加入attention的crnn ---- ocr之pytorch代码解释(带代码)
代码的作者说明网页:https://ptorch.com/news/228.html
代码:https://github.com/Andy-zhujunwen/Attention_ocr.pytorch
我在基于原作者的基础上进行代码的说明。
一,数据集
数据集下载链接:https://pan.baidu.com/s/1hIurFJ73XbzL-QG4V-oe0w#list/path=%2F
数据集是这样的纸条:
![]()
分辨率都是 32x280
索引文件是这样的:

左边表示训练图片的地址,右边表示训练图片的label,即图片上写着什么字。
字典:
要识别文字的话,那必不可少的就是字典文件了,字典文件里面每行一个汉字,这份代码提供的字典文件一共有5990个汉字,所以有5990行。
简图如下:(字典文件名字:char_std_5990.txt)
二,大体流程:
1。得到字典变量
通过字典文件读取字典里的每个字符,读到变量alphabet中:
with open('./data/char_std_5990.txt',encoding='UTF-8') as f:
data = f.readlines()
alphabet = [x.rstrip() for x in data]
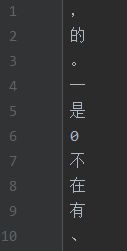
alphabet = ''.join(alphabet)#.decode('UTF-8') # python2不加decode的时候会乱码alphabet里是这样的:[,的。一是0不在有、人“”了中国大为1:上2这个以年生和我.......],所以alphabet里也是有5990个汉字的。
但是我们还要额外加多3个字符,一个是空格(用$表示),一个是表示开始的起始符号(SOS),一个是表示结束的结束符号(EOS)。然后把这5990+3个字符放进一个叫dict的字典变量中:
dict的形式:{['SOS']:0,['EOS']:1,['$']:2,[',']:3,['的']:4,,['。']:5,['一']:6,['是']:7......}
2.网络结构:
网络分为两部分:Encoder 和 Decoder
2.1 Encoder:
Encoder由CNN和两个双向的LSTM(BiLstm)组成:
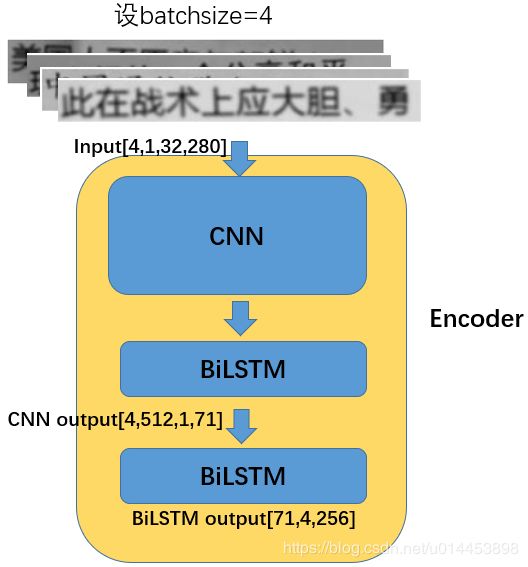
上图的Encoder里的input size为[4,1,32,280]是因为4是指batch size,1是通道数(表示输入图片是灰度图),32,280表示输入图片的尺寸是32x280. 并且由上可知,输入4张迅雷图片,输出的是4个1x71尺寸,通道数为256的特征向量。
class CNN(nn.Module):
'''
CNN+BiLstm做特征提取
'''
def __init__(self, imgH, nc, nh):
super(CNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
self.cnn = nn.Sequential(
nn.Conv2d(nc, 64, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d(2, 2), # 64x16x50
nn.Conv2d(64, 128, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d(2, 2), # 128x8x25
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d((2,2), (2,1), (0,1)),
nn.Conv2d(256, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True), # 512x4x25
nn.Conv2d(512, 512, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d((2,2), (2,1), (0,1)), # 512x2x25
nn.Conv2d(512, 512, 2, 1, 0), nn.BatchNorm2d(512), nn.ReLU(True)) # 512x1x25
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nh))
def forward(self, input):
#print(input.shape) #torch.Size([4, 1, 32, 280])
# conv features
conv = self.cnn(input)
#print(conv.shape) #([4, 512, 1, 71])
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2)
#print(conv.shape) #([4, 512, 71])
conv = conv.permute(2, 0, 1) # [w, b, c]
#print(conv.shape) #[71,4,512]
# rnn features calculate
encoder_outputs = self.rnn(conv) # seq * batch * n_classes// 25 × batchsize × 256(隐藏节点个数)
#print(encoder_outputs.shape) #[71,4,256]
return encoder_outputs2.2 Decoder
将训练图片输入到Encoder得到特征向量后,接着就得建立Decoder对特征向量进行处理。
首先要------处理labels:
我们假设batch size为4.则表示输入一次训练数据,就是4张图片:

从索引文件中,找出4张图,和相对应的4个label。然后对 这些labels进行编码(注意,上面的Encoder是对输入图片编码的,这次编码是对label编码的)。目的是把labels的文字转成字典(dict)中是数字,即用数字来表示文字。(当然还会在前头加上起始符号和最后加上结束符号)如下面过程:
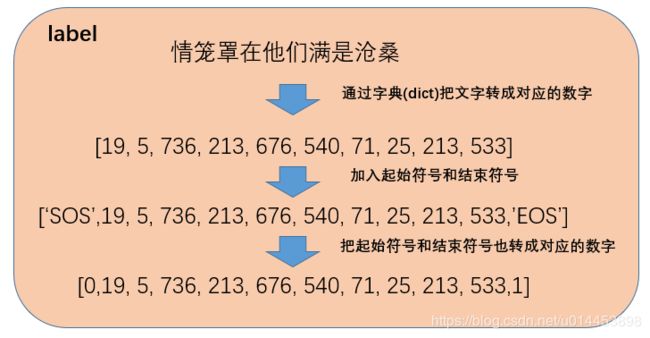
上述过程完成对单个label的处理。
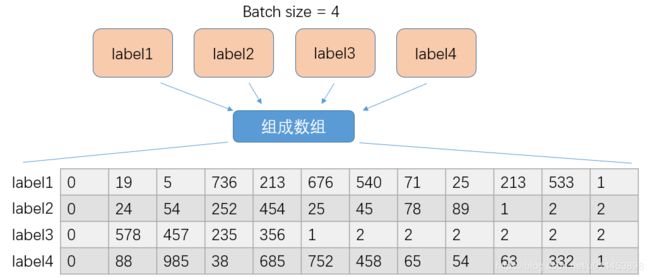
这就完成了一次训练的 labels 的编码,注意最后那个数组为什么那么多2,是因为一开始就按照最长的label设置数组的大小,例如label1最长,为12。则初始化数组为 4x12,并且初始值都为2,因为2在字典中表示空格。
def encode(self, text): #text形如('英语(零起点)只招日', '终必然会对博客服务商', '窥知母意,我自己也不', '今年早些时候,“好孝'),个数跟batchsize有关
if isinstance(text, str):
text = [self.dict[item] for item in text] #把text从dict中转换为相应的数字[19, 5, 736, 213, 676, 540, 71, 25, 213, 533]
elif isinstance(text, collections.Iterable):
text = [self.encode(s) for s in text] # 编码
max_length = max([len(x) for x in text]) # 对齐
nb = len(text) #4 = batch_size
targets = torch.ones(nb, max_length + 2) * 2# use ‘blank’ for pading #torch.Size([4,12)
for i in range(nb): #target=[batchsize,句子]
targets[i][0] = 0 # 开始
targets[i][1:len(text[i]) + 1] = text[i]
targets[i][len(text[i]) + 1] = 1
text = targets.transpose(0, 1).contiguous() #torch.Size([12, 4])
text = text.long()
return torch.LongTensor(text)
上图是总体流程图:其中 image encoder和labels encoder之前有介绍过,那现在说说decoder是如何工作的。
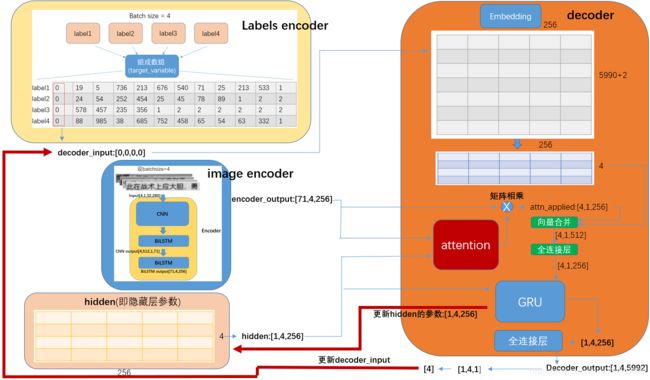
如上图所示,decoder的输入参数有几个,分别是:
decoder_input:表示送入decoder的batch size个字符,即batchsize个句子仲的第几列的字符。decoder_input初始值是0,因为每个句子被编码后,起始位置都被插入了一个起始符号(用0表示)。decoder_input输入到decoder后,decoder的会根据decoder的输出来更新decoder_input。
decoder_input的更新:

encoder_output:表示batchsize张训练图片经过神经网络提取的词向量。encoder_output会与hidden参数结合然后送入attention模块获得注意力权重(attention weight),即上图红色模块。
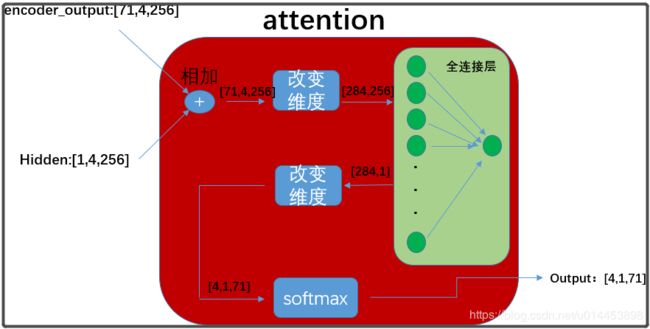
hidden: hidden属于可训练的参数,属于GRU(lstm变种)的状态变量,由GRU负责更新。
embedding:产生于decoder内,embedding在decoder内初始化,里面的参数也是可以被训练的。decoder_input往embedding输入4个词的序号,然后从embedding内取出相对应的词向量,与atten_applied进行合并并经过全连接层降维,送入GRU。
decoder最终得到的输出向量的维度是:[1,4,5992],其实就是表示 4(batchsize=4)张图片里,每张图片某个(列)字符在5992个汉字字典内各自的概率。
然后就和target_variable(上面流程图有)一起送到损失函数里计算损失值。
loss += criterion(decoder_output, target_variable[di]) # 每次预测一个字符 torch.Size([4, 5992]) 和 torch.Size([4])
测试阶段:
测试时,batchsize会被设置成1。即一张图片通过decoder_output出来的向量维度是[1,5992],通过选取概率最大的词的索引后,则为[1,1]。然后通过一个 词的decoder 来把词的索引从dict字典里 转换为对应的词。
def decode(self, t):
texts = list(self.dict.keys())[list(self.dict.values()).index(t)]
return texts
代码链接:https://github.com/Andy-zhujunwen/Attention_ocr.pytorch
后续可能会加上代码的演示效果。