3.Towards Unifified Depth and Semantic Prediction from a Single Image
论文在这儿
本篇论文的源代码貌似没有公布…
大体思想
由于深度估计和语义分割两者有密切关联且能相互促进,所以这篇论文提出了一个统一的深度和语义联合预测框架(a two-layer Hierarchical Conditional Random Field分层条件随机场(HCRF)),首次将语义分割和深度估计结合起来。
CRF的理解
CRF就是用来计算给定观察序列计算标记序列的概率的P(y | x, lambda),需要确定特征函数和参数向量lambda,特征函数的选取决定了性能,lambda使用极大似然法估计
这篇论文先使用第一篇论文中的global CNN在整张图片上去预测一个由像素级别的深度值和语义标签组成的global layout。再将图片划分成local segments在global layout的指导下预测得到region-level depth and semantic labels,帮助实现更多的细节。
①框架: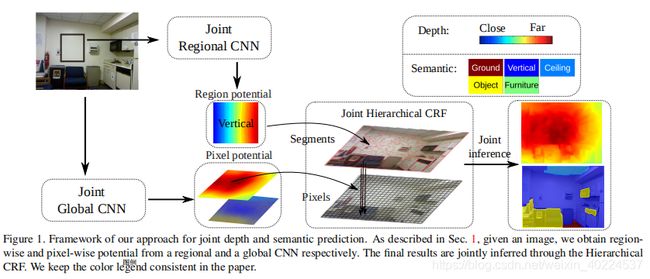
在底层的一元势(the unary potentials)是在整张图上使用CNN全局预测得到的像素级别的深度值和语义标签,提供global scale and semantic guidance。上层的一元势是在local regions上通过另一个CNN based regressors训练得到的region-wise depth and semantic maps,give more depth and semantic boundaries.
②Formulation:
HCRF由两层结点(nodes)和边(edges)组成
底层:
结点是图片I中的像素,每个像素i属于I.
我们的目的是预测每个像素的深度值di和语义标签Ii。
使用Xi={di,Ii}表示the inference output at pixel i.
上层:
把图片I分解成local segments,使用segments表示结点。
S表示分解后的the set of segments,s表示每个segment.
ys={ds,ls}表示每个segment的深度和语义标签。
RS表示一个segment s中的所有像素,XS表示RS中的所有预测值
三种edges:
- the pair-wise edges between neighboring pixels
- the edges between neighboring segments
- the edges connecting R_s and s
The energy for minimization is formulated as:

其中:
①the pair-wise edges between neighboring pixels:![]()
![]()
![]()
td:threshold
②the edges connecting R_s and s
在图上!!!
③the edges between neighboring segments:

![]()
![]()
【注】
dist_g(s, t):基于semantic edge map所计算的测地距离(geodesic distance)
f:local appearance feature(the mean and variance of the pixel RGB values),
针对每个segment
dist_a(s, t):两个segments之间的基于appearance的距离
w(l_s, l_t):从数据中学习到的平滑权重矩阵(当l_s= l_t即两个segments语义标签一致时,w(l_s, l_t)值越高,两个segments之间越需要higher depth smoothness)
③Joint Global Depth and Semantic Prediction:
使用的CNN框架是第一篇论文中的coarse网络(第一个),除了在最后一层的深度结点,也引入了语义节点去预测语义标签。所以损失函数由两部分组成:
【注】训练数据时,先仅仅使用RGB-D training data(在最后一层去除语义节点)训练网络去预测深度值,然后使用带语义标签的RGB-D数据集增加语义节点来调整网络。训练时,将会对属于一个语义标签的每一个像素预测深度图和probability image
④Joint Local Depth and Semantic Prediction:
在局部预测阶段,我们想要估计the segment的the normalized depth map
d_i = d_n ∗ sc + d_c
d_c:segment center的绝对深度值
d_n:the depth map的相对深度值
sc:the scale change(比例因子)
【注】[d_c, sc] are two unknown variables that we would infer in the HCRF,当我们推断出这两个值时,将他们与标准深度图结合来得到这个segment中每一个像素的绝对深度,这样可以增强全局像素级预测和局部segment级预测的一致性。
4.1. Normalized Joint Templates
将局部深度估计问题描述为一组规范化模板(template)的合成预测。为了合成模板,使用the semantic and depth ground truth去保证一致性。首先根据语义标签cluster the segments,对于相同标签的segments,使用L1 distance metric去cluster their normalized depth maps来生成一组模板。

4.2. Joint Template Regression
使用a segment s和一组模板Tj去学习segment和模板之间的相似度(affinities)。使用CNN作为局部训练模型,且将segments的warped bounding box作为输入。Local CNN是通过微调第③部分的the global CNN来学习的。回归后,选取有Top N(这篇论文中用的N=2)相似度的模板,将它们的标准化深度值和语义标签聚合到具有其相关性的segment上作为权重。这个平均结果就是标准化深度图的预测和该段语义标签的概率???
The affifinity during training is defifined as:
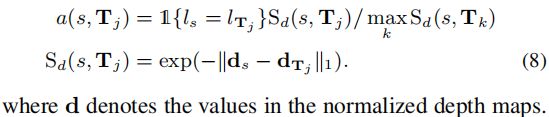
Loss function over the affinities:
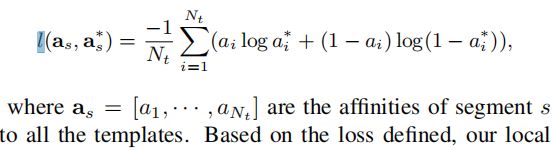
【注】本文提出了由于local segment appearance所导致的深度和语义模糊问题的三种方法:
1.使用the global CNN的输出regularize局部预测。
2.屏蔽掉segments外的背景可以减少两个segments共用一个边界框的混淆。for a segment, we take the f c6 layer output of the local CNN both from its bounding box and masked region, and concatenate it with the global prediction within the corresponding bounding box to form our feature vector.We train a Support Vector Regressor upon that feature to predict a segment’s affifinities to the templates.
3. 如果segments很大的话,预测的模糊问题会减轻。(30,50,100segments in three scales respectively)
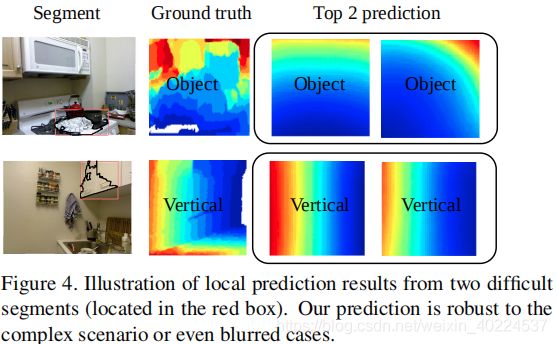
【注】补充前面的公式:
![]() 【注】
【注】
P(l_s):segment s上预测的语义标签的可能性
d_gc:在segment center进行全局深度预测得出的绝对深度
sc_g:在segments边界框进行全局预测得到的the depth scale
⑤Joint HCRF Inference:
使用loopy belief propagation(LBP),具体操作并不是将两个任务同时进行,而是minimizing one when fixing the other
LBP:K. P. Murphy, Y. Weiss, and M. I. Jordan. Loopy belief propagation for approximate inference:An empirical study. In CoRR, 2013
1.给定深度估计进行语义推理:给定深度估计,先执行LBP去在segment level中推测语义标签,然后将局部区域的预测传递给它所覆盖的像素,然后使用MAP预测像素级别的语义标签。
2. 给定语义标签进行深度估计:先在segment-level推测深度变量(the center depth d_c和比例因子sc),由于这些变量是连续的,无法使用LBP,所以将一个segment的中心深度d_c量化为与全局模型中预测的各个值相对应的一组离散的偏移量,并且将尺度sc量化为各个全局尺度的偏移
【注】
论文中使用全局预测作为初始化,通过首先估计语义标签,然后预测深度来执行1次迭代。(迭代次数多的话,效果提升反而并不明显)为了进一步加快算法的速度,论文中使用graph cut来有效地解决像素级语义标注问题。在像素级深度推断中,我们发现平滑项对最终解的影响很小。因此,深度推断被简化为全局预测和局部预测的线性组合,这很容易通过使用地面真实深度的最大似然来学习