自从使用上了 hadoop 集群后,服务器 要经常扩容 ,hdfs 也要 经常rebalance
如果只有一台的话,没有问题,按照命令操作就可以,但是 单单格式化就要等好久,但是是一个集群 四五台就可以需要整很久,两个小时下不来,而且还容易出错,说不定不小心,你就可能把 完好的一块磁盘给格式化成zero
如果一个集群已经有上百台节点了,为了充分解放劳动力,如果没有一个可以使之自动化执行磁盘格式化流程的脚本 我感觉三天才能完整干完,而且你还要不断的验证,防止万一没有格式化好或者 挂载点异常,导致新的磁盘还是无法使用,为此 我在同事的建议下 写了一个脚本,发现刚开始由于没有经验,即使是使用脚本,还是出了一些问题,但是当你不断的调整,在一台机器上实验完全成功后,由于每个节点的配置都是一样的,所以一个这样的自动化执行脚本 可以在整个拓扑网络同层次的各个节点全部适用。
首先带大家熟悉一下关于磁盘 格式化 相关命令 及解释
1.查看
fdisk -l
2.磁盘分区
fdisk /dev/vdb
(根据提示,依次输入“n”,“p”“1”,两次回车,“wq”,分区就开始了,很快就会完成。)
3.格式化分区
mkfs.ext3 /dev/vdb1
4.添加分区信息
echo '/dev/vdb1 /data1 ext3 defaults 0 0' >> /etc/fstab
(其中 /mnt 可以改成自定义的目录,我们一般用 /data1)
5.挂载分区
mount -a
一下是脚本的具体内容,
vi fsnewdisk.sh
`
‘#!/bin/sh
disks=("/dev/vdg" "/dev/vdh")
counts=6
for disk in ${disks[*]}
do
echo "begin fenqu disk :"+ $disk
echo "format disk complete mkdir ing"+${counts}
sudo -i mkdir /data${counts}
echo "n
p
1
wq"| fdisk $disk &
echo "fenqu finish,format disk ing"
mkfs.ext3 ${disk}1
echo "register in fstab"
echo "${disk}1 /data${counts} ext3 defaults 0 0">> /etc/fstab
echo "gua zai disk"
echo "all complete"
counts=$(expr $counts + 1)
echo "counts"+$counts
done
mount -a
`
编辑好后,就 直接 sh fsnewdisk.sh & ,一定要后台进程,防止 terminal关闭,导致脚本执行中断
,另外 要关注 你的盘符 和挂载的文件目录点,因为之前我已经挂载了五个磁盘了,也是同样的操作,这次从第六个盘开始,所以有一些是需要 自己做适当修改
通过 fdisk -l 查看 磁盘,
注意 磁盘扩容的操作 只能在root用户下进行
磁盘只有格式化 挂载好 才会出现 Device Boot Start End Blocks Id System
而没有格式化的 只是绑定了的磁盘 是没有这些内容的,比如下张图
/dev/vdg 和 /dev/vdh两个磁盘都还没有格式化 ,只是购买了,绑定在服务器节点上
假如你在执行磁盘格式化出现了意外也不要担心,重新再来一次正确的即可
比如 这些错误
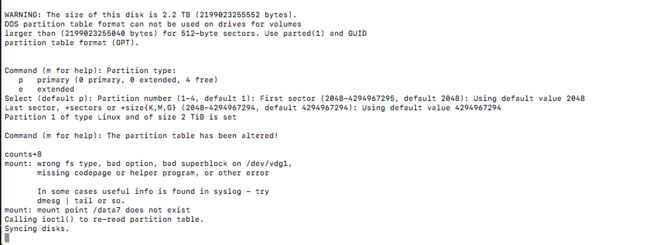
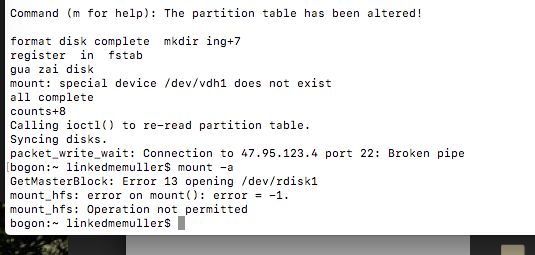
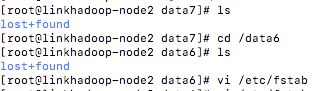
验证 这个盘是否挂载好的另一种方式就是cd 到磁盘的挂载目录下有没有 lost+found 这个文件
当这些都做好了以后,修改 hadoop 集群每个节点的 配置文件 hdfs-site.xml 中的dfs.datanode.data.dir 属性,把你新添加的磁盘加入到其value中
还有就是 yarn-site.xml 中 NodeManager的 yarn.nodemanager.local-dirs 属性,把新加入的盘追加到其value中
划重点来了,大家加入的磁盘的挂载目录 比如说是 /data6 和 /data7 我们在 格式化 和挂载的时候都是root 用户下操作的,两个 目录的权限都是 root ,如果 你不修改,直接在 hadoop管理员用户【一般不是root 用户】重启hadoop 集群的话,我会告诉你 所有DataNode节点 的 DataNode 后台守护进程将无法 启动,因为 根本没有权限无法向这两个目录写入文件,
报错 :# Namenode is in startup mode
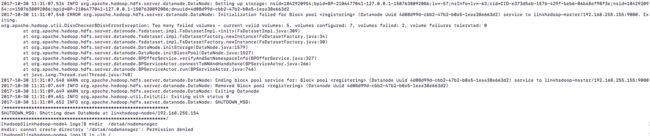


当你修改了所有DataNode节点的这两个新的挂载目录的权限后


然后重启 hadoop 集群,这样磁盘就可以被hadoop 的DataNode 节点识别 作为hdfs 存储单元来使用了,

但是我们还要考虑一个 问题 就是 hadoop的磁盘默认写入策略 是 Robin, 这样的话,还是原来的旧盘 最先写满,新盘写的少,假如你这样扩容就不管了,万一 旧盘已经写入了 磁盘的99%,再加多少新盘都是杯水车薪,我们要考虑 的是 减轻旧盘的磁盘写入压力,这个才是扩容的关键,虽然我修改 成了 优先写入新的磁盘的策略,但是这个还是不够的,需要我们手动rebalance, 强制执行把 旧盘的数据块 转移到新盘,来回 均匀一下。这样最后 新盘旧盘 大家的写入量都一样,再往里面写日志流就不必担心到底写到哪个盘里了,以后再有新盘的时候也是要这样rebalance的
hadoop 本身自带一个 start-balancer.sh的一个脚本,我们可以使用欧冠它,另外 dfadmin中也有一个 balance的参数可以设定的
这个明天尝试,完事我告诉大家。