python 爬取菜单生成菜谱,做饭买菜不用愁
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:木下瞳
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http://t.cn/A6Zvjdun
前几天小编在家当主厨,从买菜到端上桌的全部流程都有小编操办,想着就弄一些简单一些的菜,就没有多想,可当小编去到超市站在一堆菜的面前却不知所措了,看着花花绿绿,五颜六色的菜不知道买什么,做什么菜。
于是小编突发奇想,自己丰衣足食,弄一个菜谱生成器,随机生成 “三菜一汤”,完美解决买菜难的问题~
项目简介
从 “下厨房” 爬取【家常菜】【快手菜】【下饭菜】【汤羹】四类菜品中的最近流行的,保存在 csv 文件,制作一个界面,随机生成三菜一汤的菜谱,菜谱包含菜名,食材,评分,教程链接,并在界面中显示食材词云,用户可重复,可多次生成菜谱:
http://www.xiachufang.com/
结果展示
运行 ui_support.py 文件:
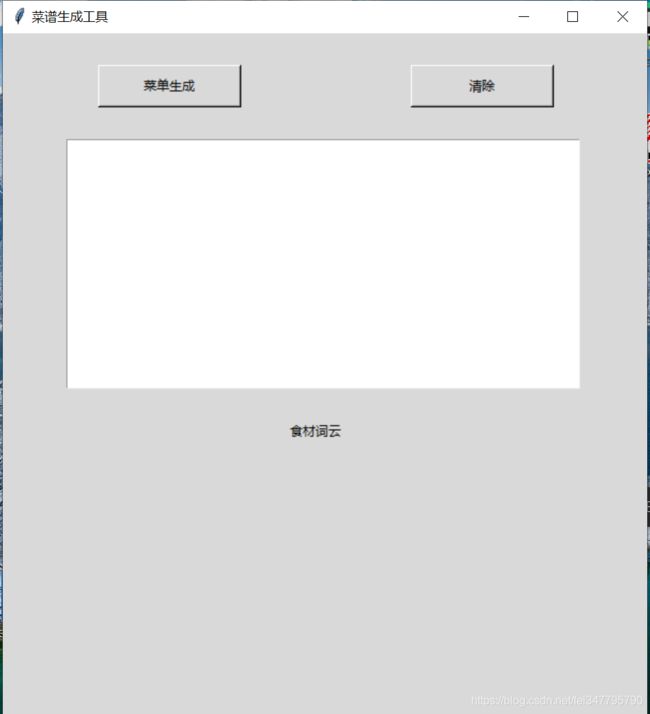

要是不满意,还可以点击【清除】按钮,继续重新生成噢~
知识点
从本项目中,你可以学到以下知识:
1.爬虫的基本流程
2.xpath 提取数据
3.创建,写入,读取 csv
4.pandas 随机选择数据 sample()
5.DateFrame 转为 List
6.ui 生成工具 page 的使用
7.根据生成 ui 代码,添加事件触发逻辑
8.词云制作
项目流程
在项目文件中有一个 read.txt 文件,里面也有说明项目的模块划分。
spider.py 为爬虫文件,爬取我们需要的数据,逻辑为:创建 csv,创建 url 后遍历访问,提取数据,写入 csv。
在获得的 csv 有一个问题,打开看会是乱码,设置为 utf8,gbk 都不能正常在 wps 显示,但用 txt 打开是正常显示,经过测试,在 ui 界面显示也正常,这是因为在食材中有一些表情字符,获得后的 csv 不需要任何处理:
接下来制作 ui 界面,使用了 page 工具来生成界面代码,关于这个工具安装配置参考:
Python 脚本 GUI 界面生成工具
小编这里是设计好的,就再简单介绍一下:
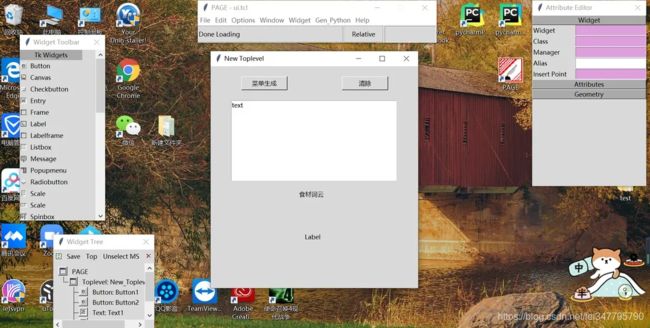
从左侧 “Widget Toolbar” 控件栏,选择相应控件到中间窗口即可,对于按钮控件,我们需要添加触发命令,点击 “生成菜单” 就会运行相应逻辑。
选中 “菜单生成” 控件,再选中 “Attribute Editor” 栏的 “Attribute” ,在 “command” 写入触发函数名,“text” “tooltip” 分别为文本显示,提示标签:
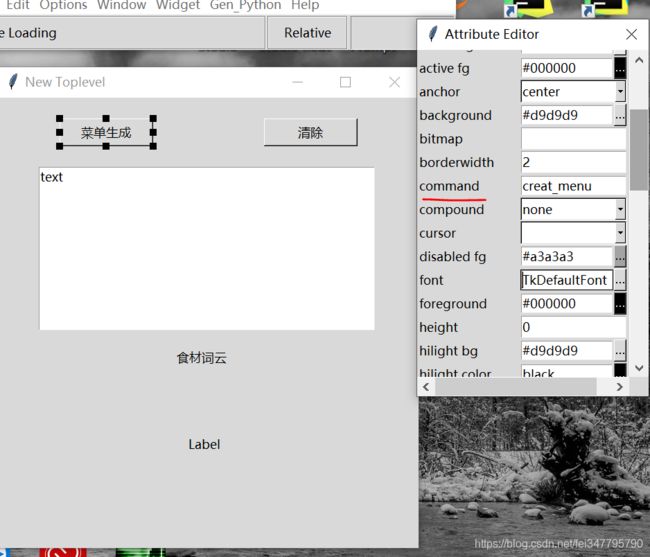
设计好后,先保存,小编的保存文件名为 ui,它是保存为 ui.tcl 文件,现在把界面代码也保存:
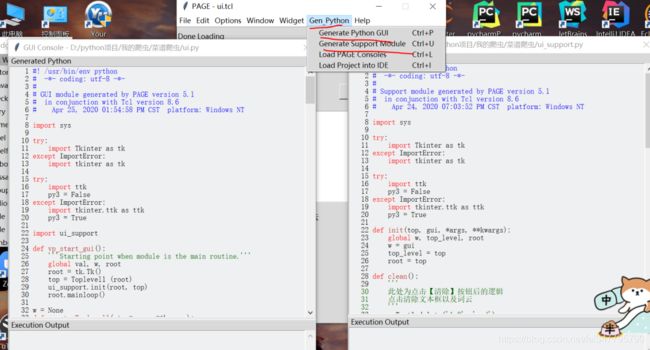
分别点击 “Save” 保存这两个文件,会保存在与 ui.tcl 的同一目录。
“python GUI” 是界面逻辑,保存后的文件名为 ui.py,不需要动。
“Support Module” 是触发事件代码,我们相应的逻辑就是在这里面添加:
打开 ui_support.py ,找到设置的 “command”,即为函数名:
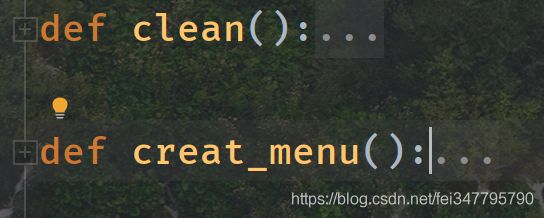
clean 函数为点击【清除】按钮后,把文本框清除:

creat_menu 函数为点击【生成菜谱】按钮后的逻辑,从 csv 中随机抽取三菜一汤显示在文本框,显示词云在标签栏。
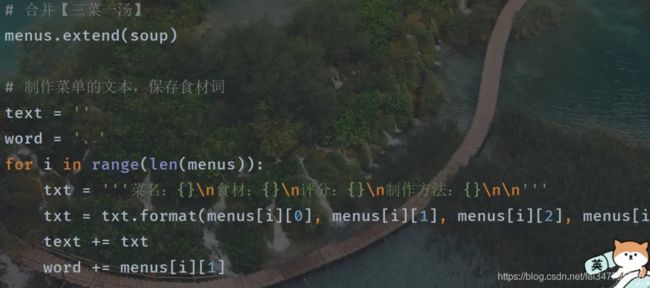
其主要为:读取 csv,DataFrame 转化为 list,合并【三菜一汤】,制作菜单的文本,保存食材词,菜单文本框插入,词云生成,插入词云:

这样所有逻辑都完成了,运行 ui_support.py 即可开始菜谱生成啦~
完整代码
spider.py
import requests
import csv
from lxml import etree
from fake_useragent import UserAgent
def create_csv():
'''
创建 foods.csv, soups.csv
'''
head = ['name','food','score','link']
csvs = ['foods.csv','soups.csv']
for c in csvs:
with open(c,'w',encoding='gbk',newline='') as f:
writer = csv.writer(f)
writer.writerow(head)
def get_html(url,kind):
'''
请求 html
'''
headers = {
'User-Agent' : UserAgent().random,
'Cookie' : 'bid=SUKKdKjF; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22171a785835191-0292964d820ab7-4313f6a-921600-171a78583520%22%2C%22%24device_id%22%3A%22171a785835191-0292964d820ab7-4313f6a-921600-171a78583520%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; __utmz=177678124.1587653477.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __gads=ID=e0150cd671284025:T=1587653477:S=ALNI_Mbm6h5yX4RCMFDKDV9SBCRwZXLwFg; Hm_lvt_ecd4feb5c351cc02583045a5813b5142=1587653477,1587700573; __utma=177678124.702716191.1587653477.1587653477.1587700573.2; __utmc=177678124; __utmb=177678124.44.10.1587700573; Hm_lpvt_ecd4feb5c351cc02583045a5813b5142=1587703641',
'Host' : 'www.xiachufang.com',
'Referer' : kind.split('?')[0]
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response
else:
return
def get_infos(response):
'''
提取数据
'''
infos = []
html = etree.HTML(response.text)
menus = html.xpath('//ul[@class="list"]/li')[:20]
for menu in menus:
name = menu.xpath('./div/div/p[1]/a/text()')[0].replace('\n','').replace(' ','')
food = menu.xpath('./div/div/p[@class="ing ellipsis"]')[0]
food = food.xpath('string(.)').replace('\n','').replace(' ','')
score = menu.xpath('./div/div/p[3]/span[1]/text()')[0]
link = menu.xpath('./div/div/p[1]/a/@href')[0]
link = 'http://www.xiachufang.com' + link
infos.append([name,food,score,link])
return infos
def write_to_csv(infos,file):
'''
写入 csv
'''
with open(file,'a+',encoding='utf8',newline='') as f:
writer = csv.writer(f)
for info in infos:
writer.writerow(info)
if __name__ == '__main__':
count = 1
create_csv()
kind_urls = ['http://www.xiachufang.com/category/40076/',
'http://www.xiachufang.com/category/40077/',
'http://www.xiachufang.com/category/40078/',
'http://www.xiachufang.com/category/20130/']
for kind in kind_urls:
kind += '?page={}'
urls = [kind.format(str(i)) for i in range(1,12)]
for url in urls:
response = get_html(url,kind)
if response == None:
continue
infos = get_infos(response)
# 判断是否为【汤羹】url,写入对应的 csv
if '20130' not in url:
file = 'foods.csv'
else:
file = 'soups.csv'
write_to_csv(infos,file)
print('已爬取 %d 页菜谱' % count)
count += 1
ui_support.py
#! /usr/bin/env python
# -*- coding: utf-8 -*-
#
# Support module generated by PAGE version 5.1
# in conjunction with Tcl version 8.6
# Apr 24, 2020 07:03:52 PM CST platform: Windows NT
import sys
try:
import Tkinter as tk
except ImportError:
import tkinter as tk
try:
import ttk
py3 = False
except ImportError:
import tkinter.ttk as ttk
py3 = True
def init(top, gui, *args, **kwargs):
global w, top_level, root
w = gui
top_level = top
root = top
def clean():
'''
此处为点击【清除】按钮后的逻辑
点击清除文本框以及词云
'''
w.Text1.delete('1.0', 'end')
sys.stdout.flush()
def creat_menu():
'''
此处为点击【生成菜谱】按钮后的逻辑
从 csv 中随机抽取三菜一汤
显示在文本框
显示词云在标签栏
'''
import pandas as pd
import numpy as np
import wordcloud
menu_df = pd.read_csv('foods.csv', encoding='utf8')
soup_df = pd.read_csv('soups.csv', encoding='utf8')
# DataFrame 转化为 list
menus = menu_df.sample(3)
menus = np.array(menus)
menus = menus.tolist()
soup = soup_df.sample()
soup = np.array(soup)
soup = soup.tolist()
# 合并【三菜一汤】
menus.extend(soup)
# 制作菜单的文本,保存食材词
text = ''
word = '、'
for i in range(len(menus)):
txt = '''菜名:{}\n食材:{}\n评分:{}\n制作方法:{}\n\n'''
txt = txt.format(menus[i][0], menus[i][1], menus[i][2], menus[i][3])
text += txt
word += menus[i][1]
# 菜单文本框插入
w.Text1.insert('insert',text)
# 词云生成
word = word.replace('、', ' ')
wd = wordcloud.WordCloud(background_color='white',
width=478, height=181,
font_path='msyh.ttc',
)
wd.generate(word)
wd.to_file('foods.png')
# 插入词云
img = tk.PhotoImage(file='foods.png')
w.Label1.configure(imag=img).pack()
sys.stdout.flush()
def destroy_window():
# Function which closes the window.
global top_level
top_level.destroy()
top_level = None
if __name__ == '__main__':
import ui
ui.vp_start_gui()