Python数据分析01:语法基础
第1章 准备工作(Preliminaries)
1.1重要的Python库
1.1.1NumPy
NumPy(Numerical Python的简称)是Python科学计算的基础包。Numpy不仅为Python提供快速的数组处理能力,而且NumPy在数据分析⽅⾯还有另外⼀个主要作⽤,即作为在算法和库之间传递数据的容器。对于数值型数据,NumPy数组在存储和处理数据时要⽐内置的Python数据结构⾼效得多。
1.1.2pandas
pandas提供了快速便捷处理结构化数据的⼤量数据结构和函数。⾃从2010年出现以来,它使Python成为强⼤⽽⾼效的数据分析环境。本书⽤得最多的pandas对象是DataFrame,它是
⼀个⾯向列(column-oriented)的⼆维表结构,另⼀个是Series,⼀个⼀维的标签化数组对象。
pandas兼具NumPy⾼性能的数组计算功能以及电⼦表格和关系型数据库(如SQL)灵活的数据处理功能。它提供了复杂精细的索引功能,以便更为便捷地完成重塑、切⽚和切块、聚合以及选取数据⼦集等操作。
1.1.3matplotlib
matplotlib是最流⾏的⽤于绘制图表和其它⼆维数据可视化的Python库。它最初由John D.Hunter(JDH)创建,⽬前由⼀个庞⼤的开发⼈员团队维护。它⾮常适合创建出版物上⽤的图表。虽然还有其它的Python可视化库,matplotlib却是使⽤最⼴泛的,并且它和其它⽣态⼯具配合也⾮常完美
1.2引入惯例
Python社区已经⼴泛采取了⼀些常⽤模块的命名惯例:
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport seaborn as snsimport statsmodels as sm
因此,当你看到np.arange时,就应该想到它引⽤的是NumPy中的arange函数
第2章 Python语法基础,IPython和Jupyter Notebooks
2.1 Python基础
加载Numpy库,生成随机数(IPython可读性较强)
import numpy as np
data = {i : np.random.randn() for i in range(7)}
data
#输出
{0: -0.05757878139706212,
1: -0.7783998166155556,
2: -0.8518952223355938,
3: -0.07822225232974736,
4: -1.317626542766965,
5: 1.3368188882374743,
6: 0.305922679176145}
在标准Python解释器上打印data,可读性较差如下
>>> from numpy.random import randn
>>> data = {i : randn() for i in range(7)}
>>> print(data)
{0: -1.5948255432744511, 1: 0.10569006472787983, 2: 1.972367135977295,
3: 0.15455217573074576, 4: -0.24058577449429575, 5: -1.2904897053651216,
6: 0.3308507317325902}
2.1.1 Tab补全
按下Tab,会搜索已输⼊变量(对象、函数等等)的命名空间
an_apple = 27
an_example = 42
an #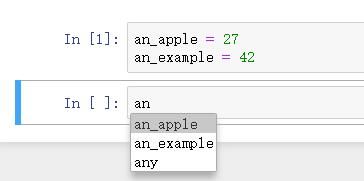
Tab代码补全同样适用于模块中,Tab键也可以补全文件路径
import datetime
datetime. #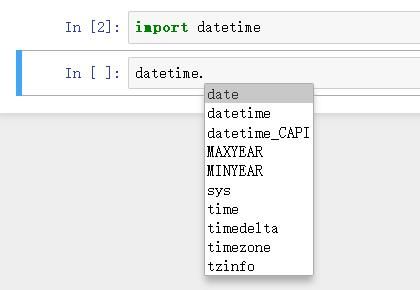
2.1.2 自省
在变量前后使⽤问号?,可以显示对象的信息:
b = [1,2,3]
b?
#输出结果如下
Type: list
String form: [1, 2, 3]
Length: 3
Docstring:
Built-in mutable sequence.
If no argument is given, the constructor creates a new empty list.
The argument must be an iterable if specified.
也可以作为对象的⾃省。如果对象是⼀个函数或实例⽅法,定义过的⽂档字符串,也会显示出信息。假设我们写了⼀个如下的函数:
def add_numbers(a, b):
"""
Add two numbers together
Returns
-------
the_sum : type of arguments
"""
return a + b
使用 ? 显示 add_numbers() 信息
add_numbers?
#输出结果如下
Signature: add_numbers(a, b)
Docstring:
Add two numbers together
Returns
-------
the_sum : type of arguments
File: d:\jupyter notebook\<ipython-input-94-0e543d60c645>
Type: function
使⽤ ?? 会显示函数的源码
add_numbers??
#输出结果如下
Signature: add_numbers(a, b)
Source:
def add_numbers(a, b):
"""
Add two numbers together
Returns
-------
the_sum : type of arguments
"""
return a + b
File: d:\jupyter notebook\<ipython-input-94-0e543d60c645>
Type: function
? 还有⼀个⽤途,就是像Unix或Windows命令⾏⼀样搜索IPython的命名空间。字符与通配符结合可以匹配所有的名字。例如,我们可以获得所有包含load的 NumPy 命名空间:
np.*load*?
#输出结果如下
np.__loader__
np.load
np.loads
np.loadtxt
2.1.3 %run命令
你可以⽤ %run 命令运⾏所有的Python程序。假设有⼀个⽂件 ipython_script_test.py :
def f(x, y, z):
return (x + y) / z
a = 5
b = 6
c = 7.5
result = f(a, b, c)
可以如下运⾏:
%run ipython_script_test.py
如果想让⼀个脚本访问IPython已经定义过的变量,可以使⽤ %run -i;在Jupyter notebook中,你也可以使⽤ %load ,它将脚本导⼊到⼀个代码格中。
2.1.4 中断运行的代码
代码运⾏时按Ctrl-C,⽆论是%run或⻓时间运⾏命令,都会导致KeyboardInterrupt。这会导致几乎左右Python程序⽴即停⽌,除⾮⼀些特殊情况。
2.1.5 从剪贴板执行程序
如果使⽤Jupyter notebook,你可以将代码复制粘贴到任意代码格执⾏。在IPython shell中也可以从剪贴板执⾏。假设在其它应⽤中复制了如下代码:
x = 5
y = 7
if x > 5:
x += 1
y = 8
最简单的⽅法是使⽤%paste和%cpaste函数,%paste可以直接运⾏剪贴板中的代码,%cpaste功能类似,但会给出⼀条提示:
%paste
%cpaste
2.1.6 魔术命令
IPython中特殊的命令(Python中没有)被称作“魔术”命令。这些命令可以使普通任务更便捷,更容易控制IPython系统。魔术命令是在指令前添加百分号%前缀。例如,可以⽤%timeit(这个命令后⾯会详谈)测量任何Python语句,例如矩阵乘法,的执⾏时间:
a = np.random.randn(100, 100)
%timeit np.dot(a, a)
47.3 µs ± 1.98 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
魔术命令可以被看做IPython中运⾏的命令⾏。许多魔术命令有“命令⾏”选项,可以通过?查看:
%debug?
魔术函数默认可以不⽤百分号,只要没有变量和函数名相同。这个特点被称为“⾃动魔术”,可以⽤%automagic打开或关闭。⼀些魔术函数与Python函数很像,它的结果可以赋值给⼀个变量:
%pwd
#输出结果
'D:\\Jupter Notebook'
foo = %pwd
foo
#输出结果
'D:\\Jupter Notebook'
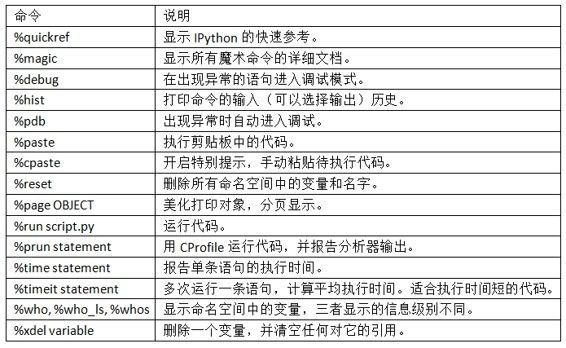
IPython的⽂档可以在shell中打开,我建议你⽤%quickref或%magic学习下所有特殊命令,下表列出了⼀些可以提⾼⽣产率的交互计算和Python开发的IPython指令。
2.1.7 集成Matplotlib
IPython在分析计算领域能够流⾏的原因之⼀是它⾮常好的集成了数据可视化和其它⽤户界⾯库,⽐如matplotlib。不⽤担⼼以前没⽤过matplotlib,后⾯会详细介绍。%matplotlib魔术函数配置了IPython shell和Jupyter notebook中的matplotlib。
在IPython shell中,运⾏%matplotlib可以进⾏设置,可以创建多个绘图窗⼝,⽽不会⼲扰控制台session:
%matplotlib
#输出结果
Using matplotlib backend: Qt5Agg
2.2 Python语法基础
Python的语⾔设计强调的是可读性、简洁和清晰。所以有些⼈称Python为“可执⾏的伪代码”
2.2.1 使用缩进,而不是括号
Python使⽤空⽩字符(tab和空格:最好是使用四个空格或者使用tab代替四个空格)来组织代码,⽽不是像其它语⾔,⽐如R、C++、JAVA和Perl那样使⽤括号。看⼀个排序算法的for循环:
for x in array:
if x < pivot:
less.append(x)
else:
greater.append(x)
冒号标志着缩进代码块的开始,冒号之后的所有代码的缩进量必须相同,直到代码块结束。不管是否喜欢这种形式,使⽤空⽩符是Python程序员开发的⼀部分,这可以让python的代码可读性⼤⼤优于其它语⾔。虽然期初看起来很奇怪,经过⼀段时间,你就能适应了。
分号可以给同一行的语句做切分,但是Python不建议将多条语句放在一行,会降低代码可读性:
a = 5; b = 6; c = 7
2.2.2 万物皆对象
Python语⾔的⼀个重要特性就是它的对象模型的⼀致性。每个数字、字符串、数据结构、函数、类、模块等等,都是在Python解释器的⾃有“盒⼦”内,它被认为是Python对象。每个对象都有类型(例如,字符串或函数)和内部数据。在实际中,这可以让语⾔⾮常灵活,因为函数也可以被当做对象使⽤。
2.2.3 注释
Python使用#添加注释,任何前⾯带有井号#的⽂本都会被Python解释器忽略:
a=23
#a
2.2.4 变量和参数传递
在Python中,对于下述代码,将a赋值给新变量b的过程,实际上是一个引用过程,a和b本质上是同一个对象:
a = [1, 2, 3]
b = a
a.append(4) # 在a中添加一个元素
b
#输出结果
[1, 2, 3, 4]
赋值也被称作绑定,我们是把⼀个名字绑定给⼀个对象。变量名有时可能被称为绑定变量。
2.2.5 动态引用,强类型
变量是在特殊命名空间中的对象的名字,类型信息保存在对象⾃身中,与许多编译语⾔(如JAVA和C++)对⽐,Python中的对象引⽤不包含附属的类型。下⾯的代码是没有问题的:
a = 5
type(a)
#输出结果
int
a = 'foo'
type(a)
#输出结果
str
Python被认为是强类型化语⾔,意味着每个对象都有明确的类型(或类),默许转换只会发⽣在特定的情况下,例如:
a = 4
b = 2.4
a+b
#输出结果
1.6666666666666667
a = '4'
b = 2.4
a+b
#输出结果
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-3-3e3becc9db11> in <module>
1 a = '4'
2 b = 2.4
----> 3 a/b
TypeError: unsupported operand type(s) for /: 'str' and 'float'
在某些编程语言中可能会输出42.4
可以⽤isinstance函数检查对象是某个类型,isinstance也可以⽤类型元组,检查对象的类型是否在元组中:
a = 5.1
isinstance(a, float)
#输出结果
True
a = 5; b = 4.5
isinstance(a, (int, float))
isinstance(b, (int, float))
#输出结果
True
2.2.6 属性和方法
Python的对象通常都有属性(存储在对象内部)和⽅法(对象的附属函数可以访问对象的内部数据)。可以⽤obj.attribute_name访问属性和⽅法:
a = 'foo'
a. #getattr(a, 'split')
2.2.7 二元运算符和比较运算符
如+、-、/、*都为二元运算符:
5 - 7
12 + 21.5
5 <= 2

要判断两个引⽤是否指向同⼀个对象,可以使⽤is⽅法。is not可以判断两个对象是不同的:
a = [1, 2, 3]
b = a
c = list(a)
a is b
#输出结果
True
a is not c
#输出结果
True
因为list总是创建⼀个新的Python列表(即复制),我们可以断定c是不同于a的。使⽤is⽐较与==运算符不同,如下:
a = [1, 2, 3]
c = list(a)
a == c
#输出结果
True
2.2.8 可变与不可变对象
Python中的⼤多数对象,⽐如列表、字典、NumPy数组,和⽤户定义的类型(类),都是可变的。意味着这些对象或包含的值可以被修改,其它的,例如字符串和元组,是不可变的:
a_list = ['foo', 2, [4, 5]]
a_list[2] = (3, 4)
a_list
#输出结果
['foo', 2, (3, 4)]
a_tuple = (3, 5, (4, 5))
a_tuple[1] = 'four'
#输出结果
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-22-2c9bddc8679c> in <module>
1 a_tuple = (3, 5, (4, 5))
----> 2 a_tuple[1] = 'four'
TypeError: 'tuple' object does not support item assignment
2.2.9 标量的类型
Python的标准库中有⼀些内建的类型,⽤以处理数值数据、字符串、布尔值,和⽇期时间。这些单值类型被称为标量类型。下表列出了主要的标量。⽇期和时间处理另外讨论,因为它们是标准库的datetime模块提供的。
这里有张表
2.2.10 数值类型
Python的主要数值类型是int和float。int可以存储任意⼤的数,浮点数使⽤float类型;每个数都是双精度(64位)的值。也可以⽤科学计数法表示:
ival = 17239871
ival ** 6
#输出结果
26254519291092456596965462913230729701102721
fval = 7.243
fval2 = 6.78e-5 #科学计数法
2.2.11 字符串
可以⽤单引号或双引号来写字符串:
a = 'one way of writing a string'
b = "another way"
对于有换⾏符的字符串,可以使⽤三引号,'''或"""都⾏:
c = """
This is a longer string that
spans multiple lines
"""
Python的字符串是不可变的,不能修改字符串:
a = 'this is a string'
a[10] = 'f' # 此时a并没有被修改许多Python对象使⽤str函数可以被转化为字符串:
#输出结果
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-30-cfa170a67205> in <module>
1 a = 'this is a string'
----> 2 a[10] = 'f'
TypeError: 'str' object does not support item assignment
许多Python对象使⽤str函数可以被转化为字符串:
a = 5.6
a
#5.6
s = str(a)
s
#'5.6'
print(s)
#5.6
字符串是⼀个序列的Unicode字符,因此可以像其它序列,⽐如列表和元组(下⼀章会详细介绍两者)⼀样处理:
s = 'python'
list(s)
#输出结果
['p', 'y', 't', 'h', 'o', 'n']
s[:3] #切片
#输出结果
'pyt'
反斜杠是转义字符,意思是它备⽤来表示特殊字符,⽐如换⾏符\n或Unicode字符。要写⼀个包含反斜杠的字符串,需要进⾏转义:
s = '12\\34'
print(s)
#输出结果
12\34
在字符串前⾯加⼀个r,表明字符就是它⾃身,避免反斜杠带来的影响:
s = r'this\has\no\special\characters'
s
#输出结果
'this\\has\\no\\special\\characters'
将两个字符串合并,会产⽣⼀个新的字符串:
a = 'this is the first half '
b = 'and this is the second half'
a + b
#输出结果
'this is the first half and this is the second half'
2.2.12 字节和Unicode
在Python 3及以上版本中,Unicode是⼀级的字符串类型,这样可以更⼀致的处理ASCII和Non-ASCII⽂本。在⽼的Python版本中,字符串都是字节,不使⽤Unicode编码。假如知道字符编码,可以将其转化为Unicode。看⼀个例⼦:
可以⽤encode将这个Unicode字符串编码为UTF-8:
val = "español"
val_utf8 = val.encode('utf-8')
val_utf8
#输出结果
b'espa\xc3\xb1ol'
type(val_utf8)
#输出结果
bytes
如果你知道⼀个字节对象的Unicode编码,⽤decode⽅法可以解码:
val_utf8 = b'espa\xc3\xb1ol'
val_utf8.decode('utf-8')
#输出结果
'español'
虽然UTF-8编码已经变成主流,但因为历史的原因,你仍然可能碰到其它编码的数据:
val.encode('latin1')
#输出结果
b'espa\xf1ol'
val.encode('utf-16')
#输出结果
b'\xff\xfee\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
val.encode('utf-16le')
#输出结果
b'e\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
2.2.13 布尔值
Python中的布尔值有两个,True和False。⽐较和其它条件表达式可以⽤True和False判断。布尔值可以与and和or结合使⽤:
True and True
#输出结果
True
False or True
#输出结果
True
2.2.14 类型转换
str、bool、int和float也是函数,可以⽤来转换类型:
s = '3.14159'
fval = float(s)
type(fval)
#输出结果
float
int(fval)
#输出结果
3
bool(fval)
#输出结果
True
2.2.15 None
None是Python的空值类型。如果⼀个函数没有明确的返回值,就会默认返回None
a = None
a is None
b = 5
b is not None
None也常常作为函数的默认参数:
def add_and_maybe_multiply(a, b, c=None):
result = a + b
if c is not None:
result = result * c
return result
另外,None不仅是⼀个保留字,还是唯⼀的NoneType的实例:
type(None)
#输出结果
oneType
2.2.16 日期和时间
Python内建的datetime模块提供了datetime、date和time类型。datetime类型结合了date和time,是最常使⽤的:
from datetime import datetime, date, time
dt = datetime(2011, 10, 29, 20, 30, 21)
dt.day
dt.minute
根据datetime实例,你可以⽤date和time提取出各⾃的对象:
dt.date()
#输出结果
datetime.date(2011, 10, 29)
dt.time()
#输出结果
datetime.time(20, 30, 21)
strftime函数可以将datetime格式化为字符串:
dt.strftime('%m/%d/%Y %H:%M')
#输出结果
'10/29/2011 20:30'
strptime可以将字符串转换成datetime对象:
datetime.strptime('20091031', '%Y%m%d')
#输出结果
datetime.datetime(2009, 10, 31, 0, 0)

当你聚类或对时间序列进⾏分组,替换datetimes的time字段有时会很有⽤。例如,⽤0替换分和秒:
dt.replace(minute=0, second=0)
#输出结果
datetime.datetime(2011, 10, 29, 20, 0)
因为datetime.datetime是不可变类型,上⾯的⽅法会产⽣新的对象。两个datetime对象的差会产⽣⼀个datetime.timedelta类型:
dt2 = datetime(2011, 11, 15, 22, 30)
delta = dt2 - dt
delta
#输出结果
datetime.timedelta(days=17, seconds=7179)
结果timedelta(17, 7179)指明了timedelta将17天、7179秒的编码⽅式。
2.2.17 if、elif和else
if是最⼴为⼈知的控制流语句。它检查⼀个条件,如果为True,就执⾏后⾯的语句:
x = -1
if x < 0:
print('It is negative')
if后⾯可以跟⼀个或多个elif,所有条件都是False时,还可以添加⼀个else:
if x < 0:
print('It is negative')
elif x == 0:
print('Equal to zero')
elif 0 < x < 5:
print('Positive but smaller than 5')
else:
print('Positive and larger than or equal to 5')
参考资料:
- 《利用Python进行数据分析》