DenseNet---《Densely Connected Convolutional Networks》
DenseNet—《Densely Connected Convolutional Networks》
这学期数字图像处理课程要求在课堂做一次presentation,于是选择了CVPR2017最佳论文《Densely Connected Convolutional Networks》。这篇论文的第一作者是两位中国学生,黄高和刘壮,简直是佩服。论文中作者创新性的提出了一种新的卷积神经网络架构,并将源代码和预训练的模型发布在了Github上,感兴趣的童鞋可以尝试一下。
摘要
最近的研究表明如果靠近输入的层和靠近输出的层之间的连接越短,卷积网络大体上能够更深、更精确、更高效的训练。在这篇论文中,作者进一步将这个观察发挥到了极致——让网络中的每一层与其前面的所有层相连,因此,一个 L L 层的网络拥有 L(L+1)2 L ( L + 1 ) 2 个连接,但 L L 层的传统卷积网络只包含 L L 个连接,因为每一层只与前面一层相连,所以作者将这个网络命名为DenseNet。对于DenseNet中的每一层,其前面所有层的特征图作为当前层的输入,同时当前层的特征图也作为其后每一层的输入。DenseNet有如下优点:减缓了梯度消失,增强了特征传播,促进了特征重用,降低了网络参数。在CIFAR-10,CIFAR-100,SVHN和ImageNet数据集上,DenseNet用更少的计算取得了最佳的效果。
相关研究与进展
卷积神经网络(CNNs)已经成为视觉目标识别最主要的机器学习方法。虽然LeNet5提出提出已有二十多年,但是直到最近计算机硬件发展和网络结构的改进,训练真正的深度CNNs才成为可能。目前,提高神经网络性能最直接的想法就是增加网络的深度,一种是增加网络的层数,最简单的全连接+批梯度下降,会随着网络层数的增加导致参数急剧增长,仅仅适用只有几百个参数的小网络。接着出现了跨层连接(skip-connection),例如:Highway Networks采用旁路(bypassing paths)和门单元(gating units),Residual Networks(ResNets)在网络中加入了恒等映射(identify mappings)等这些网络结构都实现了多层特征利用。另一种提升网络性能的方法是增加网络的宽度,GoogLeNet提出了“Inception”模块结合不同大小的卷积核。
DenseNets
DenseNets主要受到作者去年发表在ECCV的文章《Deep networks with stochastic depth》的启发:
- dropout:随机丢掉一些层,网络的性能并不会下降,这表明网络并不需要一个递进的层级结构,当前层可以利用前面几层的特征图。
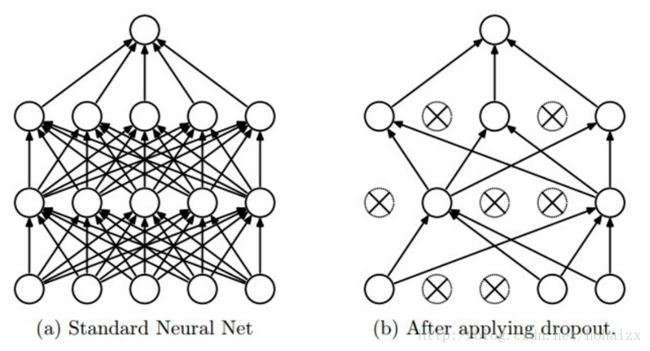
- ResNets:训练过程中随机扔掉很多层也不会破坏算法的收敛,说明了 ResNets 具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。
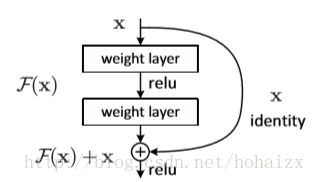
基于以上两点启发,作者提出了DenseNet,包含以下两个特点:
- 密集连接,让网络中的每一层都与其前面的每一层相连,实现特征重用。
- 每一层尽可能的窄,即每一层只学习很少的特征图,降低特征学习的冗余。
下图是一个5层的Dense block,每一层将前面的每一层的特征图作为输入。
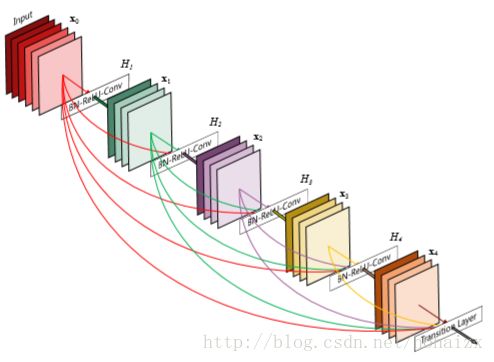
具体的,DenseNets由以下几个部分组成:
- Dense connectivity
最原始的卷积网络中,每一层的输入只与其前一层关联
上面提到的激活函数 Hl(⋅) H l ( ⋅ ) 级联了三个操作,即
卷积网络中下采样(down-sampling)是至关重要的一个步骤,为了实现下采样,DenseNets将网络划分成多个dense block,两个block之间的层称为Transition layers,由一个1*1的卷积层连接一个2*2的平均池化层组成。
- Bottleneck layers
即使是每一层只产生 k k 个特征图,网络也会因为密集连接有很多的输入,受GoogLeNet的启发,在3*3卷积之前加入一个1*1的卷积层以减少输入的特征图数目,这个1*1的卷积层被称为Bottleneck layers,同样由BN+ReLU+Conv(1*1)组成。含有Bottleneck layers的DenseNet被记作DenseNet-B。
- Compression
在Transition layers中,作者同样尝试减少了特征图数目
实验
下图是CIFAR、SVHN数据集上的网络示意图

ImageNet数据集上的网络配置
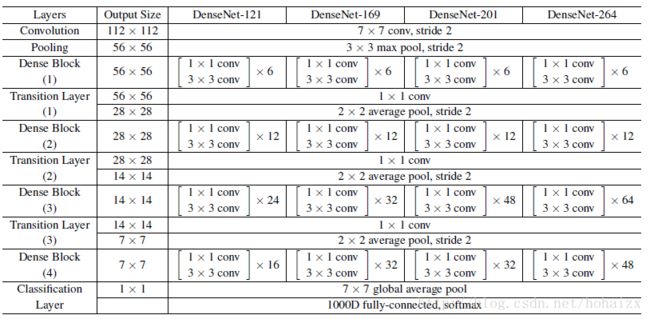
具体的,作者在训练中用到了以下技巧(tricks):
- 随机梯度下降(SGD)
- 动态学习速率
- 权重衰减(weight decay)
- 附加动量(momentum)
- dropout
实验结果
在CIFAR、SVHN和ImageNet中,DenseNet都取得了最佳性能。如下图标蓝结果展示了在CIFAR、SVHN数据集上DenseNet都取得了最佳效果:

对比倒数第二栏中的三个网络,可以发现随着网络参数从1.0M增加到7.0M最后到27.2M,网络的错误率由5.24%降低到4.10%最后到3.74%,这说明网络的容量在不断增大。另一个角度看,250层的DenseNet仅仅只有15.3M的参数,但是在C10+中取得了最佳的3.62%的结果,而Wide ResNet包含36.5M的参数,错误率却有4.17%,这表明DenseNet具有更高的参数效率。同样的,在C10+和C100+上ResNet和DenseNet到达接近的性能(错误率4.62%vs4.51%,22.71%vs22.27%),ResNet的参数是DenseNet的10被多(10.2M vs 0.8M)。
在IamgeNet上,同样得到了类似的结论

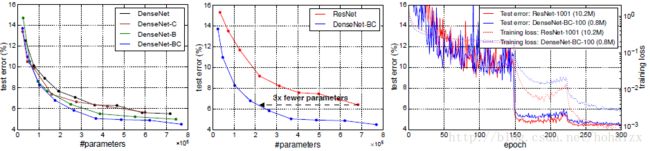
所以,随着网络层数的增加,网络的准确率不断上升,容量(capacity)也在逐渐增大;但是没有出现参数优化、过拟合等问题。
总结
作者提出了一种新的卷积神经网络结构,命名DenseNet。其创新性地将网络中任意两层直接相连,在多个数据集上达到了最佳效果。其主要有如下优点:
- 省参数:达到同样的准确率需要更少的参数
- 省计算:较少的参数,更高的计算效率
- 泛化性能好:综合利用浅层复杂度底的特征,决策函数函数更加平滑
参考文献
原文下载地址
CVPR 2017最佳论文作者解读:DenseNet 的“what”、“why”和“how”|CVPR 2017
本人总结的PPT