** Hadoop框架基础(三)
上一节我们使用eclipse运行展示了hdfs系统中的某个文件数据,这一节我们简析一下离线计算框架MapReduce,以及通过eclipse来编写关于MapReduce的代码,在Hadoop第一小节内容中,我们成功运行了官方的WordCount的案例,这一节我们自己编写代码走一下这个流程。
本节目标:
* 了解mapreduce原理
* 编写wordcount的mapreduce案例
** MapReduce简述及架构

上图简单的阐明了map和reduce的两个过程或者作用,虽然不够严谨,但是足以提供一个大概的认知,map过程是一个蔬菜到制成食物前的准备工作,reduce将准备好的材料合并进而制作出食物的过程,举个例子(方案3可以对比蔬菜这个图片做一个简单理解):
任务:我想检索全国的身份证信息,将姓名重复最多的名字统计出来。
想要完成这个任务,我们想一下方案
方案1:将全国的身份信息先搜集到某个文件中(比如搜集到“身份信息.txt”文件中),然后写一个程序,遍历该文件所有的名字,统计出名字出现最多的那个,并输出出来。
方案2:多线程,并发同时遍历处理该文件,但前提是:该计算机是物理多核CPU;而且还要手动分割文件,不然会出现内容重复统计,再者还要手动合并结果,做数据同步,效率比1高,但是代码逻辑比1麻烦的多。
方案3:我还是使用“方案1”的代码,把“方案1”的代码部署到多台计算机上,每台计算机遍历身份信息文件的一部分,统计出结果后,所有计算机做一个合并就OK了,但问题是,如何切分文件给所有的计算机,怎么切分合理,所有计算机的结果合并谁来处理,怎么合并。
其实mapreduce过程就是方案3。我们要学习的,也就是别人制定好的方案,并研究其合理性。
** MapReduce代码编写
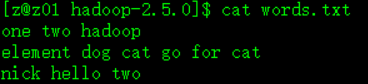
目标:计算words.txt文档中的所有单词出现的次数,单词如图:
代码组成部分:
* map
如下图,首先创建WordCountMapper类,继承自org.apache.hadoop.mapreduce.Mapper类,然后复写其map方法,这个map方法会在整个框架需要进行map运算时自动调用的。map方法中,需要做的操作是将单词和出现次数放入map映射,比如这个例子,map过程结束后,出现的结果是:
这里需要注意的是:
1、单词作为键
2、单词不管出现了几次,该键所对应的值都为1
3、map方法的参数,key为当前单词,value为分配给当前map任务的整个文本内容,所以后边要做一个split分割,后边的正则表达式的意思为:单词按照任意空白字符分割。

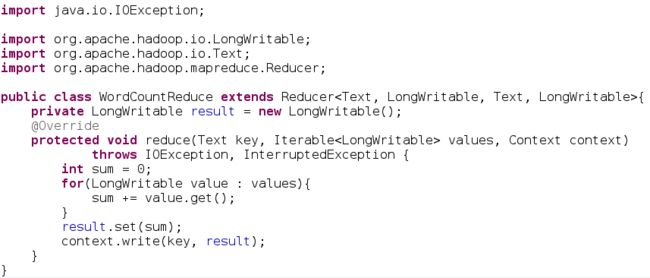
* reduce
如下图,首先创建WordCountReduce类,继承自org.apache.hadoop.mapreduce.Reducer类,然后覆写其reduce方法,这个reduce方法会在整个框架需要进行reduce运算时自动调用的。reduce方法中,需要做的操作是将map映射好的单词做合并处理(在shuffle过程讲解前,只能这样不太严谨的表述),reduce方法的key参数是当前传入到reduce方法中的单词,比如:cat这个单词,接着values参数,是这个cat单词所对应的映射,此例子为两个1。reduce过程,是将如下数据进行合并运算:
那么对于cat这个单词来讲,reduce中的key参数就代表cat,values参数就代表[1, 1],如此便可统计合并。最后出来的结果,比如cat这个单词,那么就是
可能的疑惑:
1、map过程产生的
2、如果我这个words.txt文件有10T这么大,那么按照HDFS存储分割成好多个128M分布存储在各个主机,那到底是怎么来协调的。
如上两个问题需要涉及到map和reduce的之间的一些细节,即shuffle过程(后续在说)。
* job
编写完map和reduce代码后,最后需要创建一个任务来执行mapreduce运算,如下图,首先创建一个App类,继承自Configured并实现Tool接口,这里会让你覆写run方法。在run方法中,我们需要做的是:
1、创建配置实例Configuration
2、创建Job任务并设置Job任务所在类为App.class
3、为当前Job设置数据输入路径inPath
4、为当前Job设置map运算所在的那个类为WordCountMapper.class,设置map任务输出的结果类型,
5、设置Job的reduce运算所在类,为WordCountReducer.class,设置reducer输出结果
6、设置Job任务的输出目录outPath
7、如果Job任务成功执行完毕,则返回0,否则返回1。
8、调用时,将输入目录和输出目录传入到args参数中,此时我直接默认:
args = new String[]{"/input/words/words.txt", "/output/"};
最后通过如下两行代码,执行任务并退出系统。
int status = ToolRunner.run(app.getConf(), app, args);
System.exit(status);

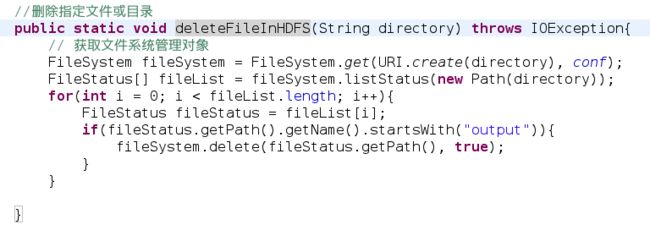
其中的deleteFileInHDFS方法为之前自定义的Tools类中的方法,方法可以在HDFS系统中删除传入的目录,在这个例子里,每次执行都删除之前创建出来的output目录,原因在于在执行某个job任务前,输出目录不能为已经存在的目录,所以要么手动删除之前的目录,要么手动指定新目录。在此为了方便我选择了前者(因为对于本例来讲,之前那些输出数据不需要了)。
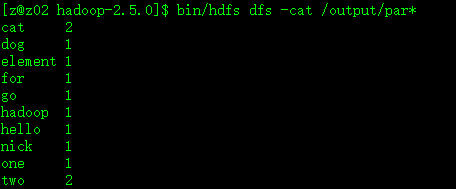
接着就可以运行该案例了,注意运行时,要先开启hdfs和yarn的相关服务,运行完成后,通过查看output目录的结果如图:
以上便完成了mapreduce关于wordcount单词统计的编码和运行。接下来,我们回忆一下之前使用官方examples.jar运行的单词统计任务,使用的命令是:
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/ /output/
那么我们也想使用类似的方式把自己的代码打成jar包之后调用,怎么玩呢。首先,既然是想手动传入输入数据和输出目录,那么就先把如下代码注释掉:

接着,我们开始打包程序:
1、在Eclipse中,依次点击:File -- Export -- Java -- JAR file -- Next
2、出现如下界面,这里我把JAR的输出目录改为:/home/z/Desktop/MyWordCount.jar,同时注意选择你要打包的源码,即src/main/java

3、下一步,再下一步,出现如下界面,注意红框部分,这里我们选择一个jar包的入口类,如果不选择,那么我们执行jar包时,还需要手动输入哪个类为入口类,最后Finish。(如果你的红框内容被遮挡住了,先Cancel下,然后全屏你的虚拟机系统,再次来到这个界面就能看到了)

4、桌面生成了一个Jar文件则成功。接下来我们通过这个jar来运行一下,输入指令:
$ bin/yarn jar /home/z/Desktop/MyWordCount.jar /input/words/words.txt /output/,如图所示,开始运行任务:

最后查看该任务结果:

成功运行!
** 最后我们对比两条命令
运行官方jar:$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/ /output/
运行自己jar:$ bin/yarn jar /home/z/Desktop/MyWordCount.jar /input/words/words.txt /output/
* 运行官方的jar时,除了指定某个位置的jar包运行在yarn平台上之外,还提供了wordcount任务名称,而我们自己写的没有,是因为我们封装的jar就一个单词统计任务,而且在封装jar时指定了主类。
* 运行官方提供的jar中的wordcount任务,提供的数据输入目录为/input/并没有指定哪个具体文件,是因为官方的demo中编写了自动遍历指定目录中所有可用的统计资源,而我们的代码中没有写这样的功能,所以请直接指定文件的绝对路径。
** 总结
本节需要大概了解mapreduce的运行原理,并成功使用eclipse编写mapreduce的单词统计任务,使之成功运行。最后完成jar包封装并成功调用。
IT全栈公众号:

QQ大数据技术交流群(广告勿入):476966007

下一节:Hadoop框架基础(四)