python----MQ--实现通信
首先准备工作:pip install pika安装rabbitmq–python的依赖
这里的话就是要先看一下官网出的案例:
先了解一下官网给出的定义:
RabbitMQ是一个消息代理。它的工作就是接收和转发消息。你可以把它想像成一个邮局:你把信件放入邮箱,邮递员就会把信件投递到你的收件人处。在这个比喻中,RabbitMQ就扮演着邮箱、邮局以及邮递员的角色。
- 生产(Producing)的意思就是发送。发送消息的程序就是一个生产者(producer)。我们一般用"P"来表示:
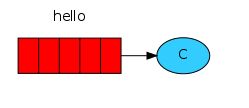
- 队列(queue)就是存在于RabbitMQ中邮箱的名称。虽然消息的传输经过了RabbitMQ和你的应用程序,但是它只能被存储于队列当中。实质上队列就是个巨大的消息缓冲区,它的大小只受主机内存和硬盘限制。多个生产者(producers)可以把消息发送给同一个队列,同样,多个消费者(consumers)也能够从同一个队列(queue)中获取数据。队列可以绘制成这样

- 在这里,消费(Consuming)和接收(receiving)是同一个意思。一个消费者(consumer)就是一个等待获取消息的程序。我们把它绘制为"C":
需要指出的是生产者、消费者、代理需不要待在同一个设备上;事实上大多数应用也确实不在会将他们放在一台机器上。
通过案例来熟悉它:
Hello World
接下来我们用Python写两个小程序。一个发送单条消息的生产者(producer)和一个接收消息并将其输出的消费者(consumer)。传递的消息是"Hello World"。
下图中,“P”代表生产者,“C”代表消费者,中间的盒子代表为消费者保留的消息缓冲区,也就是我们的队列。
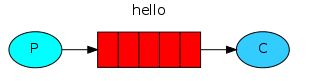
生产者(producer)把消息发送到一个名为“hello”的队列中。消费者(consumer)从这个队列中获取消息。
发送
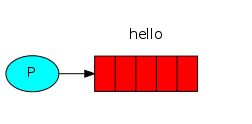
我们第一个程序send.py会发送一个消息到队列中。首先要做的事情就是建立一个到RabbitMQ服务器的连接。
接收
我们的第二个程序receive.py,将会从队列中获取消息并将其打印到屏幕上。
这次我们还是需要要先连接到RabbitMQ服务器。连接服务器的代码和之前是一样的。
下一步也和之前一样,我们需要确认队列是存在的。我们可以多次使用queue_declare命令来创建同一个队列,但是只有一个队列会被真正的创建。
通常我们谈到队列服务, 会有三个概念, 发消息者 , 队列 , 收消息者 . ( 消息 本来也应该算是一个独立的概念, 但是简单处理之下, 它可能并没有太多的内涵)
流程上是, 发消息者 把消息放到 队列 中去, 然后 收消息者 从 队列 中取出消息.
RabbitMQ 在这个基本概念之上, 多做了一层抽象, 在 发消息者 和 队列 之间, 加入了 交换器 (Exchange) . 这样 发消息者 和 队列 就没有直接联系, 转而变成 发消息者 把消息给 交换器 , 交换器 根据调度策略再把消息再给 队列 .
当然, 多一层抽象会增加复杂度, 但是同时, 功能上也更灵活. 事实上, 很多时候面对具体场景时, 在这种"四段式"的结构下, 你可选择的方案不止一种的. 不过也不必过于担心, 在一些自我规定的"原则"之下, "正确"的方案也不会那么纠结.
Producing : 生产者, 产生消息的角色.
Exchange : 交换器, 在得到生产者的消息后, 把消息扔到队列的角色.
Queue : 队列, 消息暂时呆的地方.
Consuming: 消费者, 把消息从队列中取出的角色.
Message :RabbitMQ 中的消息有自己的一系列属性, 某些属性对信息流有直接影响.
在使用过程中, 我们通常还会关注如下的机制:
持久化 :服务重启时, 是否能恢复队列中的数据.
==调度策略 ==:交换器如何把消息给到哪些队列, 是每个队列给一条, 或者把一条消息给多个队列.
==分配策略 ==: 队列面对消费者时, 如何把消息吐出去, 来一个消费者就把消息全给它, 还是只给一条.
状态反馈 :当消息从某一个队列中被提出后, 这个消息的生命周期就此结束, 还是说需要一个具体的信号以明确标识消息已被正确处理.
推荐一个地址有详细的策略:https://blog.csdn.net/summerhust/article/details/46325107
send.py的完整代码:
import pika
connection =
pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
receive.py的完整代码:
import pika
connection =
pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
现在我们可以在终端中尝试一下我们的程序了。
首先我们启动一个消费者,它会持续的运行来等待投递到达。
注意:先运行我们的receive.py文件
然后启动生产者,生产者程序每次执行后都会停止运行。
启动send.py
成功了!我们已经通过RabbitMQ发送第一条消息。你也许已经注意到了,receive.py程序并没有退出。它一直在准备获取消息,你可以通过Ctrl-C来中止它。
我用的版本估计比较高所以在使用的时候一些函数里面的参数发生了变化,下面是我的版本的代码:
send.py
import pika
#创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
#建立通道
channel = connection.channel()
#创建队列
channel.queue_declare(queue='hello')
#往hello队列中添加消息
#exchange代表交换机,空字符代表默认交换机
#routing_key表示你要发送消息的队列
#body表示你要发送的消息内容
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World'
)
print("[x] Sent 'Hello World'")
#关闭连接
connection.close()
receive.py
import pika
#创建链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
#建立通道
channel = connection.channel()
#回调函数
def callback(ch,method,properties,body):
print("[x] Received {}".format(body))
#绑定消息
'''
告诉RabbitMQ这个回调函数(callback)将会从名为"hello"的队列中接收消息
auto_ack=True:如果设置为真,将使用自动确认模式。
'''
channel.basic_consume(on_message_callback=callback,
queue='hello',
auto_ack=True
)
print('[*] Waiting for messages. To exit press CTRL+C')
#我们运行一个用来等待消息数据并且在需要的时候运行回调函数的无限循环
channel.start_consuming()
结果:
先运行receive.py
send.py
回到我们的receive的控制台:
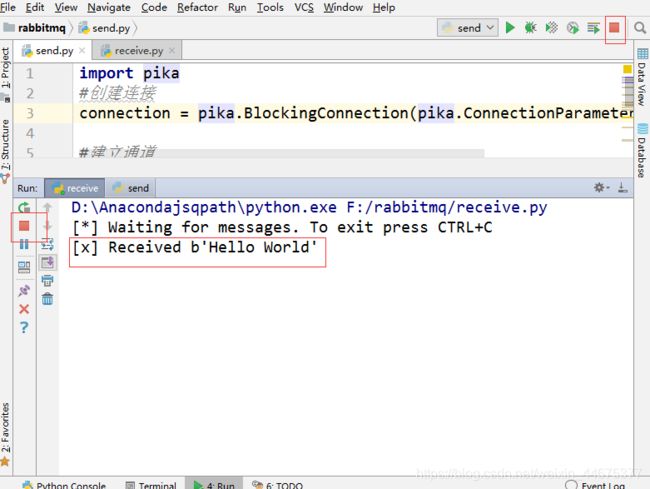
接收到了来自send方的消息,其次还有就是我们的receive方并没有停,那么我们再试着多运行几次send.py
建议:
遇到函数没有你已知的参数,说明版本更新,前辈们想到了更好的寓意去代表,那么在不知道的情况下怎么继续风雨无阻的行走呢,按住CTRL点进去看源码,试着去读英文,见的多了慢慢就知道了。搞懂了源码里给的参数,那不就手到擒来了。实在没办法的翻译会用吧,但是翻译的也不能全相信,要根据自己的判断去读源码是想表达什么意思。
注意:详细的介绍我没有一一列出来,给一个地址有详细的解释:http://rabbitmq.mr-ping.com/tutorials_with_python/[1]Hello_World.html