Hadoop1.2.1详细配置与相关问题讲解
新手,折腾了一天,终于把Hadoop伪分布式配置好了,下面讲解所有流程以及我遇到的一些问题的解决方法。
配置环境准备
hadoop-1.2.1 --> HDFS
伪分布式配置-->1个NameNode节点,2个DateNode节点,1个SeconaryNode节点部署在3个虚拟机上
系统-->VMWARE CentOS7.0(node1、node2、node3)
系统准备
首先在虚拟机上安装CentOS7.0系统,当然版本无所本,为方便协调,我们在安装过程中把主机名设置为node1、node2、node3,并且不设置用户,直接root用户。
在此说明一下为什么不设置用户,因为我发现你如果在后面配置过程中如果使用非root用户,免密码登录过程实现有点麻烦,因为你每次还要加上sudo或者手动切换到root(当然我这只是方便学习而已,并没有应用)。
遇到问题1:su切换root,提示Authentication failure。
原因:没有激活root用户。解决方法:1 sudo passwd2 Password:输入你的当前root密码3 Enter new UNIX password:root密码4 Retype new UNIX password:重新输入root密码。

软件安装
一、JAVA、SSH安装(必备)
这两个是最重要的,关于这两个如何安装,具体可以根据你的系统百度一下,很容易找到的,在此我根据CentOS7.0说明一下.centos7.0是没有自带java,因此直接yum安装就好了。具体给几条命令吧。
yum list installed |grep java查看是否已经安装JDK
已经安装

yum -y list java* 查看yum中的java安装包
yum -y install java-1.8.0-openjdk*使用yum安装Java环境
配置本机JAVA_HOME
ls /usr/lib/jvm/--查看本机java安装目录

此时只需要在终端中打开环境变量文件 vim /etc/profile,(保存命令按ESC,然后输入“:w”即可保存,然后”:q”退出vi)填写相应的目录即可:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
SSH在centos7中是默认开启,所以并不需要安装与开启服务
相关命令,参考http://blog.csdn.net/nanatintin/article/details/8535445
#rpm -qa |grep ssh 检查是否装了SSH包没有的话yum install openssh-server
#chkconfig --list sshd 检查SSHD是否在本运行级别下设置为开机启动#chkconfig --level 2345 sshd on 如果没设置启动就设置下.
#service sshd restart 重新启动
#netstat -antp |grep sshd 看是否启动了22端口.确认下.
#iptables -nL 看看是否放行了22口
问题2:无法联网(ping 不通)
原因:系统安装过程中忘记开启联网设置。
解决方法:1,查看网卡配置文件名 一般是ifcfg-en*之类的

2.编辑该文件,修改ONBOOT=no改为ONBOOT=yes,esc后退:wq保存退出。

二、Xshell、Xftp软件安装(选备)
Xshell:官网链接,百度一些绿色破解软件也行,我的就是。
Xftp:官网链接
虽说是选备,但我觉得还是挺有必要的,个人选择,Xshell是为了方便在系统之间的切换以及文本的复制快速,毕竟在VMWARE大软件操作会有点麻烦;Xftp是为了方便在物理机和虚拟机之间传输文件,当然你如果是界面系统的话,安装tool其实也行,我的是无界面,所以......
三、iptable、network-tools安装(选备)
iptable:方便之后网络端口的查看以及关闭,centos默认使用firewall。安装:yum install iptables-services;编辑:vi /etc/sysconfig/iptables
network-tools:方便使用ifconfig查看ip,使用别的方法还是有的,个人习惯。安装:yum install network-tools;查看:ifconfig
ifconfig
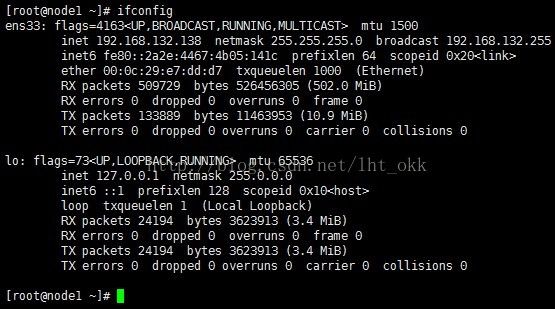
记住自己的三个系统IP,以我自己为例(node1:192.168.132.138;node2:192.168.132.139;node3:192.168.132.140)
Hadoop准备
一、Hadoop1.2.1官网下载:https://dist.apache.org/repos/dist/release/hadoop/common/hadoop-1.2.1/
二、利用Xftp放在三个系统中的同一个目录下(根目录)

三、解压(/root目录下)hadoop包到当前目录下:tar -zxvf hadoop-1.2.1.tar.gzip (-Z 指定解压目录)
注意:三个系统必须同时解压到相同目录下(以我自己为例,解压到/root/hadoop-1.2.1),避免之后出现找不到目录的错误。
四、(如果你的操作要在不同的目录下,可以选择重链接)
举个例子:ln -sf /root/hadoop-1.2.1 /root/hadoop--第一个目录为原始目录,第二个目录为链接目录
配置前测试和设置免密码登录,注意:每台主机都要做同样的事情
1.测试主机之间的通信:ping一下别的主机,看是否能通信,例如ping [email protected]和ping [email protected]
2.测试ssh是否能正常工作连接别的主机,例如:
等登录即可,exit退出继续测试。
3.实现ssh 主机名 登录
vi /etc/hosts--修改hosts文件,添加可以ssh 主机名登录的ip和主机名
格式:ip 主机名 别名(中间用空格隔开)

vi /etc/sysconfig/network
添加: NETWORKING=yes
HOSTNAME=node1
hostname--查看hostname名,如果不是对应的主机名,请修改 vi /etc/hostname--添加对应主机名即可![]()
node2和node3同理修改
4.免密码登录(实现node1登录node2和node3免密码)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys --生成id_dsa、id_dsa.pub、authorized_keys公钥文件
(此时可以测试本机是否可以免密登录,如:ssh node1)

scp id_dsa.pub root@node2:~--拷贝node1的公钥到node2和node3的根目录上去,前提是node2和node3实现了本机免密码
cat id_dsa.pub >> ~/.ssh/authorized_keys--在node2和node3的主机上分别把node1的公钥内容追加到本机的authorized_keys上去
好了,分别测试一下吧

配置Hadoop文件
1.进入到配置文件目录下
cd /root/hadoop --进入hadoop文件
cd conf --进入hadoop配置文件目录conf

2.配置core-site.xml
vi core-site.xml
在
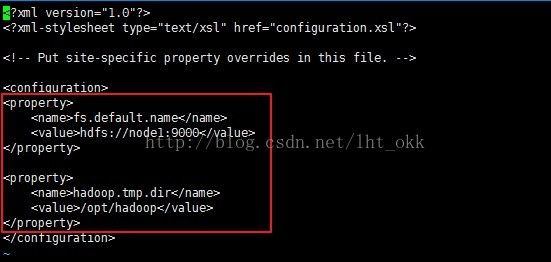
这个配置的namenode结点的信息,node1:地址信息,也可以是ip地址。如(192.168.132.138),之所以可以使用主机名,因为我配置hosts文件。
配置文件存放目录,默认会存放在tmp目录,一旦关机就会消失,因此手动设置一下。
3.配置hdfs-site.xml文件
添加以上内容,value=2,表示我们有2个DateNode节点。
4.配置slaves,设置DateNode
vi slaves
node2
node3
把节点名直接添加上去
5.配置masters,设置SeconaryNode
node2
这个可以设置DateNode上也行。
其他主机也要同样的配置操作,或者直接把配置好的文件直接复制过去也是可以的。
/root/hadoop/conf 目录下
scp ./* [email protected]:/root/hadoop/conf/
6.配置mapred-site.xml
启动HDFS
1.格式化
进入/root/hadoop/bin目录
./hadoop namenode -format--格式化操作

2.启动HDFS
./start-dfs.sh

问题3:找不到目录
原因:hadoop在每台主机的目录名称不一样导致
解决方法:修改DateNode机的hadoop目录,使其目录和NameNode的一样。
问题4:需要登录密码
原因:设置免密码登录不成功或者root用户拒绝非root用户登录
解决方法:重新按照上述方法设置免密码登录,或者非root用户设置root权限,具体百度一下。为了方便,本人使用root用户操作。
3.测试是否有启动
在namenode主机下,输入命令jps可以看到namenode字样表明成功启动,同理在datanode主机下可以看到datenode字样。


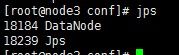
4.停止hdfs启动
./stop-dfs.sh
5 全启动
./start-all.sh
访问HDFS
在window上访问测试
1.修改window中hosts文件

添加host信息
192.168.132.138 node1
192.168.132.139 node2
192.168.132.140 node3
2.打开浏览器,地址栏输入 http://node1:50070,出现下图表示访问成功。

3.测试DateNode是否成功访问,点击 Browse the filesystem
成功加载

问题5:Browse the filesystem访问不了
原因和解决方法参考 http://www.cnblogs.com/hzmark/p/hadoop_Browsethefilesystem.html
一个普遍的说法就是主机名和ip对应不了,浏览器无法解析。解决方法就是设置访问机的hosts,使之对应起来。这个我上面也有说到。
但是我设置了之后还是遇到了这个问题,于是我检查端口,发现端口都是可以可以对应访问的,无奈找不出别的原因,直接把防火墙全部都关闭了,然后就好了,我估计还是端口的问题吧。
centos7下关闭防火墙
1、关闭firewall:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
访问MapReduce
http://node1:50030
参考:1 官方文档 http://hadoop.apache.org/docs/r1.2.1/single_node_setup.html
2 视频教程
3 百度
总结
总体上配置步骤不是很难,过程很清晰明了,前人也给我们总结了很多错误提示。可能对于linux的操作如果不熟悉的话,可能一些命令还有一些内部机制原理可能还是一知半解吧,没关系,学习嘛,一步一步来,看到的各位也可以给我一些意见,谢谢!