- nest.js实战之集成Apple登录
crayon-shin-chan
surprise#nest.jsapplenestjs
1.简介https://developer.apple.com/documentation/sign_in_with_apple/sign_in_with_apple_rest_api/verifying_a_userApple登录也是符合OAuth2规范的,但是我们不需要执行所有的步骤,只需要解析idToken获取用户信息即可Apple登录时用户可以选择是否隐藏邮箱,如果隐藏邮箱,则获取的邮箱是
- 鬼谷子:人有四种,你是哪种?
永泉说鬼谷
鬼谷子原文:粤若稽古,圣人之在天地间也,为众生之先。观阴阳之开阖以名命物,知存亡之门户,筹策万类之终始,达人心之理,见变化之朕焉,而守司其门户。译文:从古至今,生活在天地之间的圣人,就是要成为众人的先导。通过观察阴阳开阖的变化来对事物作出判断,并进一步了解事物生存和死亡的关键。策划事情发展的开头与结尾,通晓其中的人性的之理,通过事物发展过程中的微小变化,而守住事物发展的关键要害。(1)如何做圣人人
- HTML之创建容器和表格
一百天成为python专家
java开发语言前端csshtmlhtml5
创建容器为了让网页的布局更加美观,HTML提供了容器的概念,即在网页中占用一块区域,在此区域内可以添加多种标签,且这些标签只会在该区域内显示,使得标签有了各自的容器,能在各自的区域内显示内容。标签在HTML中使用标签来建立一个容器。其使用形式如下:kdiv>其他标签被标签所包含的标签都隶属于同一个容器,当使用标签设置属性样式(即style通用样式)时整个容器都会显示此样式。示例代码:这里是标题我是
- 【王老师每日家庭教育分享】——为什么好父母要懂点心理学?
王继轩24
孩子的“问题”行为背后都隐藏着某种心理需求,优秀的父母会根据孩子的心理特点因势利导。中国近现代教育家陈鹤琴说:“家庭教育必须根据儿童的心理始能行之得当。”父母爱孩子,更应该懂孩子正所谓“爱不需要理由,但是爱需要技巧”。在教育孩子的时候,父母必须首先了解孩子的心理和特点。
- 博客时代的文字之美
芥末笔记
看到一些好的句子,突然有感而发,或者有想展开写一下的主题,会记录在备忘录里。今天翻看的时候,看到两句话,好像出自去年南方人物周刊开年刊的卷首语。“春的气息已经破土,玉兰在枝头含苞,枯草在墙角转绿,而春联在家门口等你。祝福你做自己人生的改变者,祝福你拥有新的春天。”今天已经2月26号了,开启日更的第十四天。这应该是自己今年最大的改变了。日更的好处是显而易见的,从一个标题的确定到八九百字的成文,最快基
- 第三章 数据链路层
becoolguy
一、数据链路层的功能数据链路层在物理层提供服务的基础上向网络层提供服务,主要作用是加强物理层传输层原始比特流的功能,将物理层提供的可能出错的物理连接改造成为逻辑上无差错的数据链路,使之对网络层表现为一条无差错的链路。二、介质访问控制CSMA/CD:先听后发、边听边发、冲突停发、随机重发CSMA/CA:在发送数据时先广播告知其他结点,让其他结点在某段时间内不要发送数据,以免出现碰撞三、局域网PPP协
- 日更第一百八十八天
清幽励志文苑
图片发自App日子不知觉的流逝着,生活在闹心与和解中过着,每日闲暇之余总是会抽出点时间来上看看。涂鸦几笔,记录光阴,留下足迹,最初也许是为日更而更,但后来就已成为习惯,没有目的,只是想写,想发表下字符。再这里几乎不怎么和文友们互动,只是随心而看,每一篇点赞过得文章都是用心阅读厚的赞赏。也很是感谢简友们的关注品读赏阅,你们的每一次赞赏都是对清幽的鼓励,感谢一路有你们同行,晚安,好梦,简友们!
- Android12.0 需求开发篇之OTA AB升级篇章一
洋仔518
android
1.需求描述RK3568平台对应项目上要求使能AB分区,这样同样OTA也需要能够支持AB分区升级,RK平台默认是不给打开AB分区的,AB分区是单分区的进一步优化模式其优点如下:
- 2022-08-16
龟背竹
2022年8月16日,北京,天气多云转晴。像极了我的人生嘛,以后要晴朗起来了,心阔朗,哪里都有阳光。壬寅年戊申月辛丑日,农历七月十九,星期二。两胳膊酸痛得一晚上没睡踏实,今天睁眼就将近九点,旧的iPad应该能卖出去,折旧很厉害,但没办法,这就是现实,当时再完美无暇高价值的东西,有了新的替代之后,只能接受贬值。我可能也是那个不合时宜的物件了,索性我是人,可以与时俱进,不断向前,自己要看得起自己,而不
- 《中国教育史》第九章近代教育体制的变革
泺伊悦尔
2020年2月16日正月二十三第一节民国初年的教育改革一、制定教育方针注重道德教育,以实力教育、军国民教育辅之,更以美感教育,完成其道德。二、颁布壬子癸丑学制1912-1913年。(1)学制体系:三段四级。初等教育分为初等小学(4年,义务教育)和高等小学共七年,法定入学年龄6年。中等阶段4年,专门设女子中学。高等教育设大学,分预科、本科、大学院三个层次。学制总年限为17-18年。小学之下,蒙养园和
- 【老夏献方】药草可护肤之止痒去屑!
拈花老夏
图片发自App【老夏献方】如果,你用老夏帮你细火慢熬的植物洗发乳《夏》还是无法止痒和去屑,在你决定放弃植物,打算重返抗生素药物制剂的时候,我还是建议你再试试下面这个简单的方子,它已在最后关头化解了很多苦恼!中药铺都能配齐,简单,便宜,好用!图片发自App【老夏提醒】针对血热型头痒头皮屑、顽固性真菌感染型、头发根部顽固性湿疹,大量案例使用有效。请注意适当忌口!!!如果有效,我希望你不用感谢老夏,但你
- 第一章:再相遇
c6910821d417
今天是新生入学的第一天,许嘉瑜暗暗地下定决心这学期一定要好好学习,立志要成为一个博学多才的学霸。她仔细地在分班表里寻找着她自己的名字,指尖在分班表上轻轻地移动。突然,一只大手触碰到了她的手指,她抬头一看,原来是一个老熟人,不过和记忆中的小男孩却完全不同了。“顾子彦,怎么是你?”这不是小时候那个总爱嘤嘤嘤的邻家小男孩吗?不是已经搬走好多年了吗?难道又搬回来了?许嘉瑜心想。“自从你从隔壁搬走了以后我就
- 手把手一步一步教你使用Java开发一个大型街机动作闯关类游戏09之sprite动画
__豆约翰__
项目源码项目源码sprite动画上一节,我们可以控制sprite移动了,但sprite的移动就是平移,比较呆板;这一节我们给sprite添加动画效果。Animation类继承Transform,这样就具备了平移和缩放的能力。主要思想是:1.包含一个图片的列表(动画的本质就是多张图片的连续播放)2.内部有个定时器,不断更换图片。@OverridepublicvoidactionPerformed(A
- 有话好好说
快乐老家
父母与子女沟通时,虽然很愿意了解孩子的内心感受,接受孩子的情绪,常无意中流露出某些传统的角色,造成亲子沟通障碍,扼杀了孩子表达的勇气。一、七种传统角色影响沟通顺畅1.指挥官的角色“我都告诉过你,叫你不要和他来往”“我都和你说过很多次了,你总是不长记性”“如果你再...,我就...”命令的语气,心存好意,造成心灵的威胁,扼杀表达勇气。2.道德家的角色“你应该为你的不对行为向老师慎重的道歉”“你不应该
- LangGraph人机交互
wwx0622
人机交互AIGCAI编程gpt
Agent开发框架之Langgraph第一章Langgraph简介与入门第二章LangGraph条件边与工具调用第三章LangGraph人机交互:中断与调试文章目录Agent开发框架之Langgraph前言一、LangGraph人机交互代码总结前言在一些程序中,可能需要用户的状态才能使程序继续执行。例如,假如我们部署了一个web页面,在前端的输入框中得到了用户输入,接着后端接收该信息并注入到任务中
- 面对抑郁症或者躁郁的孩子,父母不要慌,教你几招轻松解决!
彭华勇
最近,一则双人落水的新闻又把抑郁症推上了风口浪尖。其实,随着社会越来越发展,人们面对的新的东西越来越多,挑战也就越来越多,压力也就越来越大,对于大多数患有抑郁症和躁郁症的孩子的父母来说,他们不知道如何帮助他们度过难关。因此,大多数时候,父母受不了这种精神上的折磨,就会把孩子扔进医院,一走了之。之前,彭老师接到过一个案例,孩子是重度抑郁,由于父母常常不在家在外面忙生意,孩子在很早患上抑郁症的时候,父
- 2022-06-18
lattde
持己之爱筑梦远航2022年6月18日宣传组何飞飞今天是暑调活动的第二天,真的是时间紧任务重,经过第一天的工作,我深深地意识到暑期调研工作的艰辛与不易。昨天我们两个组的工作就是做好每个组的大纲工作,今天的任务就是将昨天整理好的大纲进行进一步地完善,所以今天的工作更为繁琐细致。但是,我们的每一位组员都很忙碌,都各自尽善尽美地负责自己的板块,争取做到最好。每一项工作都经历了一次又一次地修改,今天组员之间
- 《论语》打卡第二十九天
柯松珠
【原文】4.23:子曰:“以约失之者鲜矣。”【译文】4.23孔子说:“严于律己,就会少犯错误。”【一点感悟】孔子追求中庸之道,过分的奢侈,过分的节约,都不是他所倡导。他的目标达到合适,舒服的状态,不放纵,也不过分约束,一切符合中庸。这个境界真的很难做到。只要求自己早起早睡,每天看点书。保持每天学习状态。【原文】4.24:子曰:“君子欲讷于言而敏于行。”【译文】4.24孔子说:“君子应当言谈简洁,行
- 风骚榜(2023-04-01更新五律榜)
张成昱
二十一世纪旧体诗词风骚榜上榜絮语:不赴云之末,当知人后言。五律·寻风作者:柒柒六落日村烟直,春山辙迹轻。枝闲云不动,池静影分明。身共单车疾,凉从短袖生。知风因我起,而后到青苹。五律榜第一与诸同学游香山诗画园瞻龙榆生手札/北林子(拏云诗友)龙七风骚客,百年高旷怀。篁烟横彩峪,蝶影下青崖。思渐车尘远,感尤山气佳。忽然黄叶落,一片择空阶。第二镜子(新韵)/讷言不敏(海棠诗友)霜身薄若纸,深可蕴乾坤。似水
- 攻城天下内部号怎么获取 哪里能弄到手游内部号?
会飞滴鱼儿
(如果你玩手游,请你认真看完这篇文章。因为下面的内容可能会颠覆你的认知。)我本人从2015年从事手游研发和运营5年时间,曾经是某一游戏大厂的运营主管,这五年时间里我接手过17款热门游戏的研发与运营工作。但在2020年,我毅然决然的退出游戏行业。所有才敢爆出手游产业链的内幕。大家玩游戏肯定都遇到过托,其实市面上百分之85的手游里面都有手游托,甚至达到一款游戏一个服都有一个托。我们业内以内部号来称呼。
- 搞基者说
老李_4a56
油印室一体机品牌是基士得耶,大家尊称操作人为搞基者。不过这台机器人们更喜欢谐音称即死的爷。此爷长期混迹仕林,拜读各类官样文章,居然习得一身恶习,欺丑媚美尤甚。向有佳人作宰油印,爷逆来顺受,任劳任怨。今者豁齿老人当途,不意欺其齿落头秃,竟老气横秋,喜怒无常,吊儿郎当。豁者敬其服务多年,功劳苦劳可圈可点,乃灌油润之,抹布净之,延医疗之,所作殷勤不一而足。然精诚已至,金石不开,此爷做事全凭意气,或漫漶难
- 再赠文友回眸一笑笑
亮靓_27d5
掌勺当大厨,妙笔写诗文。回眸一笑笑,惊动简村人。图片发自App注1:此诗是我品读文友回眸一笑散文《酸奶蛋糕》一文时,写下的一首点评诗。注2:文友回眸一笑笑,不仅现代情诗写得特棒,厨艺也不错,《笑笑厨房》经常秀厨艺,而且歌声甜美,歌声也为简村文友所喜爱。我曾赠《回眸一笑笑》嵌名诗两首以表示对她的敬意。注3:附录我赠《回眸一笑笑》两首嵌名诗,以便与文友一起分享。其一回瞻简村美才女,波光盈盈撼歌房。一曲
- 2022-05-21 - 草稿
喜悦肖娟
游戏惹得祸场景:先生回家发现儿子还在玩游戏,就提出让孩子交出手机,孩子很不乐意,当时也很有情绪。我坐到他身边,看着他说“妈妈感受到你此刻很生气,是吗?”孩子委屈不语,看到孩子眼眶红了。“爸爸让你把手机里的游戏删掉,你不开心是吗?”感受到孩子的情绪有了一些放松,“你愿意跟妈妈说说你内心的想法吗?”孩子依然不语,换成以前我面对孩子的沉默不语,我可能就没耐性再继续下去了,我会丢下一句“你自己好好想想吧”
- 《顿悟智慧禅文化》之八
世界和平_众生安康
圣人同心,心灯相传传说中有一天,佛陀在灵山会上,亲手拈花,百万人天者都各自茫然,唯迦叶尊者破颜微笑。世尊乃曰:“吾有正法眼藏,涅槃妙心,实相无相,微妙法门,不立文字,教外别传,付嘱摩诃迦叶。”佛陀于是将法门付嘱大迦叶,“禅”就这样开始传承下来。佛陀曾经谈经三百余会,说法四十九年,三藏十二部经典,浩瀚无涯,无数的文字般若,薪火相传——而禅,微妙法门,教外别传;不立文字者,亦不离文字。往下之后,无论宗
- 配镜风波
㴠佑宝妈
这几天虽然听了院长的课,但是我还是无力到了极点!原因还是老公闹的我心里不舒服。周五晚上导师班上课前,老公不吭声用我的钉钉登录在导师班群里诋毁心时代和院长,我被移出群,后来给婷婷说了情况又把我拉进群里,谁知道第二天早上上课才发现又被踢出钉钉群了,给婷婷联系才知道他半夜又登我的钉钉群又发诋毁信息,对于他的做法我的心真是凉透了,特别是他一而再的这样做,我有强烈的耻辱感!于是从周五晚上到现在非必要没再给他
- 再给孙翔一年,他能够得着巅峰时期的韩文清吗?
颚之巨人马赛尔
在动漫中,孙翔虽然出场次数不多,但存在感一直很强,让别人不得不注意到他。文/颚之巨人马赛尔如果孙翔没有足够的实力,他这般狂傲,早就被人黑得爬不起来了。应该说,孙翔确实有自傲的资本,不说别的,光是带着越云这支弱旅一路逆风翻盘,就不是一般人能做得到的。他足够年轻,上升劲头非常猛,外形也很不错,至少是能让各大战队手握主动权的高层们眼前一亮的人物。如果他不是被恰好被陶轩挖走、如果他没有阴错阳差地踏入嘉王朝
- 《潜夫论》卷16述赦诗解2圣制刑法威奸惩恶赦非常用因时制宜
琴诗书画
《潜夫论》卷16述赦诗解2圣制刑法威奸惩恶赦非常用因时制宜题文诗:谨慎之民,用天之道,分地之利,择莫犯土,谨身节用,积累纤微,以致小过,质良善民,惟国之基.轻薄恶子,不道凶民,思彼奸邪,起作盗贼,竟以财色,杀人父母,戮人之子,灭人之门,取人之贿,及谄谀官,贪残不轨,凶恶弊吏,掠杀不辜,侵冤小民,小民皆望,圣帝当为,诛恶治冤,以解蓄怨.一门赦之,反令恶人,高会夸诧,老盗服臧,而过门也,孝子见雠,而不
- 网游之纵横(一)
猫小叮
终于等来了23日,韩雨立刻开始了游戏“您好~”清脆的声音响起请问您的游戏名称一个NPC问“风雪之星”韩雨想了一会儿,说到“好的,风雪之星,请选择外貌”风雪之星在一堆脸中找了十多分钟,选了一个比较大众的脸好的,即将开始游戏……一阵强光闪过,风雪(简称)出现在一座山上他打开地图,顿时傻眼了,地图上仅有的(除了出生地,其他需要玩家探索)两个字“益州”映入眼帘顿时,风雪手舞足蹈,益州,也就是四川,可是出名
- “趟着走”还是换种方式
水墨烟岚
如果把家长教育孩子比作走路一种方式,那么“趟着走”也是其中的一种。谁都不知道要翻越一座山峰会遇到什么人、碰到什么事、经过什么样的路,承受什么样的跌倒之痛,甚至会有什么样的狂风暴雨、什么样的断桥低谷。但是人生总要前行,无论是否愿意,不管准备是否充足。“趟着走”,一边低头拉车,一边抬头看路。低头拉车会很累,但再累也得脚踏实地;抬头看路就能看到希望,探视到目标,但得把眼下的事做好。所有的物质享受都会成为
- 从“父母与子女无恩”一论看亲子关系
给我一杯奶茶我还能学
人与人之间的交集关系,实在复杂。由于自然界生物基因的传承,人类自发地组建并完善了“家庭”这一概念,也正是因为如此,人们才有了内外亲疏之的区分。“内”、“亲”,大多形容的就是血缘关系,更明确点来说,指的是亲子关系。即我们与父母的关系,我们与子女的关系。《中华人民共和国婚姻法》中的第二十一条的规定就写道:父母对子女有抚养教育的义务;子女对父母有赡养扶助的义务。法律描述的亲子关系,意味着人们必须承担起教
- 插入表主键冲突做更新
a-john
有以下场景:
用户下了一个订单,订单内的内容较多,且来自多表,首次下单的时候,内容可能会不全(部分内容不是必须,出现有些表根本就没有没有该订单的值)。在以后更改订单时,有些内容会更改,有些内容会新增。
问题:
如果在sql语句中执行update操作,在没有数据的表中会出错。如果在逻辑代码中先做查询,查询结果有做更新,没有做插入,这样会将代码复杂化。
解决:
mysql中提供了一个sql语
- Android xml资源文件中@、@android:type、@*、?、@+含义和区别
Cb123456
@+@?@*
一.@代表引用资源
1.引用自定义资源。格式:@[package:]type/name
android:text="@string/hello"
2.引用系统资源。格式:@android:type/name
android:textColor="@android:color/opaque_red"
- 数据结构的基本介绍
天子之骄
数据结构散列表树、图线性结构价格标签
数据结构的基本介绍
数据结构就是数据的组织形式,用一种提前设计好的框架去存取数据,以便更方便,高效的对数据进行增删查改。正确选择合适的数据结构,对软件程序的高效执行的影响作用不亚于算法的设计。此外,在计算机系统中数据结构的作用也是非同小可。例如常常在编程语言中听到的栈,堆等,就是经典的数据结构。
经典的数据结构大致如下:
一:线性数据结构
(1):列表
a
- 通过二维码开放平台的API快速生成二维码
一炮送你回车库
api
现在很多网站都有通过扫二维码用手机连接的功能,联图网(http://www.liantu.com/pingtai/)的二维码开放平台开放了一个生成二维码图片的Api,挺方便使用的。闲着无聊,写了个前台快速生成二维码的方法。
html代码如下:(二维码将生成在这div下)
? 1
&nbs
- ImageIO读取一张图片改变大小
3213213333332132
javaIOimageBufferedImage
package com.demo;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
/**
* @Description 读取一张图片改变大小
* @author FuJianyon
- myeclipse集成svn(一针见血)
7454103
eclipseSVNMyEclipse
&n
- 装箱与拆箱----autoboxing和unboxing
darkranger
J2SE
4.2 自动装箱和拆箱
基本数据(Primitive)类型的自动装箱(autoboxing)、拆箱(unboxing)是自J2SE 5.0开始提供的功能。虽然为您打包基本数据类型提供了方便,但提供方便的同时表示隐藏了细节,建议在能够区分基本数据类型与对象的差别时再使用。
4.2.1 autoboxing和unboxing
在Java中,所有要处理的东西几乎都是对象(Object)
- ajax传统的方式制作ajax
aijuans
Ajax
//这是前台的代码
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <% String path = request.getContextPath(); String basePath = request.getScheme()+
- 只用jre的eclipse是怎么编译java源文件的?
avords
javaeclipsejdktomcat
eclipse只需要jre就可以运行开发java程序了,也能自动 编译java源代码,但是jre不是java的运行环境么,难道jre中也带有编译工具? 还是eclipse自己实现的?谁能给解释一下呢问题补充:假设系统中没有安装jdk or jre,只在eclipse的目录中有一个jre,那么eclipse会采用该jre,问题是eclipse照样可以编译java源文件,为什么呢?
&nb
- 前端模块化
bee1314
模块化
背景: 前端JavaScript模块化,其实已经不是什么新鲜事了。但是很多的项目还没有真正的使用起来,还处于刀耕火种的野蛮生长阶段。 JavaScript一直缺乏有效的包管理机制,造成了大量的全局变量,大量的方法冲突。我们多么渴望有天能像Java(import),Python (import),Ruby(require)那样写代码。在没有包管理机制的年代,我们是怎么避免所
- 处理百万级以上的数据处理
bijian1013
oraclesql数据库大数据查询
一.处理百万级以上的数据提高查询速度的方法: 1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 o
- mac 卸载 java 1.7 或更高版本
征客丶
javaOS
卸载 java 1.7 或更高
sudo rm -rf /Library/Internet\ Plug-Ins/JavaAppletPlugin.plugin
成功执行此命令后,还可以执行 java 与 javac 命令
sudo rm -rf /Library/PreferencePanes/JavaControlPanel.prefPane
成功执行此命令后,还可以执行 java
- 【Spark六十一】Spark Streaming结合Flume、Kafka进行日志分析
bit1129
Stream
第一步,Flume和Kakfa对接,Flume抓取日志,写到Kafka中
第二部,Spark Streaming读取Kafka中的数据,进行实时分析
本文首先使用Kakfa自带的消息处理(脚本)来获取消息,走通Flume和Kafka的对接 1. Flume配置
1. 下载Flume和Kafka集成的插件,下载地址:https://github.com/beyondj2ee/f
- Erlang vs TNSDL
bookjovi
erlang
TNSDL是Nokia内部用于开发电信交换软件的私有语言,是在SDL语言的基础上加以修改而成,TNSDL需翻译成C语言得以编译执行,TNSDL语言中实现了异步并行的特点,当然要完整实现异步并行还需要运行时动态库的支持,异步并行类似于Erlang的process(轻量级进程),TNSDL中则称之为hand,Erlang是基于vm(beam)开发,
- 非常希望有一个预防疲劳的java软件, 预防过劳死和眼睛疲劳,大家一起努力搞一个
ljy325
企业应用
非常希望有一个预防疲劳的java软件,我看新闻和网站,国防科技大学的科学家累死了,太疲劳,老是加班,不休息,经常吃药,吃药根本就没用,根本原因是疲劳过度。我以前做java,那会公司垃圾,老想赶快学习到东西跳槽离开,搞得超负荷,不明理。深圳做软件开发经常累死人,总有不明理的人,有个软件提醒限制很好,可以挽救很多人的生命。
相关新闻:
(1)IT行业成五大疾病重灾区:过劳死平均37.9岁
- 读《研磨设计模式》-代码笔记-原型模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* Effective Java 建议使用copy constructor or copy factory来代替clone()方法:
* 1.public Product copy(Product p){}
* 2.publi
- 配置管理---svn工具之权限配置
chenyu19891124
SVN
今天花了大半天的功夫,终于弄懂svn权限配置。下面是今天收获的战绩。
安装完svn后就是在svn中建立版本库,比如我本地的是版本库路径是C:\Repositories\pepos。pepos是我的版本库。在pepos的目录结构
pepos
component
webapps
在conf里面的auth里赋予的权限配置为
[groups]
- 浅谈程序员的数学修养
comsci
设计模式编程算法面试招聘
浅谈程序员的数学修养
- 批量执行 bulk collect与forall用法
daizj
oraclesqlbulk collectforall
BULK COLLECT 子句会批量检索结果,即一次性将结果集绑定到一个集合变量中,并从SQL引擎发送到PL/SQL引擎。通常可以在SELECT INTO、
FETCH INTO以及RETURNING INTO子句中使用BULK COLLECT。本文将逐一描述BULK COLLECT在这几种情形下的用法。
有关FORALL语句的用法请参考:批量SQL之 F
- Linux下使用rsync最快速删除海量文件的方法
dongwei_6688
OS
1、先安装rsync:yum install rsync
2、建立一个空的文件夹:mkdir /tmp/test
3、用rsync删除目标目录:rsync --delete-before -a -H -v --progress --stats /tmp/test/ log/这样我们要删除的log目录就会被清空了,删除的速度会非常快。rsync实际上用的是替换原理,处理数十万个文件也是秒删。
- Yii CModel中rules验证规格
dcj3sjt126com
rulesyiivalidate
Yii cValidator主要用法分析:
yii验证rulesit 分类: Yii yii的rules验证 cValidator主要属性 attributes ,builtInValidators,enableClientValidation,message,on,safe,skipOnError
- 基于vagrant的redis主从实验
dcj3sjt126com
vagrant
平台: Mac
工具: Vagrant
系统: Centos6.5
实验目的: Redis主从
实现思路
制作一个基于sentos6.5, 已经安装好reids的box, 添加一个脚本配置从机, 然后作为后面主机从机的基础box
制作sentos6.5+redis的box
mkdir vagrant_redis
cd vagrant_
- Memcached(二)、Centos安装Memcached服务器
frank1234
centosmemcached
一、安装gcc
rpm和yum安装memcached服务器连接没有找到,所以我使用的是make的方式安装,由于make依赖于gcc,所以要先安装gcc
开始安装,命令如下,[color=red][b]顺序一定不能出错[/b][/color]:
建议可以先切换到root用户,不然可能会遇到权限问题:su root 输入密码......
rpm -ivh kernel-head
- Remove Duplicates from Sorted List
hcx2013
remove
Given a sorted linked list, delete all duplicates such that each element appear only once.
For example,Given 1->1->2, return 1->2.Given 1->1->2->3->3, return&
- Spring4新特性——JSR310日期时间API的支持
jinnianshilongnian
spring4
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- 浅谈enum与单例设计模式
247687009
java单例
在JDK1.5之前的单例实现方式有两种(懒汉式和饿汉式并无设计上的区别故看做一种),两者同是私有构
造器,导出静态成员变量,以便调用者访问。
第一种
package singleton;
public class Singleton {
//导出全局成员
public final static Singleton INSTANCE = new S
- 使用switch条件语句需要注意的几点
openwrt
cbreakswitch
1. 当满足条件的case中没有break,程序将依次执行其后的每种条件(包括default)直到遇到break跳出
int main()
{
int n = 1;
switch(n) {
case 1:
printf("--1--\n");
default:
printf("defa
- 配置Spring Mybatis JUnit测试环境的应用上下文
schnell18
springmybatisJUnit
Spring-test模块中的应用上下文和web及spring boot的有很大差异。主要试下来差异有:
单元测试的app context不支持从外部properties文件注入属性
@Value注解不能解析带通配符的路径字符串
解决第一个问题可以配置一个PropertyPlaceholderConfigurer的bean。
第二个问题的具体实例是:
- Java 定时任务总结一
tuoni
javaspringtimerquartztimertask
Java定时任务总结 一.从技术上分类大概分为以下三种方式: 1.Java自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务; 说明: java.util.Timer定时器,实际上是个线程,定时执行TimerTask类 &
- 一种防止用户生成内容站点出现商业广告以及非法有害等垃圾信息的方法
yangshangchuan
rank相似度计算文本相似度词袋模型余弦相似度
本文描述了一种在ITEYE博客频道上面出现的新型的商业广告形式及其应对方法,对于其他的用户生成内容站点类型也具有同样的适用性。
最近在ITEYE博客频道上面出现了一种新型的商业广告形式,方法如下:
1、注册多个账号(一般10个以上)。
2、从多个账号中选择一个账号,发表1-2篇博文
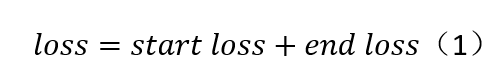
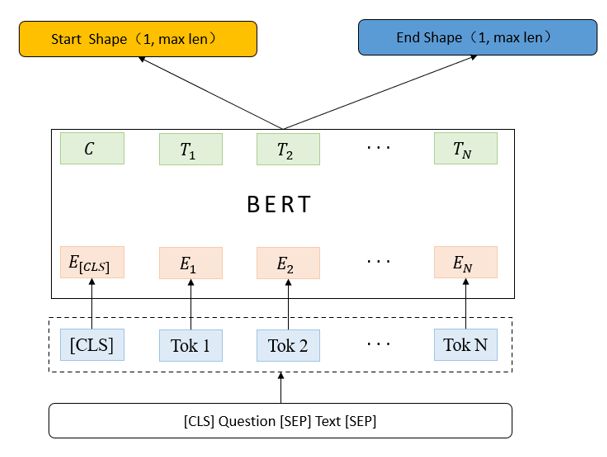 图1 模型示意图
图1 模型示意图
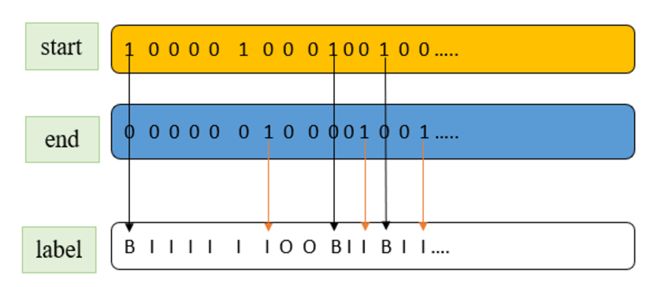 图2 预测结果配对
图2 预测结果配对
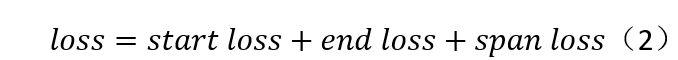
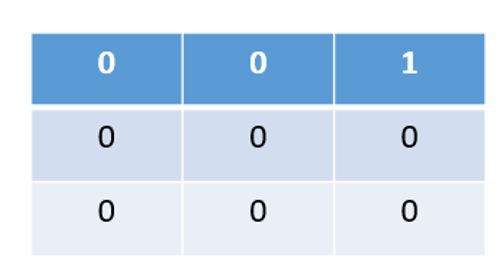 图3 span矩阵
图3 span矩阵
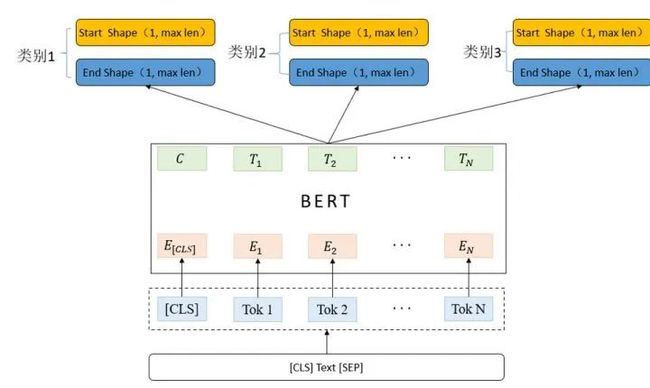 图4 指针网络
图4 指针网络