毕设总结1:使用python scrapy 爬取 伯乐在线文章
伯乐在线爬取教程
- 写在前面
- scrapy架构
- 爬取过程
- Spider
- 爬取思路
- Item
- pipelines
- Main
写在前面
伯乐在线 好像已经不能访问了,但爬虫的思路还是一样的。
scrapy架构
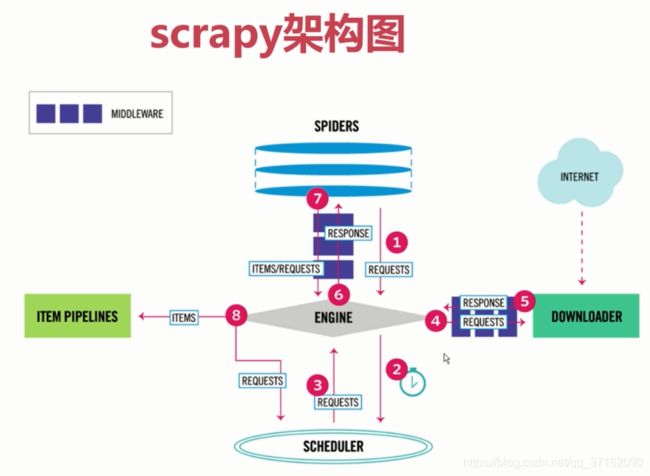
这里不深入介绍scrapy(主要是我自己也不是很懂..),但是了解一下运行原理还是对写代码有帮助的。
简单介绍一下这个框架,scrapy就是一款用python写的爬虫框架,它使爬虫的编写变得十分简单和有层次感。
简单介绍一下scrapy组件:
1. Spider:也就是自己写的爬虫逻辑;
2. Engine:scrapy引擎,类似于中央处理器;
3. Scheduler: 调度器;
4. Downloader:下载器,用于下载整个页面;
5. Item Pipeline:管道,用于处理数据;
6. Middleware:类似于过滤器,比如处理一下ip地址等。
简单的爬虫,我们只要编写Spider 、Item Pipeline 和 Middleware即可。
爬取过程
Spider
如果你想要自动生成一套Spider的模板可以:
1.进入命令行环境cmd(win+r);
2.然后进入到工作目录区间(本地项目存放目录);
3.输入 scrapy genspider (-t crawl(选择需要的模板)) xxx(爬虫名) www.xxx.com(爬取的目标网页)。
这里以伯乐在线为例:scrapy genspider jobbole www.jobbole.com
4.回车。
爬取思路
- 解析每篇文章的url,找出其规律,并使用css选择器或者xpath等手段去匹配相对应的元素,也就是这一页所有文章的url。
post_nodes = response.css("#archive .floated-thumb .post-thumb a") # 根据css选择器获取所有文章url+封面图
- 获取到每一篇文章的url后,分别下载每篇文章。
for post_node in post_nodes:
image_url = post_node.css("img::attr(src)").extract_first("") # 封面图
post_url = post_node.css("::attr(href)").extract_first("")
# yield 下载 解析
yield Request(url=parse.urljoin(response.url, post_url),
meta={"front_image_url": image_url},
callback=self.parse_detail_css) # callback 回调函数,这里通过parse_detail_css() 方法去获取每篇文章的标题、作者、内容等数据。方法会在下面代码处演示。
- 获取下一页的文章。以此类推 迭代加深度遍历。
# 提取下一页
next_urls = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_urls:
# 交给下载器
yield Request(url=next_urls, callback=self.parse)
注:笔者这里用的环境是 python3.6 + pycharm。
至于如何使用 css 和 xpath选择器,这里不做过多讲解,我会在以后专门写一篇关于选择器的博客。
jobbole爬虫逻辑代码:
import scrapy
from scrapy.http import Request
from urllib import parse
import re
import datetime
from ArticleSpider.utils.common import get_md5
from ArticleSpider.items import JobboleArticleItem
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] # 起始url
def parse(self, response):
'''
1. 获取文章列表中的文章url交给scrapy 下载解析
2.获取下一页的url
'''
post_nodes = response.css("#archive .floated-thumb .post-thumb a") # 根据css选择器获取所有文章url
for post_node in post_nodes:
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
# yield 下载 解析
# 在Request中把封面图url传入 到response中获取 这里用meta 字典
yield Request(url=parse.urljoin(response.url, post_url),
meta={"front_image_url": image_url},
callback=self.parse_detail_css)
print(post_url)
# 提取下一页
next_urls = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_urls:
# 交给下载器
yield Request(url=next_urls, callback=self.parse)
def parse_detail_css(self, response):
article_item = JobboleArticleItem()
# 获取封面图 从meta中获取
# front_image_url = response.meta["front_image_url"] # 字典的获取方法
front_image_url = response.meta.get("front_image_url", "") # get方法 默认值为""
print("封面图:%s" % front_image_url)
# 使用css方法
article_date = response.css(".entry-meta-hide-on-mobile::text").extract_first('').strip().replace(" ·", "")
print(article_date)
article_title = response.css(".entry-header h1::text").extract_first('')
print(article_title)
content = response.css(".entry").extract()[0]
article_zan = response.css(".vote-post-up h10::text").extract_first()
match_re = re.match(".*?(\d).*", article_zan)
if article_zan is None:
article_zan = 0
elif match_re:
article_zan = int(match_re.group(1))
else:
article_zan = 0
print("%d个赞" % article_zan)
article_fav = response.css(".bookmark-btn::text").extract_first("")
match_re = re.match(".*?(\d).*", article_fav)
if match_re:
article_fav = int(match_re.group(1))
else:
article_fav = 0
print("%d个收藏" % article_fav)
article_comment = response.css("a[href='#article-comment'] span::text").extract_first('')
match_re = re.match(".*?(\d).*", article_comment)
if match_re:
article_comment = int(match_re.group(1))
else:
article_comment = 0
print("%d条评论" % article_comment)
# item 填充值
article_item["article_title"] = article_title
article_item["url"] = response.url
try:
article_date = datetime.datetime.strptime(article_date, "%Y/%m/%d").date()
except Exception as res:
article_date = datetime.datetime.now().date()
article_item["article_date"] = article_date
article_item["front_image_url"] = [front_image_url]
article_item["article_zan"] = article_zan
article_item["article_comment"] = article_comment
article_item["article_fav"] = article_fav
article_item["content"] = content
article_item["url_object_id"] = get_md5(response.url)
yield article_item # 传递到pineline中
Item
可以看到上面Spider逻辑中,最后把数据全部放入了item中,可以把item看成临时存放数据的对象,包括到后面的存储数据,都是由item去传递的。所以必须要定义一个Item,定义数据类型。
在items.py中写入以下代码
class JobboleArticleItem(scrapy.Item):
article_title = scrapy.Field()
article_date = scrapy.Field()
url = scrapy.Field()
front_image_url = scrapy.Field() # 封面图url
front_image_path = scrapy.Field()
article_zan = scrapy.Field() # 赞的数量
article_fav = scrapy.Field()
article_comment = scrapy.Field()
content = scrapy.Field() # 文章内容
url_object_id = scrapy.Field() # MD5url 唯一且长度固定
# 这里把数据库操作放在了item中防止 多个item对pipeline的干扰。
def get_insert_sql(self):
# sql语句
insert_sql = """
INSERT INTO jobbole_article(article_title, url, url_object_id, article_date, content,
article_zan, article_comment, front_image_url)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
params = (self["article_title"], self["url"], self["url_object_id"],
self["article_date"], self["content"], self["article_zan"],
self["article_comment"], self["front_image_url"])
return insert_sql, params
pipelines
pipeline牵扯到数据库的操作,这里作者用的是mysql,实际项目中用到Elasticsearch来搭建搜索引擎服务,使用的是Elasticsearch非关系型数据库。
在pipelines.py中写入以下代码
import MySQLdb
from twisted.enterprise import adbapi
import MySQLdb.cursors
# 这里使用了连接池,异步。
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
# twisted 提供了一个异步容器
dbparams = dict(
host=settings["MYSQL_HOST"], # 数据库参数配在了settings.py中。在下面有介绍。
db=settings["MYSQL_DBNAME"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparams)
return cls(dbpool)
def process_item(self, item, spider):
# 使用方法二 将mysql 插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
# 处理错误
query.addErrback(self.handle_error, item, spider) # 处理异常
def handle_error(self, failure, item, spider):
print(failure)
def do_insert(self, cursor, item):
# 构建一种方法让不同的item都使用 在items.py中加入方法
insert_sql, params = item.get_insert_sql() # 不同的item有各自不同的数据库操作方法。
cursor.execute(insert_sql, params)
在settings.py中加入以下配置
MYSQL_HOST = "127.0.0.1" # 数据库服务地址
MYSQL_DBNAME = "article_spider" # 数据库名
MYSQL_USER = "root" # 用户名
MYSQL_PASSWORD = "root" # 密码
并修改settings中以下配置, 后面的数字代表优先级 越小越好。
ITEM_PIPELINES = {
'ArticleSpider.pipelines.MysqlTwistedPipeline': 3, # 数据库连接池操作
# 'ArticleSpider.pipelines.ElasticsearchPipeline': 2 # 把数据放到ES中(这里不作要求)
Main
最后,别忘了在main.py中加入执行语句去执行我们的这个爬虫。
execute(["scrapy", "crawl", "jobbole"]) # jobbole跟jobbole.py JobboleSpider name一致