请及时关注“高效运维(微信ID:greatops)”公众号,并置顶公众号,以免错过各种干货满满的原创文章。
作者简介:
汪华
现任腾讯SNG社交网络运营部高级工程师,负责多媒体增值业务的运维工作和运维自动化平台建设。
目录
一、tcpdump基础
二、自动抓包工具的实现
三、基于访问关系的业务架构树
导语:
熟悉运维的兄弟姐妹都知道tcpdump是一款抓包分析利器,其灵活的过滤规则和对表达式的支持能够让我们在众多的数据报文中抓取到理想的关键信息。
本文在介绍tcpdump的基本使用方式的同时,会向大家说明海量业务中tcpdump进阶应用场景。
在开始阅读之前请兄弟姐妹们现在脑海中思考一下这几个问题,看看读完本文后会有些什么收获。
1、tcpdump怎么使用?
2、tcpdump在海量业务中又怎么使用?
3、tcpdump除了抓包还能做什么?
一、tcpdump基础
tcpdump是一个对网络数据包进行截获的包分析工具。
tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、端口等的过滤,并支持与、或、非逻辑语句协助过滤有效信息。
命令使用规则如下:
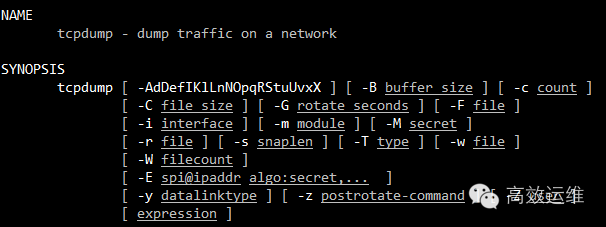
过滤方式有很多,可以依据所需设置过滤条件,较常用的三种:
1、可以按host过滤,例如:
tcpdump -i eth1 -n -X src host 10.19.66.62
2、可以按port过滤,例如:
tcpdump -i eth1 -n -X src host 10.19.66.62 and dst port 80
3、可以按protocol过滤,例如:
tcpdump -i eth1 -n -X src host 10.19.66.62 and dst port 80 and tcp
下面来看一下tcpdump过滤规则的具体使用:
我们在服务器10.219.153.215上搭建了一个http服务用来作为服务端,10.19.66.62作为客户端客户端对其发起访问。我们使用前面提到的按host 10.19.66.62、port 80以及protocol tcp的组合条件来执行tcpdump。
tcpdump -i eth1 -n tcp port 80 and host 10.19.66.62
点击可查看高清大图
不同的协议类型有不同的数据包格式显示,以tcp包为例,通常tcpdump对tcp数据包的显示格式如下:
src > dst: flags data-seqno ack window urgent options
src > dst:表明从源地址到目的地址
flags:TCP包中的标志信息,S 是SYN标志,,F (FIN),P (PUSH),R (RST),”.” (没有标记)
data-seqno:是数据包中的数据的顺序号
ack:是下次期望的顺序号
window:是接收缓存的窗口大小
urgent:表明数据包中是否有紧急指针
options:选项
执行抓包过程中输出的这八行数据其实包含了tcp三次握手和四次挥手的交互过程,详细分析下看看:
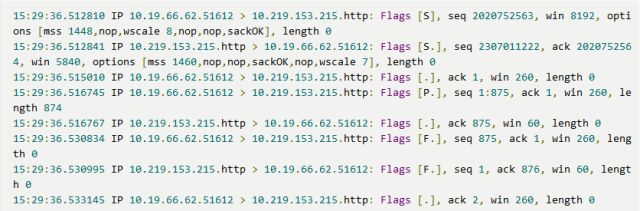
点击可查看高清大图
第一至三行为建立链接的三次握手过程,包状态为:[S]、[S.]、[.],第四至五行为传输数据的过程,包状态为[P.]、[.];第六至八行为关闭链接的四次挥手过程(ack延迟发送未禁用,所以这里只看到三个包),包状态为[F.]、[F.]、[.]。
第一行:客户端62向服务器215发送了一个序号seq 2020752563给服务端;
第二行:服务端收到后将序号加一返回ack 2020752564;
第三行:客户端检查返回值正确,向服务端发ack 1,建立了链接;
第四行和第五行:具体的数据交互,tcpdump命令-x可以显示出具体内容;
第六行:客户端发一个序号seq 875,说明要断开链接;
第七行:服务端在收到后序号加一返回ack 876,同意断开链接;
第八行:客户端检查返回值正确,向服务端发ack,链接断开。
以上的分析是使用基本的过滤条件组合获取的,如果想要获取到限制条件更严格的报文数据应该怎么写命令呢?比如在数据交互时状态为[P.]. 即PSH-ACK,如果我们要抓取flag为[P.]的包应该怎么实现呢?
这里先挂一下tcp包头的桢格式(详解可参考TCP/IP协议),以便进一步说明如何使用tcpdump的过滤功能,头部固定为20字节,每行4字节,根据协议规则可以看到各个字节中存放的内容的含义。
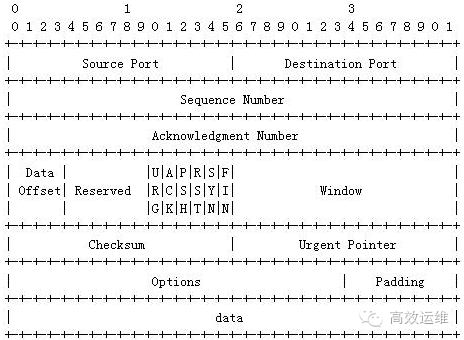
图中控制标志位在第13字节(从0开始计数). 从右往左这些位被依次编号为0到7, 而PSH位在3号,ACK在第4位,因此我们想抓取状态为[P.]的包表达式应写为tcp13=18+8。
执行命令tcpdump -i eth1 -n -X src host 10.19.66.62 and dst port 80 and tcp13=24,此时加上-X参数可以以16进制和ASCII码形式打印出包数据,便于观察。
抓取到的数据如下图,可以看到很方便的抓到了特定状态的包。
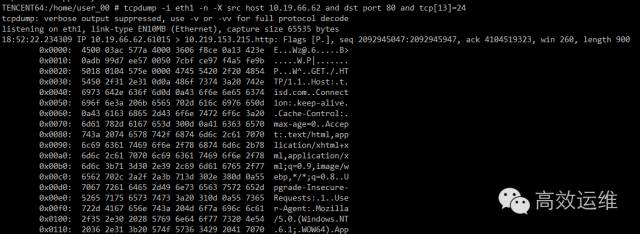
点击可查看高清大图
如果要抓取业务中的get请求包,怎么实现呢?首先查ASCII码表得”GET+空”的十六进制是0x47455420,因此表达式应为tcp[20:4]=0x47455420。
执行命令tcpdump -i eth1 -n -A src host 10.19.66.62 and dst port 80 and tcp[20:4]=0x47455420,此时加上-A参数以ASCII码方式显示数据包。
抓取到的输出如下如,可以看到get请求的具体信息了。以此推论,我们还可以把tcpdump用来统计get、post请求的访问次数等。
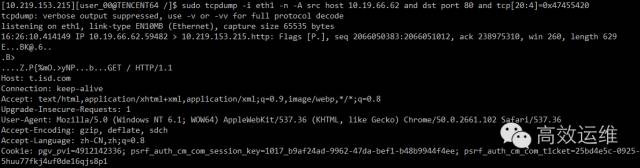
点击可查看高清大图
二、自动抓包工具的实现
第一部分中讲解了tcpdump的一些基本用法和过滤方式,但都还停留在命令行层面。
那么在海量运维系统中如何让tcpdump发挥其作用?一个命令又是怎么来构建访问关系的分析平台?构建平台后又是怎么利用分析结果的?
这里要先说明一下我们业务中所使用的一款自动抓包工具的实现原理。
抓包工具由两部分脚本组成,调度脚本run.sh和工作脚本access.sh:
调度脚本通过权衡服务器的负载状况来控制工作脚本的执行计划;
工作脚本实现tcpdump命令的基础封装。
核心实现是根据服务器监听的TCP和UDP端口,对抓取的报文进行分析后,将分析结果上报到网管,其工作原理如下流程图:

1、定时执行调度脚本
业务的访问是随机并持续的,采用抽样抓包的方式来获取访问关系数据。
所以设定为每三十分钟执行一次调度脚本,将脚本的执行写入到crontab中:/30 *
![]()
2、负载判决
短持续的抓包指令会带来一定的负载消耗,所以抓包的执行需要避开服务器高负载状态。
因此调度脚本需要进行负载判决,每次执行前判断负载是否在可执行抓包的阈值内。
此时计算cpu负载,代码如下图:
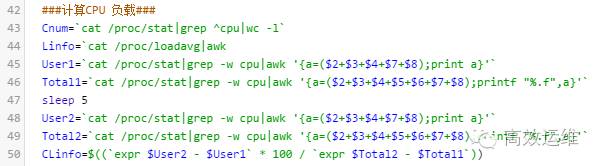 点击可查看高清大图
点击可查看高清大图
基本原理是采样两个足够短的时间间隔的CPU快照来计算这段时间内的CPU平均使用率作为服务器当前的CPU负载:
cat /proc/stat | grep ^cpu得到cpu的信息
used1=user+nice+system+irq+softirq
total1=user+nice+system+idle+iowait+irq+softirq
sleep 5秒
再次cat /proc/stat | grep ^cpu得到cpu的信息
used2=user+nice+system+irq+softirq
total2=user+nice+system+idle+iowait+irq+softirq
得到cpu在5秒内的平均使用率:
(cpu_used2 - cpu_used1) / (cpu_total2 - cpu_total1) * 100%
得到CPU的使用率后就可以进行判决了,可以假定阈值为90%,在负载阈值内即可启动抓包脚本access.sh,否则终止。
示例代码如下:
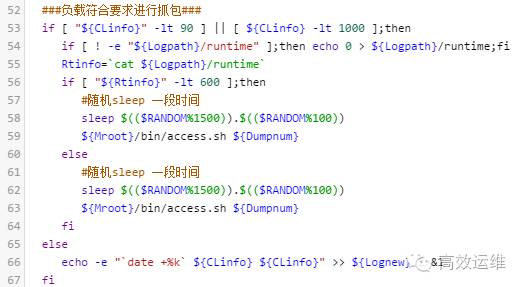
点击可查看高清大图
3、读取服务器的网络接口和IP地址
此处用来获取网卡和对应的IP地址,一般抓取内网IP即可。
![]()
点击可查看高清大图
4、获取服务器监听的TCP/UDP端口
示例代码如下:需要排除掉绑定IP为local的部分
![]()
点击可查看高清大图
5、执行抓包
此处就到了返璞归真的时候了,运用第一部分讲到的tcpdump过滤基础设定好过滤条件,后面的工作就是按条件组合来获取想要的报文数据了。此处设定了空包、端口出入包、入包、出包、所有包的几个条件。
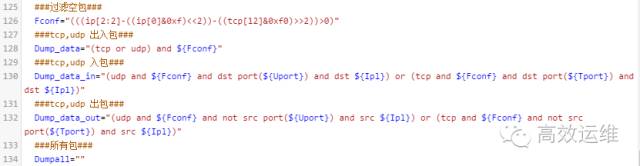
点击可查看高清大图
执行抓包后将数据结果按一定的结构组合上报到网管属性。

点击可查看高清大图
以上就是自动抓包工具的工作原理和实现方式,将此工具嵌入在服务器的初始化部署中,所有服务器在工作的同时可以上报业务的访问关系数据。
至此就完成了对所有服务器访问报文的上报和收集,后续的进阶应用都是在此基础上发展起来的。
三、基于访问关系的业务架构树
前文提到的自动抓包工具获取分析的报文数据已经上报到了网管系统,对一个业务而言,有了访问关系数据基础,我们就可以将模块间服务器的访问关系绘制图谱,业务架构树也就应运而生。
以访问关系作为骨架,业务模块作为肢体,通过图形化模型来展示业务架构,一眼就能获取更多的运营信息数据。
从访问关系中就可以看到业务请求的流转方向,对不合理的调用架构比如环状或者往复迂回的调用采取优化,可以降低关键模块的请求压力。
业务架构树的绘制原理可以分为以下步骤:
1、IP维度汇聚为功能模块维度
一个业务由若干功能模块组成,功能模块由若干服务器提供业务支撑。
前文提到的抓包数据是按IP维度上报的,所以首先需要按CMDB的数据汇聚出业务模块的访问关系,这里按IP维度取并集即可得到。汇聚之后以模块样式呈现在架构树中。
模块的附加信息包含了几种运维管理平台的抽象信息,除了各种跳转接口以外,容量信息以能量条的形式展现(绿色为低负载<30%,蓝色为正常负载30%
注:本文只讲解和tcpdump相关的部分,其他的功能组成等以后的文章再做说明。
2、确定主被调模块以及访问关系
有了功能模块的呈现后,平台就可以对模块附加上访问关系的连线。
前文提到抓包数据的分析结果是以这种形式“本机IP 源IP 目标IP 包大小 时间戳 源端口 目的端口 包量 协议 方向”上报到网管的。
按模块汇聚后,本机IP等于源IP时,目标IP汇聚的模块即为“被调”;针对这次调用本机IP或源IP汇聚的模块即为“主调”;主调到被调的方向即为主被调的“访问关系”。
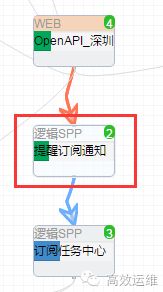
下图就是一个连接关系的确立模型:A->B->C
对A->B调用来说,A为主调,B为被调,->为从A到B的访问关系;
对B来说既是A->B关系中的被调又是B->C关系中的主调。所以访问关系连线上来看有入也有出。
对于TCP协议的访问主被调的访问关系是明确的,这里补充说明下UDP协议的服务怎么来确定主被调的。
UDP协议是面向无连接的,服务端绑定端口(也可能是一个端口段),在众多的抓包数据中,可以通过聚类的方式将端口或者端口段汇聚出来。对提供服务的集合而言,通过聚类得到了服务端,也就确定了架构树中的被调模块了。
3、选取业务自动绘制
经过1、2的原子说明后,就可以整体来看一个业务的架构树形态了。
在CMDB上选择一个业务导入绘制架构树,平台根据抓包关系汇聚出各主调->被调的节点和连线,然后通过排列算法将这些节点和连线组合,最终呈现出一份业务架构树模型。
如下图所示:
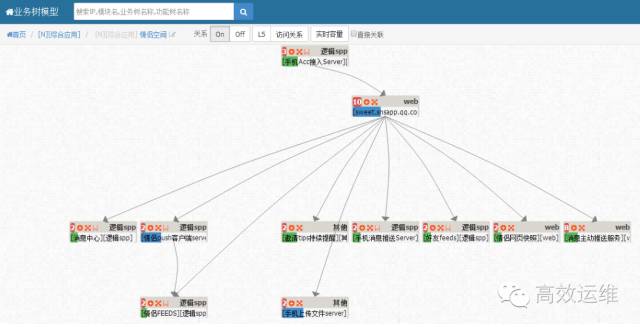
点击可查看高清大图
总结
文章内容也基本回答了我对最初几个问题的理解。从tcpdump入门到绘制业务访问拓扑视图,是在海量运维沉淀出来的经验。
对于日常运维工作帮助较大,如快速定位故障节点,同时沉淀的访问关系数据也广泛地应用在其他运维高阶场景中如资源回收、监控、大范围告警关联分析等等。本文旨在抛砖引玉,希望对大家有帮助