python中的字符串的索引、切片、查找、拆分、替换、修饰、格式化、变形、判断、编码、拼接等
文章目录
- python字符串
- 索引
- 切片
- 字符串的查找
- 1、count 计数功能
- 2、find 查找
- 3、rfind 查找
- 4、index 查找
- 5、rindex 查找
- 字符串的拆分
- 1、partition
- 2、splitlines
- 3、split
- 字符串的替换
- 1、replace
- 2、translate
- 字符串的修饰
- 1、center
- 2、ljust
- 3、rjust
- 4、zfill
- 5、format
- 6、strip
- 7、rstrip
- 8、lstrip
- 字符串格式化
- format()用法
- 1、使用位置参数
- 2、使用关键字参数
- 3、填充与格式化
- 4、精度与进制
- 字符串的变形
- 1、upper
- 2、lower
- 3、swapcase
- 4、title
- 5、capitalize
- 6、expandtabs
- 字符串的判断
- 1、isalnum
- 2、isalpha
- 3、isdigi
- 4、isupper
- 5、islower
- 6、istitle
- 7、isspace
- 8、startswith
- 9、endswith
- 10、split
- python字符串的编码
- 1、encode
- 2、decode
- 字符串的拼接
- join()方法
python字符串
字符串是一个有序的,不可修改的,元素以引号包围的序列。
python字符串的定义:双引号或者单引号中的数据,就是字符串
索引
索引号从0开始,索引的用法,取单个元素时,使用字符串[索引值],索引值为对应元素的索引号
切片
切片的语法:[起始:结束:步长]
字符串[start: end: step] 这三个参数都有默认值,默认截取方向是从左往右的
start:默认值为0;
end : 默认值未字符串结尾元素;
step : 默认值为1;
如果切片步长是负值,截取方向则是从右往左的
字符串的查找
1、count 计数功能
显示自定字符在字符串当中的个数
2、find 查找
返回从左第一个指定字符的索引,找不到返回-1
3、rfind 查找
返回从右第一个指定字符的索引,找不到返回-1
4、index 查找
返回从左第一个指定字符的索引,找不到报错
5、rindex 查找
返回从右第一个指定字符的索引,找不到报错
s = "hello world"
ret = s.count('l') # 统计字符串中该元素的个数
num = s.find('l') # 从左往右找索引
num = s.find('p') # 找不到就返回-1
num1 = s.rfind('l') # 从右往左找索引(索引的位置还是正序的)
num1 = s.rfind('p') # 找不到就返回-1
num2 = s.index('l') # 和find类似,区别在于找不到会报错,而find找不到会返回-1
# num2 = s.index('p') # 找不到就报错
num3 = s.rindex('l') # 和rfind类似,区别在于找不到的话会报错
# num3 = s.rindex('p')#找不到就报错
print(num3)
字符串的拆分
1、partition
把mystr以str分割成三部分,str前,str自身和str后
2、splitlines
按照行分隔,返回一个包含各行作为元素的列表,按照换行符分割
3、split
按照指定的内容进行分割
用的多的主要还是split
s = "I \nLove \nYou"
print(s.partition('Love'))
print(s.splitlines())
# split()按指定内容进行拆分
s = 'hello world python'
ret = s.split(' ')
print(ret)
字符串的替换
1、replace
从左到右替换指定的元素,可以指定替换的个数,默认全部替换
2、translate
按照对应关系来替换内容 from string import maketrans
主要用的多的还是replace
s = 'hello world python'
ret = s.replace('o', '0', 3) # 把o替换成0,换成前3个
print(ret)
# s = 'hello world python'
# intab = 'hello'
# outtab = 'javaa'
# ret = str.maketrans(intab, outtab)
# s2 = s.translate(ret)
# print(s2)
字符串的修饰
1、center
让字符串在指定的长度居中,如果不能居中左短右长,可以指定填充内容,默认以空格填充
2、ljust
让字符串在指定的长度左齐,可以指定填充内容,默认以空格填充
3、rjust
让字符串在指定的长度右齐,可以指定填充内容,默认以空格填充
4、zfill
将字符串填充到指定的长度,不足地方用0从左开始补充
5、format
按照顺序,将后面的参数传递给前面的大括号
6、strip
默认去除两边的空格,去除内容可以指定
7、rstrip
默认去除右边的空格,去除内容可以指定
8、lstrip
默认去除左边的空格,去除内容可以指定
'''
center:让字符串在指定的长度居中
如果不能居中则左短右长,默认填充为空格
可以设置成其它的填充
'''
# s = 'hello world'
# ret = s.center(30, '*')
# print(ret)
'''
ljust:让字符串在指定的长度左对齐
可以指定填充内容,填充右边)
rjust:与ljust相同,但是是右对齐
'''
# s = 'hello world'
# ret = s.ljust(30, '^')
# ret1=s.rjust(30,'^'
# print(ret)
# print(ret1)
'''
zfill:让字符串填充到指定的长度
不足的地方用0从左开始填充
'''
# s = 'hello world'
# ret = s.zfill(20)
# print(ret)
'''
strip:默认去除两边的空格
去除内容可以指定
'''
# s = ' hello world '
# print(s)
# ret = s.strip()
# print(ret)
'''
rstrip:默认去除右边的空格
lstrip:默认去除左边的空格
去除内容可以指定
'''
s = '*******hello world**********'
print(s)
ret = s.rstrip('*')
print(ret)
ret1 = s.lstrip('*')
print(ret1)
字符串格式化
format()用法
1、使用位置参数
2、使用关键字参数
3、填充与格式化
4、精度与进制
# msg = '大家好我叫{},今年{}岁了'
# print(msg.format('李嘉豪', 10))
#
# msg1 = '我今年{1}了,我的名字是{0},我叫{0},今年{1}岁了'
# print(msg1.format('李嘉豪', 21))
# print('我叫{},今年{}岁了,老家在{}'.format('李嘉豪', 20, '江西'))
# msg = '大家好我叫{name}!我今年{age}岁了!'
# print(msg.format(age=19, name='李嘉豪'))
# 使用关键字参数,就可以不按位置顺序
# :[填充字符][对齐方式 <^>][宽度]
# msg = '大家好我叫{:*<10}!我今年{: ^10}岁了!身高是{:>10}米'
# print(msg.format('李嘉豪', 21, 1.78))
# 精度
# long = 1.321
# wide = 0.98
# area = long * wide
# print('长方形的长是{:.2f}cm,宽是{:.3f}cm,面积是{:.5f}平方厘米'.format(long, wide, area))
# 进制
# print('二进制:{:b}'.format(10))
# print('八进制:{:o}'.format(20))
# print('十六进制:{:x}'.format(30))
# 百分号格式
name = '李嘉豪'
age = 21
height = 1.78
weight = 70
msg = "姓名:%s,年龄:%d,身高:%.2f,体重:%d公斤,目前学习的进度是10%%" % (name, age, height, weight)
print(msg)
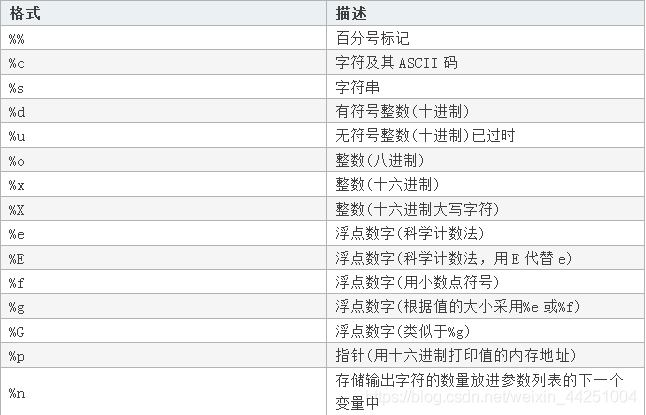
字符串的变形
1、upper
将字符串当中所有的字母转换为大写
2、lower
将字符串当中所有的字母转换为小写
3、swapcase
将字符串当中所有的字母大小写互换
4、title
将字串符当中的单词首字母大写,单词以非字母划分
5、capitalize
只有字符串的首字母大写
6、expandtabs
把字符串中的 tab 符号(’\t’)转为空格,tab 符号(’\t’)默认的空格数是 8
s10 = 'hello Python'
print(s10.upper())
print(s10.lower())
print(s10.swapcase())
print(s10.title())
print(s10.capitalize())
s11 = 'hello\tpython'
print(s11.expandtabs())
字符串的判断
1、isalnum
判断字符串是否完全由字母或数字组成
2、isalpha
判断字符串是否完全由字母组成
3、isdigi
判断字符串是否完全由数字组成
4、isupper
判断字符串当中的字母是否完全是大写
5、islower
判断字符串当中的字母是否完全是小写
6、istitle
判断字符串是否满足title格式
7、isspace
判断字符串是否完全由空格组成
8、startswith
判断字符串的开头字符,也可以截取判断
9、endswith
判断字符串的结尾字符,也可以截取判断
10、split
判断字符串的分隔符切片
s = 'hello python'
print(s.isalnum())
print(s.isalpha())
print(s.isdigit())
print(s.isupper())
print(s.islower())
print(s.istitle())
print(s.isspace())
print(s.startswith('he', 0, 7))
print(s.endswith('n', 0, 12))
python字符串的编码
1、encode
编码,将字符串转换成字节码。str–>byte
2、decode
解码 ,将字节码转换成字符串。 byte–>str
Unicode是一个规则,UTF-8是具体的实现。
英语国家发明计算机,编码表只有127个字母,这个编码表被称为ASCII编码,一个编码占一个字节大小。
中国制定了GB1212编码。
而所有语言都统一到了一套编码里,就是Unicode,一个编码占2个字节。
UTF-8把Unicode编码转化,常用的英文字母占1个字节,汉字通常是3个字节。
s = '我'
s1 = s.encode()
print(s1) #b'\xe6\x88\x91'
print(s1.decode()) #我
s2 = s.encode(encoding='gbk')
print(s2) #b'\xce\xd2'
print(s2.decode(encoding='gbk')) # 解码的时候也是用encoding='gbk' #我
字符串的拼接
join()方法
将元素以指定的链接符拼接成一个新的字符串
s = 'hello'
print('_'.join(s)) #h_e_l_l_o