<K2, V2>)[10]
{-:-}reduce (<K2, list(V2)>) → list(V3)[11]
如图1-2所示,使用MapReduce解决问题的步骤如下。
(1)需要将输入表示成一系列的键值对<K1, V1>。
(2)定义一个map函数,其输入是上一步的一个键值对<K1, V1>,其输出则是另一种键值对<K2, V2>的列表。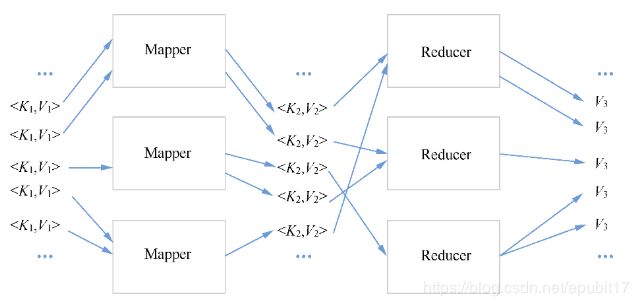
图1-2 MapReduce工作原理
(3)运行时,MapReduce框架会对每一个输入的键值对<K1, V1>调用map函数(执行map函数的机器称为Mapper),并生成一系列另一种键值对<K2, V2>。然后,MapReduce框架会根据K2进行分区(partition),即根据K2的值,将<K2, V2>对在多个称为Reducer(即执行reduce函数的机器)的机器间进行分发。
(4)还需要定义一个reduce函数,该函数的输入是一系列K2和与其对应的V2值的列表,输出是另一种值V3的列表。
(5)运行时,MapReduce框架会调用reduce函数,由reduce函数来对同一个K2的V2的列表进行聚合。
MapReduce本质上是一种“分而治之”的策略,只不过数据规模很大而已。它首先把全部输入分成多个部分,每部分启动一个Mapper;然后,等所有Mapper都执行完后,将Mapper的输出根据K2做分区,对每个分区启动一个Reducer,由Reducer进行聚合。
MapReduce看似简单,却能够解决一大类问题。MapReduce能够解决的问题具有下列特征。
- 需要一次性处理大批的数据,而且在处理前数据已经就绪,即所谓的批处理系统。
- 数据集能够被拆分,而且可以独立进行计算,不同的数据集之间没有依赖。例如,谷歌的PageRank算法的迭代实现,每一次迭代时,可以把数据分为不同的分区,不同分区之间没有依赖,因此就可以利用MapReduce实现。但斐波那契数列的计算问题则不然,其后面值的计算必须要等前面的值计算出来后方可开始,因此就不能利用MapReduce实现。
- 计算对实时性要求不高。这是因为MapReduce计算的过程非常耗时。
1.4.2 流处理分布式计算系统
对于那些不断有新数据进来,而且对实时性要求很高的计算(如实时的日志分析、实时的股票推荐系统等),MapReduce就不适用了。于是,流处理系统应运而生。
根据对新数据的处理方式,流处理系统分为以下两大类。
- 微批处理(micro-batch processing)系统:当新数据到达时,并不立即进行处理,而是等待一小段时间,然后将这一小段时间内到达的数据成批处理。这类系统的例子有Apache Spark。
- 真正的流处理(true stream processing)系统:当一条新数据到达后,立刻进行处理。这类系统的例子有Apache Storm、Apache Samza和Kafka Streams(只是一个客户端库)。
1.4.3 混合系统
在分布式计算领域,还有一种混合了批处理和流处理的系统,这类系统的一个例子是电商的智能推荐系统,其既需要批处理的功能(为了确保响应速度,预先将大量的计算通过批处理系统完成),也需要流处理的功能(根据用户的最新行为,对推荐系统进行实时调整)。
对于这类系统,有一种很流行的架构,即Lamda架构(如图1-3所示),其思想是用一个批处理系统(如MapReduce)来进行批处理计算,再用一个实时处理系统(如Apache Spark/Storm)来进行实时计算,最后用一个合并系统将二者的计算结果结合起来并生成最终的结果。

图1-3 Lamda架构
对于混合系统的实现,有篇非常有趣的文章值得一读,“Questioning the Lambda Architecture”一文中提到了Lamda架构的一个很大的缺点,即处理逻辑需要在批处理系统和流处理系统中实现两遍。该文提到了一种新的混合系统实现方式,即利用Kafka可以保存历史消息的特性,根据业务的需要,在Kafka中保存一定时间段内的历史数据,当需要进行批处理时,则访问Kafka中保存的历史数据,当需要实时处理时,则消费Kafka中的最新消息。如此这般,处理逻辑就只需要实现一套了。感兴趣的读者,可以读一读此文。
1.5 分布式系统中节点之间的关系
一个人类社会的组织,要想实现其组织功能,组织内的人需要按照某种方式被组织起来,例如,有的人负责管理,有的人负责执行,等等。由许多节点组成的分布式系统也一样,系统中的节点也需要被有机地组织起来,才能实现想要完成的功能。也就是说,有些节点需要承担这样的角色,而另一些节点则需要承担另外的角色。根据所承担角色的不同,节点之间的关系不外乎下面两种。
- 主从式(master-slave)关系:主节点集大权于一身,所有重要的信息都存储在主节点上,所有重要的决定也都由主节点做出。这类系统的例子有谷歌的GFS和Bigtable等,以及受其架构影响而开发的其他系统(如HDFS、HBase、淘宝TFS、京东JFS、百度BFS、百度Tera等)。
- 对等式(peer-to-peer)关系:这类系统中的节点之间的关系是平等的,没有中心节点,而是采用设置好的选举与协调规则来处理节点之间的协调问题,这类系统的典型代表是亚马逊的Dynamo,以及受其架构影响而开发的其他系统(如Cassandra、Riak等)。
相对而言,主从式系统实现起来要简单些,而对等式系统实现起来则困难些。
[1] 所谓集群,是指采用同样或类似配置的许多台机器,为了达到一个共同的目的而组成的系统。
[2] 像谷歌和百度这样的公司,因为索引的页面量非常庞大,需要很大的存储空间。微信和Facebook这样的社交应用亦然。
[3] 例如谷歌,其PageRank算法就需要很大的计算量;再如京东和淘宝这样的电商,其商品推荐系统也需要很大的计算量。
[4] 水平扩展(scale out)与垂直扩展(scale up)是一对相对的概念,前者是指通过增加额外的节点来扩展系统的处理能力,后者则指通过升级单个节点的硬件(CPU、内存、磁盘)来进行扩展。
[5] 节点与机器可以是物理的实体(即物理机器),也可以是虚拟的实体(如虚拟机、Docker容器)在本书中这两个概念在本书中不加区别,常互换使用。
[6] 最终一致性即在“有穷”的时间内,各个节点上的数据最终会收敛到一致的状态,当然这里的“有穷”经常是指很短暂的时间,几分或几秒就算比较长的了。
[7] ACID指的是原子性(Atomicity)、一致性(Consistency)、独立性(Isolation)和持久性(Durability)。
[8] CAP指的是一致性(Consistency)、可用性(Availability)和网络分区可容忍性(Tolerance to Network Partitions)。
[9] 阿里巴巴的OceanBase的这种实现方式实际上就是所谓的Lamda架构。
[10] map函数的功能是将输入的键值对映射成一个新的键值对列表。
[11] reduce函数的功能是将一个键和一个值的列表映射成一个新的值的列表。