Hinton 第七课 。这里先说下RNN有recurrent neural network 和 recursive neural network两种,是不一样的,前者指的是一种人工神经网络,后者指的是一种深度神经网络这里指的是前者,这部分翻译的不好,因为之前没怎么接触过RNN,不过就当理解意境吧,所以附上所有的ppt,看得懂的就看PPt,下面的是附带说明,有些语句没有那么通顺,所以就当意境了。
而且百科上居然有这么多分类:
-
完全递归网络(Fully recurrent network)
-
Hopfield网络(Hopfield network)
-
Elman networks and Jordan networks
-
回声状态网络(Echo state network)
-
长短记忆网络(Long short term memery network)
-
双向网络(Bi-directional RNN)
-
持续型网络(Continuous-time RNN)
-
分层RNN(Hierarchical RNN)
-
复发性多层感知器(Recurrent multilayer perceptron)
-
二阶递归神经网络(Second Order Recurrent Neural Network)
-
波拉克的连续的级联网络(Pollack’s sequential cascaded networks)
这一课中有个附带的论文《A novel approach to on-line handwriting recognition based on bidirectional long short-term memory networks》,是07年的,还没怎么看。
一、序列建模:简要概述
这部分简要介绍一些在序列上建模的模型,首先介绍最简单那的模型,这也是回归的模型,就是试图从之前的项中得到的序列来预测下一个项;然后介绍一些拥有隐藏单元且精心设计的变量;然后介绍一些不但有着隐藏状态而且有着隐藏动态的有趣的模型,这些都包括线性动态系统和隐马尔可夫模型。这些模型中大部分都是很复杂的,所以不期望一次就懂,提到这些模型的意图是为了展示如何将我们的模型也按照那样的模型进行递归。

当我们想要使用ML来对序列进行建模时,通常希望能够从一个序列转到另一个序列,例如:在语音识别中,我们希望从英语单词转到法语单词或者从声压序列转移到单词序列。
有时候我们没有独立的目标序列,这时候我们可以通过尝试预测输入序列中的下一项来得到一个teaching信号(应该是标签吧),所以这个目标输出序列可以是简单的输入序列中的下一步;这看上去比试图在基于图像中所有其他的像素来预测一个像素或者基于图像其他块来预测下一个块要更自然;而其中的一个原因在于对于时间序列来说,很自然的去想预测下一个时间步上是什么,然而对于图像,就不清楚从那些地方来预测什么,但是实际上在图像上也有相似的方法,而且效果还不错。
当我们预测序列中的下一项时,它就会模糊有监督和无监督之间的区别。我们使用给有监督学习设计的方法去预测下一项,但是我们不需要独立的teaching信号,所以他其实是无监督的。

这里在使用RNN去对序列建模前,先快速简单的介绍下其他序列模型。对于一个简单的序列模型而且没有记忆的来说,就是一个自回归模型:先得到许多序列中之前的项,然后尝试去预测下一个项,就像是在基于之前项的权重均值一样,之前项可能是独立的值或者是一整个向量。在线性自回归模型中,只是将之前项进行权重均值操作然后去预测下一项。
在通过加上隐藏单元就能将模型变得复杂起来。所以在前馈网络中,我们会先得到之前的输入项,将它们馈送到隐藏单元,然后预测下一项。

记忆列表模型只是在序列上用来分类的一种模型,我们能够通过其他方法来生成序列。一种非常自然的生成序列的方法是建立一个有着自己内部动态的多隐状态模型。隐状态的进化是依据它内部动态而定的,而且同时也可以生成观测值(就是预测值),从而可以得到很多不同的模型:1、信息可以在他的隐状态中存储很长一段时间,不像之前的那些无记忆模型,它没有简单的标准去判别回头看多远才能不影响后面的预测;2、如果隐状态的动态是有噪音的,而且从隐状态中生成输出也是有噪音的,那么通过观察一个这样的生成模型的输入,是没法知道他的隐状态是什么样子;3、我们所能做的最好的就是在基于所有可能的隐状态向量的空间上推测概率分布,可以知道他在空间中的某些位置,而不在空间中的其他位置,但是也没法获得准确的信息。
所以在这样的生成模型中,如果想通过观察他的生成的观测值然后去试图推测它的隐状态是什么,那通常是很难的,但是这里有两种类型的模型,他们的隐状态是比较容易计算的,也就是有着一个相对简单的计算去允许我们从可能影响数据的隐状态向量上推测概率分布,当然如果的确这么干了,而且应用到了真实数据上,那么就假定这些真实数据都是由模型生成的。所以这就是我们在建模的时候所做的事情,我们假设数据是由模型生成的,然后在基于这些数据的基础上推测这些模型的内部状态。接下来的三个ppt是基于那些已经知道这两类隐状态模型的人来介绍的:1、介绍RNN与其他标准模型的不同,如果不明白这两种标准模型,那么没关系,这里不是重点。

上图就是其中的一个标准模型:线性动态模型。它广泛的应用于工程中,这是一个有着实值隐状态的生成模型,这些隐状态是有着线性动态的,如上图中红色箭头指示的,这些动态是有着高斯噪音的所以隐状态可以进化概率(evolves probabilistically)(就是隐状态的概念可以变化的意思吧);如上图中驱动输入部分是直接影响着隐状态的,而隐状态又可以决定输出层并去预测系统的下一个输出(应用:追踪导弹),所以我们需要去推导出它的隐状态。
实际上,最早使用高斯分布的例子是从有噪音的观测值中追踪行星。高斯(人)指出,如果加入了高斯噪音,那么就能得到一个很好的结果,因为如果将高斯进行线性转换,得到的还是高斯,因为线性动态系统中所有的噪音都是高斯,所以到目前为止,基于给定观测值上的隐状态的分布(在给定输出的情况下)还是高斯,因为协方差也是全高斯,所以计算上比较复杂,但是却能高效的计算,有一个技术就叫做“卡尔曼滤波”(当年卡尔曼在nasa上和那谁说了下,结果就被应用了,可以用来捕捉飞船轨迹)。这是一个高效的递归方法去在给定一个新的观测值的情况下更新隐状态的表征。
总结:给定系统输出的观测值,我们不能确定隐状态是什么,但是我们能通过估算一个高斯分布来假设可能的隐状态是什么。当然,这里的前提条件是我们的模型是在基于观测的真实数据上正确的模型。

另一种不同的隐状态模型是使用离散分布而不是高斯分布,叫隐马尔可夫模型(HMM).。因为他基于离散数学,所以计算机科学家才更加喜欢这种。在HMM中,隐状态包含了N种选择,也就是状态的数量,而系统一般只处在其中一个状态上,状态之间的转换叫做概率,是通过一个转换矩阵(元素就是概率,这里可以参考网易 Ng的机器学习课程中HMM的章节)控制的,也就是如果处在时刻 1 ,状态1,想要知道时刻 2 下状态 3 的概率。这个输出模型通常是随机的。所以系统内的状态不能完全决定输出,在输出上有许多的变量,能表示每个状态,所以我们不能确定基于给定的输出得到的状态是什么。因为这个状态是隐藏的,所以叫隐状态。因为历史原因,一个NN中的不可见的单元都叫做隐藏单元,这里是借鉴于NN中的叫法。
因为在n个状态用n个数字来表示不同的概率分布是比较容易的,所以HMM中可以用离散状态来表示概率分布,所以即使不知道他是什么,他内部确切的状态是什么,还是能够轻松的表示概率分布。从HMM中预测下一个输出需要知道他的内部可能的隐状态,所以还是需要在概率分布上下手。基于动态规划上的一个简单的方法可以让我们在处理这些我们得到的观测值的基础上计算隐状态的概率分布。一旦我们知道了分布,那么就得到了一个优美的HMM学习算法,这也是为什么它适合语音的原因。在1970年代,它们就被用在语音识别上。

在HMM上有个根本的局限性,当我们考虑在HMM生成数据的时候到底发生什么,就能理解局限性到底在哪。在每个生成的时刻,它选择隐状态中的一个状态,所以如果有n个隐状态,那么存储在隐状态上的时间信息就差不多有log(n)位,这些就是它目前干的所有已知的事情。
现在让我们考虑一个HMM能够从前一半得到的utterance中传达多少信息到后一半。假设已经生成了前一半的utterance。现在去生成后一半(它的前一半的记忆存储在包含的n个状态中,所以他的记忆只有log(n)位信息):为了对比前一半去生成后一半,我们必须要句法匹配(所以数量和时态需要一致);同样也需要语义匹配(不可能句子的后半部分的语义完全不同于前半部分),同样语调也是需要匹配,不然前面和后面的语调看上去完全不一样就显得很怪异了;还有其他东西需要匹配:说话人的口音,速率,声响,声道扬声器的特点等。所有的这些都必须让前半部分的句子和后半部分的句子搭上。所以如果想用HMM去生成一个句子,这些隐状态需要将前半部分的信息都传达到后半部分。
现在的问题就是所有的这些方面需要100位来表示信息,所以将前半部分的这100位信息传达到后半部分,这也意味着HMM需要2 ^100个状态(一个输出表示两个状态,开,关),这太大了。

所以,这里就考虑到了递归的方法了,它们有着更高效的方法来记忆信息。它们的强大在于通过将分布式隐状态的两种属性很好的结合了起来,也就是说,一次可以激活好几个不同的单元,所以能够一次同时记忆好几个不同的事情;它们不但不止拥有一个激活单元,而且还是非线性的,一个线性动态系统有着整个隐状态向量,所以在一个时刻可以得到不止一个值,但是这些值都包含着线性的行为,所以推理起来容易,在RNN中通过将动态变得更加复杂,就能允许用更复杂的方法来更新隐状态。
在有足够的神经元和时间下,一个RNN可以计算计算机允许计算范围内的任何事情。

所以线性动态系统和HMM都是随机模型。因为这些动态和由潜在状态得到的观测值的结果都是包含着内在的噪音的。所以建模的时候就需要注意一些问题了:在基于隐状态上的后验概率分布(不论是在线性动态系统还是HMM中)是目前为止看到的数据的一个决定性函数,也就是说这些系统的推导算法还是概率分布,而这些概率分布都只是一群数字,而且这些数字决定着目前为止数据的结果。
在RNN中,这些数字构成了RNN的隐状态,而且它们也非常像这些简单随机模型的概率分布。

所以问题就是什么样的行为会出现在RNN中:它们可以是振荡的,这对于行为控制是明显的好事情,例如:当你在走路的时候想要知道你的步伐的周期性振荡;可以设置点吸引子,这可以用来检索记忆(后面会介绍到的hopfield网络是通过设置点吸引子来存储记忆),所以在是有着一些粗略 的想法去进行检索,然后通过让系统稳定到一个状态点上,并将这些状态点对应于所知道的事情,通过设置到这些状态点上,就能检索一个记忆了;如果在合适的制度(regimes这里估计是字幕错误,不过个人觉得想成规则应该还好)下设置权重的话,它们还可以是混乱的,通常来说,混乱的行为不利于信息处理,因为在信息处理中,希望行为是可靠的。但是在某些情况下这是个好想法,如果在面对一个更聪明切觉得不可能战胜的对手的时候,随机可能是一个好主意,也就是混乱(这不就是看天命?);另一个关于RNN的好处在于,很久以前,Hinton想让RNN更强大,通过使用它的隐状态的不同的子集来执行许多不同的小程序,而这些小程序的每一个都能抓取一块知识,而且所有的这些都能并行运行并以更复杂的方式交互。
可惜的是,RNN的计算能力使它很难被训练。许多年来,我们不能利用RNN的计算能力。但是它却有很多英雄式的影响,例如:Tony Robinson通过使用一个RNN来做语音识别器,他做了许多工作,在晶片机上进行并行计算,但是也只有最近,才有人通过RNN作出了比他好的结果。
二、用BP来训练RNN
这部分介绍在基于时间上用BP来训练。这也是在RNN上使用的标准训练方法。而且如果观察在RNN和一个一个时间步前进一层的前馈NN之间的对比发现这个等式还是相当简单的,这部分还会谈论提供输入和理想输出给RNN的方法。
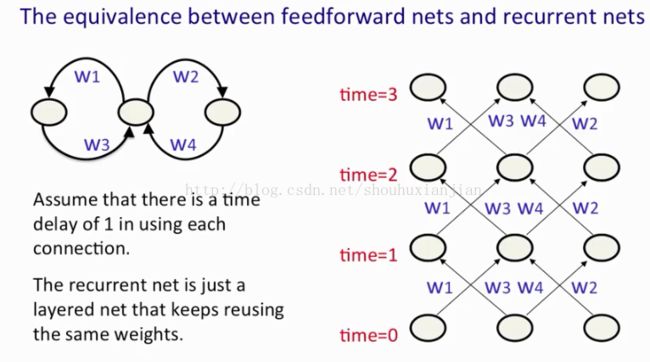
上图中显示的是一个简单的有着三个相互连接的神经元的RNN,并假设在连接上有1 的时间延时,而且这个网络是在离散时间上运行的,所以时钟是整数。理解如何训练RNN的关键在于将RNN与一个前馈网络(RNN扩展到时间上的前馈网络)等同起来。RNN以许多初始状态作为开始,在上图中底部是时刻为0 的时候,通过使用许多连接得到一个新的状态 为时刻 1,然后使用相同的权重得到另一个新的状态,以此反复,所以这很像一个权重在每一层一直是一样的前馈网络。

BP是很擅长当权重都是受限的时候来进行学习的,在CNN上有介绍。我们可以在BP中很容易的合并任何的线性约束,所以如果权重没有受限的话,我们可以向往常一样计算梯度,然后通过修改梯度使得能够迎合这个约束(意思就是如上图一样,简单的修改以前介绍的BP来在RNN上使用修改后的BP)。如果开始的时候W1 =W2,那么只需要确保W1修改的值等于W2修改的值,首先通过求W1的导数,然后求W2的导数,然后将它们相加或者求平均值,然后将这个值应用到更新W1和W2的过程中,所以如果权重开始就满足约束,那么他们还是会持续的满足约束。

通过时间的BP算法只是在将RNN视为一个层次化、有着共享权重的前馈网络上用BP训练的称呼,只是让我们记起这是在时间领域内使用BP罢了。前馈传播在每个时间步上构建一层所有单元的激活层;然后回向传播计算在每个时间步上的误差导数,这就是他为什么称之为BP through time。经过后向传播后,将每个权重上所有不同时刻的导数进行相加,然后通过同样的数值(和或者是所有导数的均值)来更新所有的权重。

上图是一个刺激性的额外问题(就是关于神经元激活状态的),如果我们没有指定所有单元的初始化状态,那么对于一些隐藏或者输出单元,我们就需要指定具体的初始化状态。我们只是将这些初始状态设置一个默认值例如0.5,但是这个值也许不是更合理的初始值。所以我们可以通过学习来得到更合理的初始值,将它们视为参数而不是激活值,并用与学习权重一样的方法来学习它们。可以通过随机猜测一个初始值作为所有非输入层单元的初始状态,在每个训练序列(每个样本)的最后,在基于所有方法上通过BP throuth time 算法回到初始状态,这就给出了基于初始状态上误差函数的梯度,然后通过这些梯度来调整初始状态,然后得到新的初始状态,得到的新的初始状态与之前的初始状态略有不同。
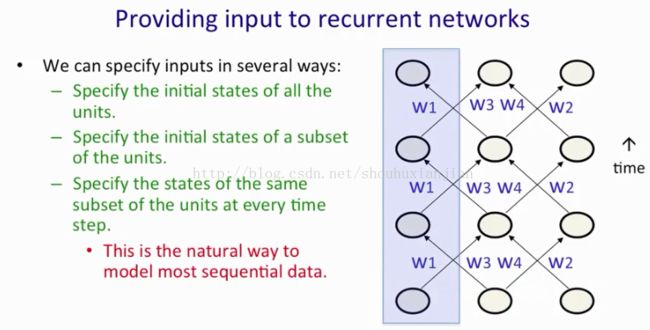
有很多种方法来给RNN提供输入:1、指定所有单元的初始状态(例子:上图中所有的单元),这也是我们考虑RNN的时候最自然的想法,就像一个受限权重的前馈网络一样;2、可以对所有单元的子集进行初始化指定(例子:上图中输入层);3、在所有单元的子集的每个时间步上指定状态(例子:上图中一列框出来的),这也可能是对于输入序列数据来说最自然的方法了。
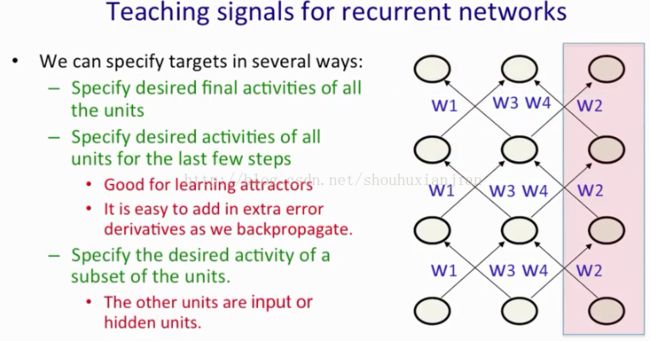
同样的,也有许多方法去对RNN的目标进行指定。当我们将他视为一个有着受限权重的前馈网络时,自然的想法就是对所有的单元指定最合适的终极状态(上图最顶层部分,也就是输出层)。如果试图训练它去学习吸引子,我们也许就会想这些合适的状态不止是对最后时间步(上图模型最顶层)上而是好几个时间(例子:上图倒数第二层)步上进行指定。这样可以使模型稳定下来,而不是前馈很多状态然后就不知道去哪了。所以通过对最后的几个状态进行指定,可以强化学习吸引子,并且BP可以将每个时间步上得到的导数加起来,所以在顶层开始的BP有着最终时间步的导数,然后往下加其他时间步的导数(如图中列框起来部分)。所以在不同的层中拥有的导数其实是有着非常小的额外的影响(就是没什么额外影响)。如果我们指定一个单元子集的激活值(这里假如是输出层),最自然的想法去训练RNN就意味着提供一个连续的输出。
三、一个训练RNN的简单例子
这部分介绍如何使用RNN去解决一个toy问题(就是玩具级别的问题)。这个问题是用来说明RNN可以干而一般的前向NN不能干的地方,也就是如何将两个二进制数进行相加,接下来可以看到RNN的隐状态是如何和有限状态自动机中的隐状态一样解决相同的问题的。

所以考虑将两个二进制数进行相加的问题,可以先训练一个前馈NN来完成这个事情,上图中右边的图显示一个有着一些输入和生成一些输出的简单网络,那么问题就来了,这时候必须要让网络知道输入和输出的最大数值,而且更重要的是,这里的处理还不能应用在不同位数上,也就是说当学会如何将上两个数值进行相加并得到结果,这时候相加的知识存储在权重中,但是当考虑这个二进制数值的一部分时,知识也是存储在不同的权重中的,所以不能得到一个自动生成的效果。(就是比如例子中的00100110,前面的加法知识和后面的加法知识不同,不是按照我们理解的那样相加,而是当成样本训练而已,不遵循数学上定义的加法)
结果就是尽管可以训练一个前馈NN,并且可以很好的将固定长度的数值进行相加,但是这种方法却不好。
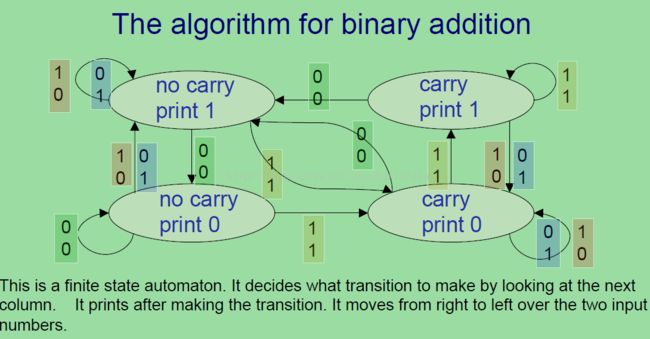
上图是关于二进制加法的解释。这里显示的状态很像HMM中的隐状态 ,只是他们不是真的隐藏罢了。系统是一个时刻一个状态,即当输入一个状态,就代表一个动作,所以不论是输出1还是0,当处在某个状态时就是拥有某种输入,也就是下一列中的两个数字,这两个数字会让系统转换到新的状态。所以如果看上图的右上方,系统处在carry状态,并且只输出1,如果系统遇见【1 1】(输入为【1,1】),那么它就维持当前状态不变,并且输出1,如果输入是【1 0】或者【0 1】那么当前系统就转移到下一个状态并且输出0(也就是右下角的状态),如果系统遇到的输入是【0 0】,那么就转移到左上角的no carry状态并且输出1。

所以一个二进制版本的RNN需要两个输入和一个输出。在每个时间步上给定两个输入数字,而且在每个时间步上还需要一次输出。强调下这里的输出是两个时间步之前的列的值的输出(上图橘红色框起来部分,这里的time箭头是不是反了?),这里需要两个时间步的延时是因为需要一个时间步去基于输入的更新隐藏单元,另一个时间步去基于隐藏单元生成输出值。

所以网络才像上图中那样。这里假设只有三个隐藏单元(这对于这个任务来说足够了),虽然有着更多的隐藏单元可以让它工作的更快,但是这里三个足矣。
这三个隐藏单元都是完全互相连接而且连接是双向的(不需要两个方向上的权值一样,不过通常来说也没有相同的权值),隐藏单元之间的连接允许一个时间步上的模式可以给下一个时间步上的模式进行投票。
输入单元有前馈连接到隐藏单元,相似的,隐藏单元有着前馈连接到输出单元,这就是他如何生成输出值的过程。

上图是解释RNN如何学习的。它从3个隐藏单元中直接学习4钟不同的激活模式,而这些模式就是对应于之前的有限状态自动机中的节点。我们肯定会将NN中的单元和有限状态自动机中的节点混淆起来:有限状态自动机中节点对应于RNN中的激活向量,这里的自动机是被约束称一个时间步只能处在一个状态的情况。相似的,在RNN中隐藏单元也是约束成一个时间步只出现一个激活向量。
所以一个RNN可以模拟一个有限状态自动机但是他的表征确实相比指数级别的强大,在有着N个隐藏单元的情况下,那么就有了2^N个可能的二进制激活向量,而且它只需要N^2个权重,所以它不需要全部用上所有的表征能力,但是如果有bootlenec(瓶颈,虽然意思是这个,但是觉得这里的意思应该参考 http://blog.csdn.net/shouhuxianjian/article/details/40795453 第四课中瓶颈意思,不是说性能受约束,而是某个地方放置一个特殊的隐藏层吧???)存在于RNN中,那么他就能做的比有限状态自动机更好。要注意到这里输入流中是每次只有有两个独立的事物(thing,翻译成项也还好吧);一个有限状态自动机需要对状态的数目进行平方去处理每次只有两个事物的情况;而一个RNN只需要两倍的隐藏单元的数目,就能表达二进制向量的数目平方级别的信息(这里意思就是RNN需要的节点比隐藏状态自动机少)。
四、为什么训练RNN这么难
这部分将会介绍梯度爆炸和消失的问题,正是因为这个问题导致训练RNN变得很困难。在很多年来,研究NN的人们认为他们没法对长时间依赖关系的网络模型进行训练。但是这里在这部分的最后会介绍4种不同的方法来解决这个问题。

为了了解为什么训练RNN如此之难,首先就得了解一个在RNN中前馈和后向传播(这里不是BP的意思,是与前馈不同的反方向而已)到底有什么不同。在前馈中,我们使用压缩型函数,例如逻辑函数去阻止激活向量的爆炸(就是输入到输出,输出是永远在【0 1】之间不让他发散出去),所以如上图所示,每个神经元使用的就是逻辑函数激活(蓝色曲线),他们没法使得结果超过1 或者小于0,以此来阻止爆炸;在后向传播上,却是完全的线性的,大多数人们认为这是很不可思议的,如果将网络的最后一层上的误差导数乘以2,那么当使用BP方法的时候就会发现所有的误差导数都被乘以了2.。所以如果观察上图中红点(蓝色曲线上的红点)我们认为这些都是前馈中的激活值所处的位置,当使用BP时,就会使用处在蓝色曲线上红点位置的梯度,所以红线意味着在红点处的tangent值(也就是斜率)。一旦完成了前馈,那么tangent的范围也就固定了,然后接着使用BP,这时候BP就像是在这些已经固定的非线性范围上使用一个线性系统,当然每次使用Bp的时候这些范围还是不同的,因为他们都是由前馈来决定的,但是在BP过程中,他们还是线性系统,所以还是被线性系统特有的问题所困扰(当迭代的时候,它们不是爆炸就是消失)。

所以当我们用BP经过很多层的时候,如果权值很小,那么梯度就会缩小,然后以指数级别变得更小,也就是说使用BP through time 的时候位于目标(输出层)之前好几层以前的梯度将会变得很小很小。相似的,如果权值很大,那么梯度就将会爆炸,这也意味着当使用BP through time ,梯度将会变得很大,并且抹平一切知识(权值代表的信息)。
在前馈网络中,除非这个网络是很深的,不然这些问题还没那么糟,因为通常来说椰子油很少的几层隐藏层而已。
但是在长序列(例如100个时间步)上训练一个RNN,如果梯度随着BP增长,那么就差不多以100为指数增长,如果梯度随着BP小时,那么同样也是以100为指数消失,所以要么爆炸,要么消失。我们也许可以通过对权值的谨慎初始化来避免这样的问题,最近越来越多的学术成果显示确实谨慎的权值初始化可以让网络的工作做的更好。
但是即使是有着很好初始化的权值,还是很难去检测当前输出与许多时间步之间的输入之间的依赖关系。RNN在处理长时依赖问题上比较棘手。

这里是一个有关一个试图去学习吸引子的系统梯度爆炸和消失的例子,假设我们试图去训练一个RNN,所以不论是以什么状态开始,都是以这两个吸引子状态中的一个结束的。所以这里是学习一个吸引子的蓝盆和一个吸引子的粉红盆,假如我们在吸引子的蓝盆中任何状态开始,我们就会以相同的点结束,这也就是说在初始化状态上微小的误差不会让结束的时候有什么不同,所以最终状态上关于初始状态上变化的导数是0,也就是梯度消失,即当我们BP通过系统的动态的时候(就是BP through time)会发现从开始的地方几乎没梯度。这当是吸引子的粉红盆也是一样的。
然而,如果我们开始的时候很靠近两个吸引子之间的位置(边界部分),那么开始的地方就会有个微小的误差,在分水岭的另一边就会使得在结束的时候有巨大的误差,这就是梯度爆炸问题。也就是无论何时试图去训练这样一种吸引子,RNN总是手梯度爆炸或者消失问题困扰。

上图就是至少有四种方法来高效的学习RNN:1、长短时记忆:通过改变NN的结构使得能够擅长记忆事物(这课下面详细讲解)。2、使用更好的优化方法去处理非常小的梯度(下一课讲解),优化中的真正的问题在于检测即使有着更小曲率的很小的梯度。Hessian-free 优化是按照NN来的,很适合干这样的事情。3、这个方法真的是一种躲避问题的方法,我们所要做的就是谨慎的初始化输入到隐藏的权值,然后谨慎的初始化隐藏到隐藏的权值,然后后向从输出到隐藏单元的权重,这里的想法就是谨慎的初始化去确保隐藏状态有着巨大的弱耦合震荡存储,所以如果输入序列,它将会混响(reverberation)很久,并且这些混响还能记忆输入序列中发生的事情,然后试图耦合这些混响到想要的输出,所以在Echo 状态网络中学到的唯一的事情就是隐藏单元到输出单元之间的连接,如果输出单元是线性的,那么就很容易训练,所以这样其实没学到递归,知识通过使用一个固定的随机递归位 罢了,知识谨慎的选择,然后只是学习隐藏到输出的连接而已。4、最后一方法是使用动量,但是是将动量初始化称可以在第三种方法中使用的值,并使得工作更好。所以聪明的方法是找出如何对这些RNN网络初始化使得它们拥有很好的动态,但是如果在有助于任务完成的方向上轻微的修改动态是有助于网络更好的工作(也就是第四种方法添加动量)。
五、长时、短时记忆
这部分将会介绍一种训练RNN的方法叫做长短时记忆。可以认为一个NN的动态状态是一个短时记忆。原理就是想要将这个短时记忆给延长到长时记忆,这是通过创建特别的模块,通过允许信息封闭在里面,然后当需要的时候将信息放出。在这过程中,门(形象的比喻)是关闭的,所以在这期间到达的信息都不会影响到记忆的状态。长时记忆有着非常成功的应用,例如手写识别,并赢得了一些比赛。

在1997年,Hochreiter和Schmidhuber发了一篇论文在神经计算期刊上,解决了如何让RNN长时间记忆事情的问题。成功的让RNN记忆长达几百个时间步。
他们通过设计一个记忆存储单元,在这个单元中使用逻辑、线性单元和乘法操作。
所以当逻辑写门打开的时候,信息就可以进入记忆存储单元。在这其中RNN剩下的部分决定了写门的状态,当剩下的部分想要存储信息时,就将写门打开(而且不论从剩下的部分的当前输入到记忆单元的是什么)存入单元。里面的信息只要保持门开着就一直不变。同样,网络剩下的部分决定了逻辑保持门的状态,如果它保持开着,那么信息就会留着。最后从记忆单元中读取信息到RNN的剩下的部分并且影响未来的状态,这时候是通过打开读门来读取的,这里是由网络剩下的部分控制一个逻辑单元实现的。
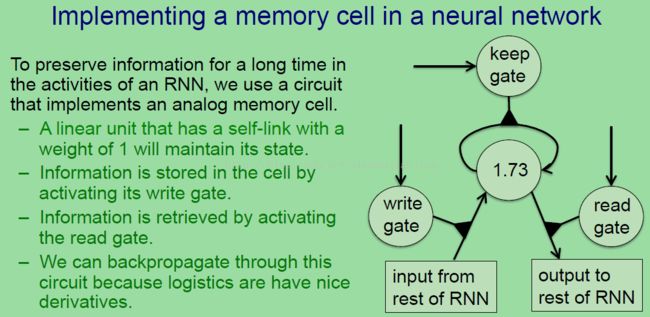
这个记忆单元实际上存储着一个模拟值,所以我们可以认为他是一个有着模拟值的线性神经元,并且通过设置权值为1来保持在每个时间步上自写相同的值,所以信息就能一直存在那里。这里的为 1 的权重是由保持门决定的,所以网络的剩余部分决定着那个逻辑保持门的状态,如果处在为1的状态或者接近1 ,那么信息只是在循环罢了,上图中的1.73的值就会一直存在,直到网络剩下的部分说不想要这个值了,那么所要做的就是将保持门设置成0,然后信息就消失了。为了存储信息到记忆单元,网络剩下部分需要打开写门,然后不论是从RNN剩下的部分中得到的输入是什么都会写入到这个记忆单元。相似的,为了从这个记忆单元中读信息,网络的剩下部分需要开启逻辑写门然后记忆单元中的值就会出来,然后影响RNN剩下的部分。
使用逻辑单元的关键在于我们可以通过BP 来穿过他们,因为他们有着很好的导数,也就是说我们可以学习并使用这种循环很多个时间步。

(一个时间步就是一个1.7为划分,视频中是动态讲的,我这里只是把最后的状态截图而已)这里介绍BP通过一个记忆单元是怎样子的。首先有个前馈操作:在初始时刻上,假设保持门是为0,所以可以擦除之前存储在记忆单元中的信息,然后把写门打开(设置为1),所以从RNN剩下部分来的1.7就会写入到记忆单元中,然后现在不想要进行读操作,所以将读门设置成0,然后将保持门设置成1,或者说是NN的剩下部分将保持门设置成1,这也就是说这个值又会写回到记忆单元中,这就是存储了。
在下一个时间步上,将写门设置成0,然后将读门设置成0,所以信息不受网络的其他部分影响。然后接着一个时间步,将保持门设置称1,所以信息可以接着存储一个时间步,然后将写门设置称0,所以没有信息可以写入,但是现在想检索这个信息,那么就设置读门为1,然后这个值1.7就会从记忆单元中出来然后影响网络的其他部分。如果我们不再需要它了,那么就把保持门设置成0,然后信息就会被擦除了。现在如果观察我们索引的时候出来的1.7,然后回头观察1.7进来的时候,这一路上的小三角型符号到下个小三角型符号都是1,也就是说这时候的权值是为1。所以正如我们回头沿着路径观察,不论我们在基于1.7上得到的误差导数是什么都是当检索的时候Bp从存储的1.7上获得的。如果想要检索一个更大的值,那么就将信息送回然后告诉他需要更大的值(也就是BP通过误差导数来调整并修改1.7的大小),记得一旦将相关的门设置成1,那么在BP信号中就没有衰减了(因为这时候不需要调整了,所以BP自然用不上了)。
刚好这样的特性就是我们所需要的,当然,如果这里的逻辑门有些许的轻微衰减,但是如果衰减足够小,信息还是能够坚持几百个时间步的。

现在来看一个采用长短时记忆的RNN完成的任务。这个任务对于RNN是轻而易举的,就是读取草书书写(估计就是人的各种手写字吧)。输入就是由(x,y)代表笔尖坐标的序列加上笔是否在纸上的信息。输出就是识别字符的序列。Graves和Schmidhuber在2009年显示有着长短时记忆的RNN特别的适合干这个任务。到目前为止,他们也是当前最好的能够完成这个任务的系统(这个课程出来的时间),并且Hinton认为加拿大post已经用他们来读取手写字体了。而在2009年这两个人没有使用笔的坐标作为输入,他们只是使用了小图像序列,这也就是说他们可以处理光学输入而不知道笔的时间(估计就是笔上纸到离开纸的时间吧),他们是通过收集写好的纸然后进行读取的。

所以这里介绍一个Alex Graves的系统的实例,这个系统是工作在笔坐标上的(就是通过笔在纸上划过的坐标,这具有实时性的意义,就是你写一个字,还没完成的时候,有可能这个网络就能识别出你要写的是什么字了)。在后续的视频(Hinton说的视频,就是最下面那张图)中,可以看到四条信息流,
1、顶层行显示他们所识别的字符,因为这个系统不会修改他的输出,所以在做这个艰难的决定(输出的结果到底是什么的问题)的时候需要延迟一小会儿来观察后续一小段的未来来帮助网络解决这个模棱两可的问题。
2、第二行显示记忆单元的子集中的状态,然后会注意到当识别一个字符的时候他们是如何重置的。
3、第三行显示实际的写的东西,而网络所全部能看见的就是笔尖的 x 和 y 的坐标,然后加上一些这个笔是否往上还是向下的信息。
4、最后第四行显示的是更复杂的。他显示梯度通过所有的路径后向传播到 x y 的位置。所以你所能看到的就是最有可能的字符,如果从那个字符上后向传播,然后问道怎样可以使得这个最有可能激活的字符变得更加的激活(就是更加的确定),那么就需要去观察到底输入的哪一位才是影响真实字符的概率的。所以你所做的决定都是基于以往发生的信息上的。
8:44-9:15,下面这张图就是一个从左到右的过程,下面第三行不断的写,第四行显示笔尖的位置,然后第二行显示网络的训练,然后第一行得到结果。(哇,这个网络好厉害。)
