coursera NLP学习笔记之week2 语言模型
接触NLP和ML也有近两年了,之前总是以为会了ML,NLP的问题就不在是问题了,的确ML的一个应用方向是NLP,可是我现在要说我错了,ML能够让你处理NLP更为便捷,而不是它就能够解决NLP问题了,所以NLP还是要老老实实的去学,真的是做学问没有任何的捷径。所以转过头来看NLP,来重新认识语言模型。
语言模型:目的是为了找到一个句子或者一个单词序列出现的概率,有时候也会计算一个序列之后将要出现单词的概率。
计算由N个单词组成的序列的概率:P(W) = P(w1,w2,w3,w4,w5…wn) 下面是语言模型的表示: P(W) or P(wn|w1,w2…wn-1)
定义完成了,下面的问题是:如何求这个联合概率?比如说:P(its, water, is, so, transparent, that)
我们首先想到的是什么?我想到的是链式规则P(x1,x2,x3,…,xn) = P(x1)P(x2|x1)P(x3|x1,x2)…P(xn|x1,…,xn-1);
也可以用这个公式来表示:
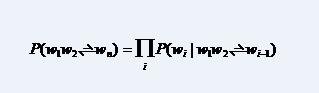
这个计算量是不是太大?来吧!马尔科夫!

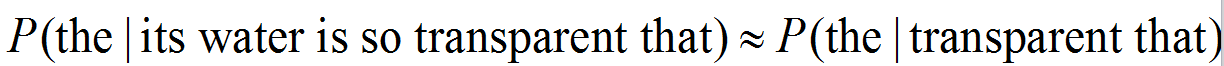
上边的式子一个是一元模型,一个是二元模型。三元模型触类旁通咯!
拼写纠错和噪声信道
拼写的任务:
拼写错误检测,拼写错误纠正(自动纠正,推荐正确单词,推荐正确单词列表)。
拼写错误的类型:
非词错误:graffe-》giraffe,对于非词错误,就是指不存在于字典中的单词判定为非词错误,字典越大越好,对于非词错误的纠正,就是给出候选词语,给出与错误单词比较相近的单词,最后找到最好的那个候选词。有两种方法:shortest weighted edit distance , highest noisy channel probability
真词错误:
印刷错误:three->there
认知错误(同音字):piece->peace,too->two
对于真词错误,给每个单词生成相应的候选集合,规则是挑选相似发音的,或者相似拼写的,集合中也要包含单词本身
选择最佳候选单词:噪声信道,或者是分类
拼写错误率:
网络查询 26%
noisy channel
首先,我们观察到一个被误拼的单词的观察值,为了找到正确的单词w,就需要以下过程:
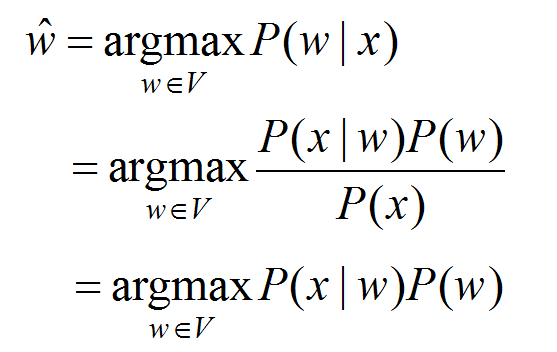
noisy channel :

评估:一些拼写错误检测集
http://en.wikipedia.org/wiki/Wikipedia:Lists_of_common_misspellings
http://hosho.ees.hokudai.ac.jp/~kubo/Rdoc/library/utils/html/aspell.html
http://ota.ahds.ac.uk/desc/0643
http://norvig.com/ngrams/spell-errors.txt
上述corpus没有认真看。有时间要回来看。
真词错误:Real-wordspelling errors