李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。
这篇文章是学习本课程第13-15课所做的笔记和自己的理解。
**Lecture 13: Unsupervised Learning - Linear Methods **
Unsupervised Learning有两种,化繁为简(Clustering & Dimension: 复杂的input→简单的output, training时只有一堆input, 不知output),无中生有(Generation: input random number, 经过function, 得到image)。
Clustering
K-means
k需要自己定
Hierarchical Agglomerative Clustering (HAC)

聚类要把目标聚到某一类里边,而实际中可能目标70%属于一类,30%属于另一类,分布式的表示也可称为降维。
Dimension Reduction
Feature selection
如果data point的某一维都不变,就没有存在意义,可以去掉。
此方法适用场合有限。
Principle Component Analysis (PCA)
希望新的特征的variance尽量大,所以k个w选择的是cov(x)的前k个最大的eigenvalue对应的eigenvector。

数学推导:

新特征的各维度之间无相关性,作为input data,可用较简单的model处理,避免overfitting。
用SVD方法得到PCA的解:

从NN角度理解PCA:

train这个NN的参数,让output与input越接近越好。
不能用gradient descent,以为不能保证 w i , w j w^i,w^j wi,wj 正交。
效果也不会比SVD方法更好。
PCA的缺点:
1、PCA是无监督的,不知道数据的标签,这样在降维映射之后可能会把两类数据混到一起。
考虑数据标签的方法LDA(Linear Discriminant Analysis)可以避免这一问题。
2、PCA是线性的。把一个三维空间中的S形分布的数据做PCA之后的效果,就是把S形拍扁,而非展开。
对宝可梦做PCA
每个宝可梦是六维向量,计算出6个特征值,计算6个特征值的ratio,舍去较小的(只取前四个特征值的特征向量作为新的特征,或者叫主成分PC)。特征值的意义是,PCA降维时,在相应维度的variance有多大。
每个PC都是一个六维向量,分析它们在哪个维度是大的正值/负值,可以分析出这个PC所代表的意义。
对人脸做PCA
对人脸,取前30个PC,每个PC拼成image,发现都是脸,而不是脸的一部分。
解释:

对数字和人脸做NMF
得到的都是“部分”:

Matrix Factorization
人买公仔,人和公仔背后都有共同的隐藏属性影响人买多少公仔,例如人的属性:萌傲娇/萌天然呆,公仔的属性:傲娇/天然呆。
我们要从购买记录(矩阵)中推断出latent factor,latent factor的数目需要事先定好。

对矩阵做SVD,SVD的中间矩阵可以并到左边矩阵或右边矩阵。
有missing data怎么办?用gradient descent做,先定义loss function L(只考虑有定义的数据)。

得到 r A , r B , r C , r D , r E , r 1 , r 2 , r 3 , r 4 r^A,r^B,r^C,r^D,r^E,r^1,r^2,r^3,r^4 rA,rB,rC,rD,rE,r1,r2,r3,r4 之后,并不知道每个维度代表什么属性,需要事后分析。
已知姐寺与小唯属于天然呆类型、春日与炮姐属于傲娇类型,所以第一个维度代表天然呆,第二个维度代表傲娇。
**Lecture 14: Unsupervised Learning - Word Embedding **
Word Embedding是降维的应用。

1-of-N Encoding不能体现单词之间的关系(如不能体现cat,dog之间的关系),改进为word class之后,不能体现类之间的关系(如不能体现class 1与class 2之间的关系),所以映射到高维空间。
生成词向量是无监督的,training data是大量文本,机器通过上下文得到词向量。
利用上下文有两类方法:Count-based与Prediction-based
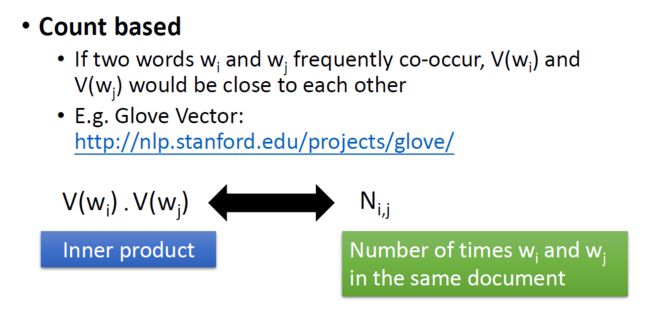
Count-based
Prediction-based
用前一个词预测后一个词:

用第一个hidden layer的input代表该词的word-embedding
对“蔡English”“马英Nine”要让它们在进入hidden layer之前(word-embedding)相近。
用前两个词预测后一个词:
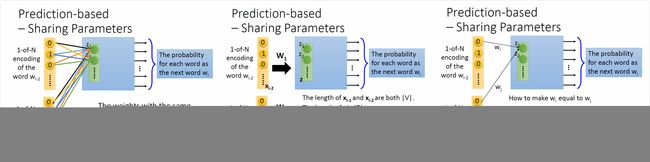
要共享参数,否则一个词会有两个词向量,共享参数还可以减少参数数量。
图中的梯度下降时参数更新公式可以保证对应参数一直相等。
Prediction-based的训练与其它结构

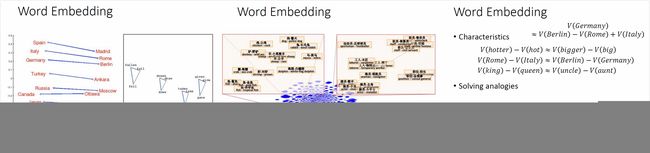
Word Embedding的特点
Multi-domain Embedding
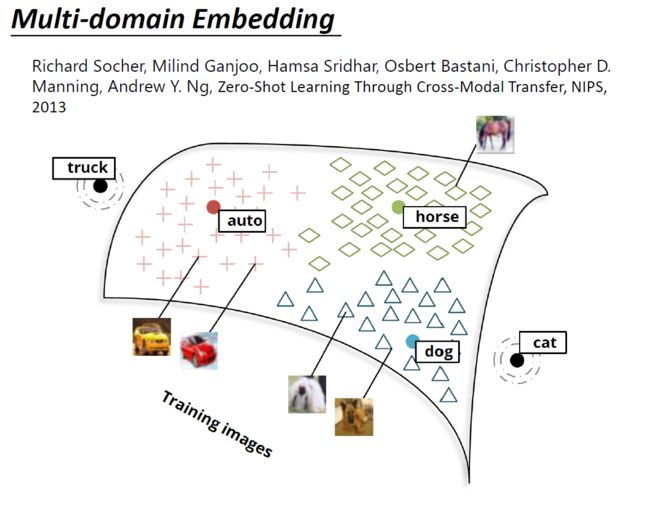
image经过NN,得到一个vector(与word vector同维度)。
对training时没出现的类别也可以进行分类!
**Lecture 15: Unsupervised Learning - Neighbor Embedding **
Manifold Learning
现在要做非线性降维。
数据可能是高维空间中的manifold,即数据其实分布在低维空间,被扭曲到高维空间中(如地球表面)。
在manifold上只有距离很近的点,欧式几何才成立。(12距离比13距离近,所以12像、13不像。14、15距离太大,没法比,不make sense)。
所以manifold learning就是要把S形展开,这样的好处是可以用欧式距离。

Locally Linear Embedding (LLE)
从原来的分布中找一点 x i x^i xi,然后找它的neighbour x j x^j xj,计算它们之间的关系 w i j w_{ij} wij。把 x i , x j x^i,x^j xi,xj 降维成 z i , z j z^i,z^j zi,zj 之后要保证它们之间的 w i j w_{ij} wij 不变。李老师用白居易《长恨歌》作比,浪漫!

LLE没有明确的function做降维。
LLE的好处是,就算不知道 x i , x j x^i,x^j xi,xj 只知道 w i j w_{ij} wij ,也可以用LLE。
要好好调neighbour的个数,刚刚好才会得到好的结果。
点之间的距离关系保持不变需要点之间够近,所以k太大不行,会考虑一些太远的点。
Laplacian Eigenmaps

两个红点之间的距离不能用欧氏距离还衡量,要看两点之间有没有高密度区域的链接,可以建立一个图,用图中的距离来表示。
回顾半监督学习:红框里那项与labelled data无关,它利用unlabelled data考虑得到的label是否smooth,作用类似于正则项。
同样的道理可以用在无监督学习。但是最小化S会有问题,因为只要让 z i = z j z^i = z^j zi=zj 就好了,这显然不合理。之所以在半监督学习时没有这个问题,是因为半监督学习的损失函数还有一项从标注数据而来,如果让所有标签都相等则那一项会很大。
所以要加一个约束:设z是M维的,则 z 1 , z 2 , . . . , z N z^1,z^2,...,z^N z1,z2,...,zN 张成 R M R^M RM 空间。
这样解出z。z就是graph laplacion L L L 的eigenvector,对应比较小的eigenvalue。
先找出z再用k-means做聚类,叫Spectral clustering.
T-distributed Stochastic Neighbor Embedding (t-SNE)
前面方法只假设相近的点接近,未假设不相近的点要分开。
t-SNE先分别计算原空间、新空间中所有点对的相似度再归一化。归一化是必要的,为了防止两个空间中距离的scale不同。
然后最小化二者之间的KL距离,代入公式用GD即可。
t-SNE计算量大,可先用PCA降维,再用t-SNE降维。
t-SNE需要一堆data point,然后找到z。如果之后再给一个数据,t-SNE是没法做的,只能再跑一遍。
所以t-SNE主要用于可视化。
t-SNE的神妙之处在于原空间与新空间中相似度计算公式不同。
原空间的计算公式,使得两个点的相似度随距离增加快速下降。
而新空间的计算公式,是长尾的,为了维持相同的相似度,两个点之间要分得更开。对原来距离很近的点,影响很小。而原来离得远的点,会被拉开,强化gap。
比较LLE on MNIST 与 t-SNE on MNIST。后者先做了PCA。

李宏毅机器学习课程笔记
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
李宏毅机器学习课程笔记2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅机器学习课程笔记3:Backpropagation、“Hello world” of Deep Learning、Tips for Training DNN
李宏毅机器学习课程笔记4:CNN、Why Deep、Semi-supervised
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅机器学习课程笔记8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅机器学习课程笔记9:Recurrent Neural Network
李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning