20180827-0917医疗复赛总结

介绍下本人。中山大学,医学生+计科学生的集合体,机器学习爱好者。
这次复赛主要是图像分类,但是感觉需要人工画坐标,因为目前效果不是很好。
记得其他比赛都是给了坐标的json,也不知道大佬们是怎么做的。
因为毕竟是自己独立的尝试网络,还是想特此记录一下。图片和链接难以贴上,就保存在本地了。需要的私聊我就好~
1、搭环境
(1)服务器端(华为云)(在浏览器里输入网址)
①搭建华为云服务器,配置linux基础环境
linux基础环境教程.pdf
②linux环境安装cuda,cudnn
ubuntu16.04下安装CUDA,cuDNN及tensorflow-gpu版本过程.pdf
Ubuntu16.04安装tensorflow(gpu版)、torch、pytorch、mxnet.pdf
③搭建anaconda和pycharm
Centos7.2离线安装 Tensorflow_gpu环境,搭建Anaconda3和pycharm.pdf
安装anaconda.pdf
安装pycharm.pdf
activate.txt(pycharm激活码,可以试试,似乎没效果)
(2)本地s3browser互传文件
①安装s3browser
s3browser配置.pdf
s3cmd工具同步S3存储桶内所有对象到本地目录指导.pdf
数据集在obs-trainingdata
软件在softwarebucket
②linux上安装库(华为云已经连接了华为镜像)
直接pip install,找不到的本机下载轮子上传softwarebucket,然后s3cmd get下载,再pip install+轮子名字
(3)使用pycharm
①启动pycharm
环境配置\linux
启动 pycharm程序的命令(pycharm已安装好).pdf

②pycharm导入tensorflow-gpu(好像需要每一个py文件都导入一次才能测试tensorflow-gpu成功)
环境配置\ImportError libcublas.so.9.0 cannot open shared
object file No such file or directory.pdf
2、数据集准备(在/mnt/sdc路径下下载文件,也就是先定位目录到sdc下,再执行s3cmd get)
①解压数据集到各自文件夹
1)解压到同名文件夹(会自己创建同名文件夹)并打印日志,解压完成后是100%。直接跳到最底shift+:+$回车到最后一行
![]()
2)查看是否有临时文件

3)遇到了要在Linux下删除海量文件的情况,需要删除数十万个文件。这个是之前的程序写的日志,增长很快,而且没什么用。这个时候,我们常用的删除命令rm -fr * 就不好用了,因为要等待的时间太长。所以必须要采取一些非常手段。我们可以使用rsync来实现快速删除大量文件。
1))先安装rsync:
yum install rsync
2))建立一个空的文件夹:
mkdir /tmp/test
3))用rsync删除目标目录:
rsync --delete-before -a -H -v --progress --stats /tmp/test/ log/
4))批量删除jpg文件
![]()
这样我们要删除的log目录就会被清空了,删除的速度会非常快。rsync实际上用的是替换原理,处理数十万个文件也是秒删。
选项说明:
–delete-before 接收者在传输之前进行删除操作
–progress 在传输时显示传输过程
-a 归档模式,表示以递归方式传输文件,并保持所有文件属性
-H 保持硬连接的文件
-v 详细输出模式
–stats 给出某些文件的传输状态
当SRC和DEST文件性质不一致时将会报错
当SRC和DEST性质都为文件【f】时,意思是清空文件内容而不是删除文件
当SRC和DEST性质都为目录【d】时,意思是删除该目录下的所有文件,使其变为空目录
最重要的是,它的处理速度相当快,处理几个G的文件也就是秒级的事
最核心的内容是:rsync实际上用的就是替换原理。
ls | xargs –n 10 rm –fr ls
②数据集格式检查
(因为实际放入网络的时候发现:
![]()
![]()
因为jpg文件里混杂了后缀是jpg,实际是bmp或者其他格式的文件。经典网络结构里的编码就是jpg,也可以用其他格式,可以自己写)
1)安装identify,查找图片格式
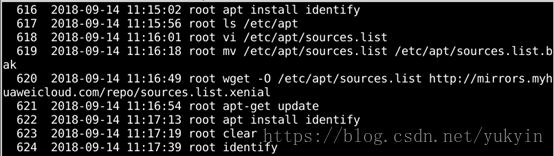
2)建立test.sh脚本
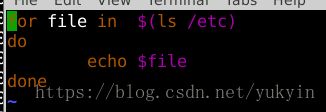
3)建立testJPG.sh脚本
![]()
4)脚本内容,把trainingdata_part2里的图片信息重定向到test(此时在目录train2下,所以identify后面要加trainingData_part2/表明此目录下图片的相对路径。此处若不加,则需要把这个sh文件放入trainingdata_part2里,下面生成的test第一列则是文件名)

5)用建立的脚本查找不是jpg的文件重定向到log(比对路径信息和图片信息)

6)发现之所以报错是因为test是以空格分隔,read_csv以空格分隔后,bmp多了一个字段
![]()
![]()
打开test
![]()
输入 :110
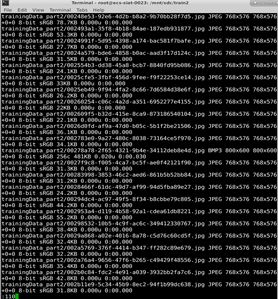

BMP这一行多了个256c,所以有十个空格
7)把test的第二列(图片真实后缀)重定向到test2里
![]()
8)检测test2里有几种格式
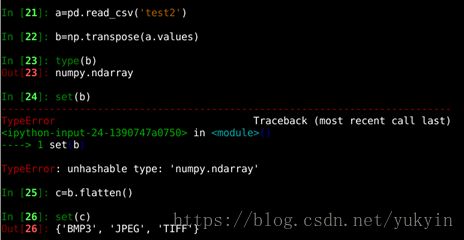
9)查找test里的BMP3文件重定向到bmp里,取出第一列文件名字
![]()
![]()
10)查找test里的TIFF文件重定向到tiff里,同上取出第一列文件名
![]()
11)删除指定文件
![]()
若file和图片不在一个文件夹,则在图片文件夹下输入以上命令,file写绝对路径加文件名
如file是/mnt/sdc/train2/bmp1,图在/mnt/sdc/train2/trainingData_part2
cd
/mnt/sdc/train2/trainingData_part2
tr
‘\n’ ‘\0’ < /mnt/sdc/train2/bmp1 | xargs -0 rm
12)把文件夹下的图片定向到filelist里
ls > index 相当于把ls应该显示的东西输出到index文件里
ls trainingData_part2
filelist
将traini ngData_part2的内容输出到filelist
3、数据预处理
(1)part1:pacsinfo文件里增加path列和abs_path列,通过risid搜索
(2)part2:pacsinfo文件里增加abs_path列,通过path+dir(对应文件夹);生成的two_pacsinfo和two_hisinfo和filelist合并,以filelist为准(保证有图);
(3)测试集的五个如part2处理后,与part2进行concat,生成新part2。生成一列source标记来源于train还是test几。(因为发现测试集与part2内容类似)
(4)part3:pacsinfo文件里增加abs_path列,通过path+dir(对应文件夹);生成的two_pacsinfo和two_hisinfo和filelist合并,以filelist为准(保证有图)(因为optype一对多)
(5)发现part1的risid是int64,astype为obj
(6)part1-3合并,以part2为准,生成hebing,保证有标签
(7)增加三个特征:age(用reg_date最大值-birth_date)、risid_cnt、reg_date_max生成新hebing
(8)把新hebing文件打label:
0:type1=0&type2=0
1:type1=1&type2=0
2:type1=0&type2=1
3:type1=1&type2=1
-1:source=1|source=2|source=3|source=4|source=5
(source=0是训练集,|是或,&是且)
4、网络
把train_data和label放入网络,分训练集和验证集,最后预测集预测到的分类建立对应的type表(两列,type1和2)。其他bug见代码及问题文件夹。
5、把病历表部分(part1-3)和图片输出层当特征放入lgb和xgb(都是0 1,不需要onehot)
不足之处,多多指教~