序言:ElasticSearch致力于隐藏分布式系统的复杂性,以下的操作都是在底层自动完成的:
将你的文档分区到不同的容器或者分片(shards),他们可以存在于一个或多个节点中
将分片均匀的分配到各个节点,对索引的搜索做负载均衡
冗余每一个分片,防止硬件故障造成的数据丢失
将集群中任意一个节点上的请求路由到相应数据所在的节点
无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移
一、集群内部工作方式
Elasticsearch用于构建高可用结可扩展的系统。扩展的方式可以是购买更好的服务器扩展(纵向扩展vertical scale or scaling up)或者购买更多的服务器(横向扩展horizontal scale or scaling out)
Elasticsearch虽然能从更强大的硬件中获得更好的额性能,但是纵向扩展有他的局限性,真正的扩展应该是横向的,它通过增加节点来均摊负载和增加可靠性。
对于大多数数据库来说,横向扩展意味着你的程序将做很大的改动才能利用这些新添加的设备,对比来说,Elasticsearch天生就是分布式的,它知道如何管理节点来提供高扩展和高可用。
二、空集群
如果我们启动一个单独的节点,他还没有数据和索引,这个集群看起来像:

一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,他们具有相同的cluster.name,他们协同工作,分享数据和负载,当加入新的节点或删除一个节点时,集群就会感知到并平衡数据。
集群中一个节点会被选举为主节点(master)他将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候该主节点不会成为集群的瓶颈,任何节点都可以成为主节点,当只有一个节点时,它就是主节点。
作为用户,我们能够与集群中的任何节点通信,包括主节点。每一个节点都知道文档存在于哪个节点上,他们可以转发请求到相应的节点上,我们访问的节点负责收集数据各节点返回的数据,最后一期返回给客户端,这一切都由Elasticsearch处理、
二、集群健康
在Elasticsearch集群中可以监控统计很多信息,但是只有一个是最重要的:集群健康(cluster health)。集群健康有三种状态:green yellow red
请求:GET /_cluster/health
如果是一个没有索引的空集群中查询,将返回:
{
"cluster_name": "elasticsearch",
"status": "green", <1> "timed_out": false, "number_of_nodes": 1, "number_of_data_nodes": 1, "active_primary_shards": 0, "active_shards": 0, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 0 }
<1>status字段提供一个综合的指标来表示集群的服务状况
green:所有主要分片和复制分片都可用
yellow:所有主要分片可用,但不是所有复制分片都可用
red:不是所有的主要分片都可用
三、添加索引
为了将数据添加到Elasticsearch,我们需要索引(index)一个存储关联数据的地方,实际上,索引知识一个用来指向一个或多个分片(shards)的逻辑命名空间(logical namespace)
一个分片(shard)是一个最小级别“工作单元(worker unit)”它只是保存了索引中所有数据的一部分。,一个分片就是一个Lucene实例,并且他本身就是一个完整的搜索引擎。
分片是Elasticsearch在集群中分发数据分关键,把分片想向成数据的容器,文档存储在分片中,然后分片分配到你集群中的节点上,当集群扩容或缩小elsticsearch将会自动在你的节点上迁移分片,使集群平衡。
分片 可以是主分片或者复制分片,你索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据
复制分片知识主分片的一个副本,他可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档
当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
我们在集群中唯一一个空节点上创建一个叫做blogs的索引,默认一个索引被分配5个主分片,目前我们只分片3个主分片和一个复制分片
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1 } }附带索引的单一节点集群:

这时我们检查集群健康:
{
"cluster_name": "elasticsearch",
"status": "yellow", <1> "timed_out": false, "number_of_nodes": 1, "number_of_data_nodes": 1, "active_primary_shards": 3, "active_shards": 3, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 3 <2> }<1>集群的状态现在是yellow
<2>我们的三个辅助分片还没有被分配到节点上
集群的健康状态yellow表示所有的主分片启动并且正常运行了--集群已经可以正常处理任何请求--但是复制分片还没有全部可用,事实上素有的三个复制分片现在都是unassigned状态,他们还没有被分配节点,在同一个节点上保存相同的数据副本是没有必要的,如果这个节点故障了,那所有的数据副本也会丢失、
四、增加故障转移
单一节点运行意味着单点故障的分析-没有数据备份。要防止故障,我们需要启动另一个节点
只要第二个节点与第一个节点有相同的cluster.name,他就能自动发现并加入第一个节点所在的集群,如果没有,可能是网络广播禁用,或防火墙阻止了节点通信。
双节点集群--所有的主分片和复制分片都已分配。
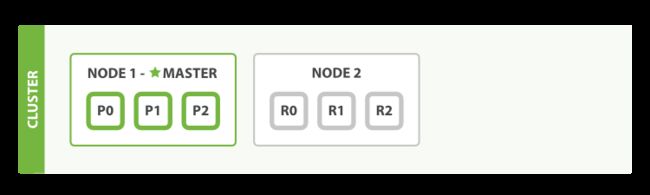
第二个节点已经加入集群,三个复制分配也已经被分配了--分别对应单个主分片,这表示丢失任意一个节点的时候依然可以保证数据的完整性、
文档的索引将首先被存储在主分片中,然后并发复制到对应的复制节点上,这可以确保我们的数据在主节点和复制节点上都可以被检索。
集群健康状态:
{
"cluster_name": "elasticsearch",
"status": "green", <1> "timed_out": false, "number_of_nodes": 2, "number_of_data_nodes": 2, "active_primary_shards": 3, "active_shards": 6, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 0 }
表明我们的集群不仅是功能完备的,而且是高可用的。
五、横向扩展
我们启动第三个节点。我们的集群将会重新组织自己
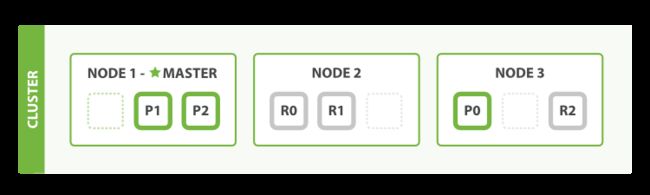
Node3包含了来自Node1和Node2的一个分片,这样每个节点就有两个分片,和之前相比少了一个,这意味着每个节点上的分片将获得更多的硬件资源。分片本身就是一个完整的搜索引擎,他可以使用单一节点的所有资源,我们拥有6个分片3主3副最多可以扩展到6个节点,每个节点有一个分片,每个分片可以100%使用这个节点的资源。
六。继续扩展
PUT /blogs/_settings
{
"number_of_replicas" : 2
}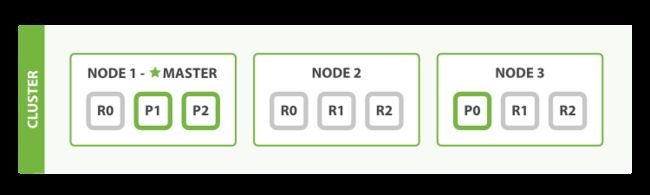
如果我们要扩展到6个以上的节点,我们可以将复制分片的数量增加以增加节点。
七、应对故障
如果我们杀掉一个节点的进程
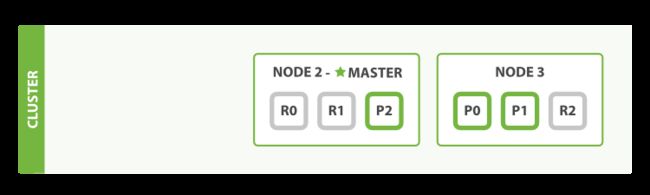
我们杀掉的是一个主节点,一个集群必须有一个主节点才能使其功能正常,所以集群做的第一件事就是各节点选举了一个新的主节点。
主分片1和2在我们杀掉node1时已经丢失,我们的索引在丢失主分片时不能正常工作,如果我们检查集群健康,将看到状态red,不是所有主节点都可用。
新主节点会将node2和node3上的复制分片升级为主分片,这是集群回到yellow状态。
为什么是yellow而不是green?
我们有三个主分片,但是我们指定每个主分片对应两个复制分片,当前却只有一个复制分片被分配,因此无法达到green。