Spark的容错机制
项目中会经常使用到Spark和Flink这些分布式框架,使用的时候老是担心如果出现异常了会怎样,今天就来了解下Spark以及Flink的容错机制。
容错是指一个系统部分出现错误的情况还能持续的提供服务,当集群达到较大的规模以后,很可以出机器故障以及网络延迟等情况,导致某个节点不能提供服务,所以分布式框架一般都会进行高容错设计。
Spark的容错机制:
Master异常退出:
个人理解是,只有StandAlone模式下才需要额外进行Master容错配置。如果是On Yarn模式,资源是由ResourceManager管理的,RM自身有容错机制,无需外部再进行配置了。
和HBase的HMaster很像,Spark会启动多个StandBy Master,当前Master异常时,会按照一定的规格选取其中一个接管Master的工作,有如下几种配置:
1. ZOOKEEPER
将集群元数据持久化到ZK中,基于ZK进行主备切换
2. FILESYSTEM
集群元数据持久化到白嫩地文件系统中
3. CUSTOM
用户自定义恢复方式
4. NONE
不持久化集群元数据。Master出现异常时,新启动的Master不进行恢复集群状态
这些策略在spark-env.sh配置文件中配置,配置项为spark.deploy.recoveryMode,默认为NODE。个人觉得生产环境下建议使用On Yarn模式,进行资源隔离比较好。如果非得使用Standalone,HA建议配置成ZK。
总结下就是Master会进行主备切换,接着移除未响应Master切换信息的driver(application)和Worker,然后重新调度driver执行。
case ElectedLeader => val (storedApps, storedDrivers, storedWorkers) = persistenceEngine.readPersistedData(rpcEnv) state = if (storedApps.isEmpty && storedDrivers.isEmpty && storedWorkers.isEmpty) { RecoveryState.ALIVE } else { RecoveryState.RECOVERING } logInfo("I have been elected leader! New state: " + state) if (state == RecoveryState.RECOVERING) { // 1. 先走这个方法,通知driver Master发生变更了 beginRecovery(storedApps, storedDrivers, storedWorkers) recoveryCompletionTask = forwardMessageThread.schedule(new Runnable { override def run(): Unit = Utils.tryLogNonFatalError { self.send(CompleteRecovery) } }, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS) } // 2. 重新调度任务执行 // Kill off any workers and apps that didn't respond to us // Reschedule drivers which were not claimed by any workers case CompleteRecovery => completeRecovery()
Worker异常退出:
个人理解是,Worker是StandAlone模式下才有的概念,On Yarn模式对应的是NodeManager,Yarn自身带有NodeManager的容错机制。
Spark Worker会保持和Master的心跳,当Worker出现超时时,Master调用timeOutDeadWorkers()方法进行处理,移除超时的Worker。移除时会通知Driver Executor已经移除(Executor异常处理详见下文),然后设置运行在当前Worker上的Driver重启或者直接删除:
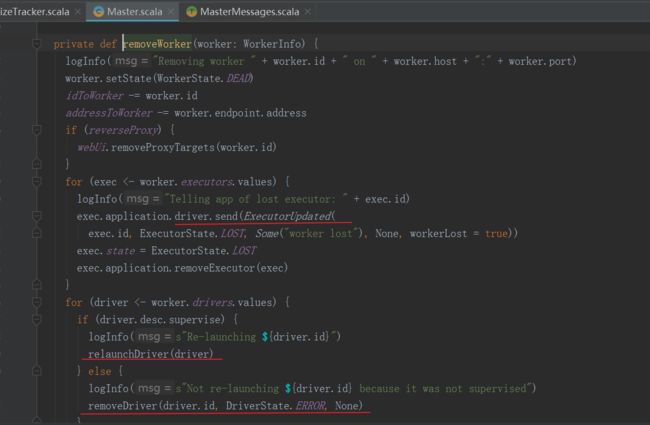
个人理解只有在cluster模式下启动时,才会有Driver的资源调度,如果在client模式下启动,Driver就在提交Job的机器上启动。关于Driver的重启策略这个还真不太清楚,有知道的朋友麻烦告知下...因为用的Client模式比较多,我理解driver挂了整个程序就挂了。
总结下就是Worker挂了会被Master移除,Worker上的Driver有可能会被重新调度执行或者直接移除。
Executor异常退出:
Executor是真正负责任务的执行,然后将任务的运行状态发送给Driver。
Executor发生异常时,外部的包装类ExecutorRunner会把异常信息发送给Worker,然后Worker会讲信息发送给Master。Master 接收到 Executor 状态变化消息后,如果发现 Executor 出现异常退出,则调用 Master.schedule 方法,尝试获取可用的 Worker 节点并重新启动 Executor。
重新启动一个新的Executor会尝试一定次数,如果还不成功,那么整个application就运行失败了。这样是为了保证application不会一直占用集群资源。
Spark Job Task的容错(即RDD的容错机制):
以上所讲的容错其实更多的是说Spark集群自身如何保证任务稳定运行,如果以上异常发生了,个人理解为本次Stage就运行失败了,幸好RDD有容错机制,可以恢复Job。Spark 会对运行失败的Stage进行retry,默认retry 3次。
RDD Lineage血统层容错:
Spark RDD实现基于Lineage的容错机制,基于RDD的各项transformation构成了compute chain,在部分计算结果丢失的时候可以根据Lineage重新恢复计算。
(1)在窄依赖中,在子RDD的分区丢失,要重算父RDD分区时,父RDD相应分区的所有数据都是子RDD分区的数据,并不存在冗余计算。
(2)在宽依赖情况下,丢失一个子RDD分区,重算的每个父RDD的每个分区的所有数据并不是都给丢失的子RDD分区用的,会有一部分数据相当于对应的是未丢失的子RDD分区中需要的数据,整个RDD都要重新计算,这样就会产生冗余计算开销和巨大的性能浪费。所以如果调用链路比较长的话,宽依赖最好做一次Checkpoint。
Checkpoint容错:
Lineage过长会造成容错成本过高,这时在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
总结:
1. 个人建议Spark尽量不要使用standalone,而是使用Yarn或者K8S等模式,这样可以做到更好的资源隔离。
2. 如果使用standalone,Master建议基于ZK配置高可用
3. Worker或者Executor异常退出没关系,Spark stage会重新执行调度。如果Spark job链路过长的话,建议在宽依赖那里执行CheckPoint,加快spark job的恢复。
参考:
https://blog.csdn.net/qq_32603475/article/details/103617089(Hadoop中Yarn的容错机制)
https://www.cnblogs.com/juncaoit/p/6542902.html(Spark容错特性)
https://www.jianshu.com/p/4e1b2d986883(Spark Master主备切换)
https://blog.csdn.net/u010886217/article/details/103289687(Spark RDD的容错机制)