目标检测 | 盘点提升小目标检测的思路
点击上方“AI算法修炼营”,选择加星标或“置顶”
标题以下,全是干货
来源:本文授权转自知乎作者高毅鹏,整理:极市平台
https://zhuanlan.zhihu.com/p/121666693,
未经作者允许,不得二次转载。
小目标检测在人脸检测领域还是目标检测领域都是难题,如何解决小目标问题成为研究者研究的热点。本文总结一些自己见过的小目标检测提升的思路,欢迎各位大佬讨论。
数据增强
数据增强方面,论文推荐Augmentation for small object detection。
小目标检测中的数据扩展(Augmentation for small object detection)[1]
Oversampling
我们通过相对少的包含小目标的在训练时过采样来解决样本少的问题。这个方法是花费最少并且最直接的方式来缓解MS COCO数据集并且改进在小目标检测中的表现。实验中,我们改变过采样率,探索过采样不仅仅在小目标检测,而且在中大型目标检测中同样有效。
Augmentation
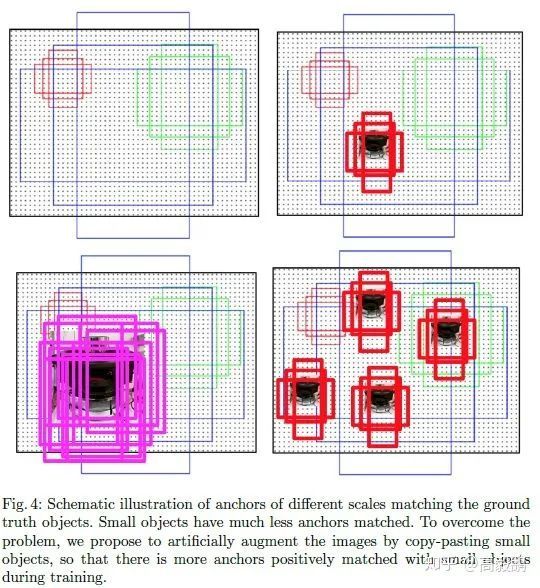
在 oversampleing 的基础上,我们还引入了针对小目标的数据集的 augmentation。MS COCO 数据集里实例分割中的 mask 使得我们可以将任何标注目标贴到图像中的任意位置。而通过增加每个图像中小目标的数量,匹配的 anchor 的数量也会随之增加,这进而提升了小目标在训练阶段对 loss 计算的贡献。
将目标粘贴到新位置之前,我们对其进行随机变换。目标缩放范围为±20%±20%,旋转范围为±15∘±15∘。复制时我们只考虑无遮挡的目标,防止图像太不真实。粘贴时确保新粘贴的目标不会与任何现有的对象发生重叠,并且距离图像边界至少有 5 个像素。
Figure 4,我们用图形说明了所提出的 augmentation 策略以及如何在训练中增加匹配 anchor 的数量,从而更好地检测小目标。
深度学习笔记(十)Augmentation for small object detection(翻译)[2]
这篇博客中有详细的介绍。此外常用数据增强方式expand对于小目标检测也有一定的提升作用。之前做过实现,去掉expand操作,模型对于小目标的检测能力大幅下降。
特征融合
RFBNet
不同尺度的特征融合,在扩大感受野的同时,也融合多个尺度的特征,增强了模型对于小目标的检测能力。
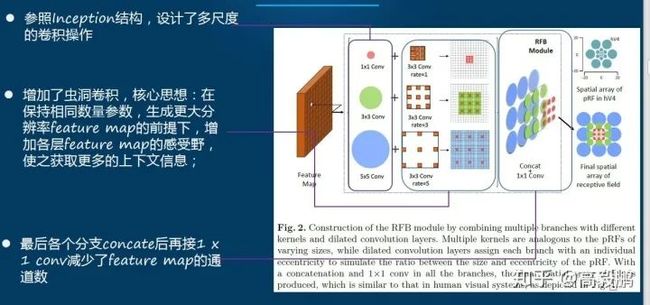
FPN
不同阶段的特征图对应的感受野不同,它们表达的信息抽象程度也不一样。**浅层的特征图感受野小,比较适合检测小目标(要检测大目标,则其只“看”到了大目标的一部分,有效信息不够);深层的特征图感受野大,适合检测大目标(要检测小目标,则其”看“到了太多的背景噪音,冗余噪音太多)**。所以,有人就提出了将不同阶段的特征图,都融合起来,来提升目标检测的性能,这就是特征金字塔网络[FPN](Feature Pyramid Networks for Object Detection[3])。
SSH
SSH中的上下文模块也是特征融合的的一种。上下文网络模块的作用是用于增大感受野,一般在two-stage 的目标检测模型当中,都是通过增大候选框的尺寸大小以合并得到更多的上下文信息,SSH通过单层卷积层的方法对上下文(context)信息进行了合并,其结构图如下图所示:
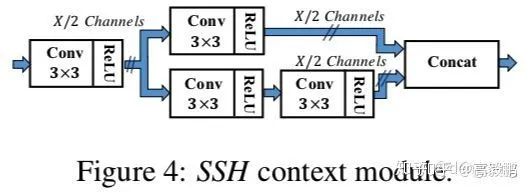
通过2个3✖️3的卷积层和3个3✖️3的卷积层并联,从而增大了卷积层的感受野,并作为各检测模块的目标尺寸。通过该方法构造的上下文的检测模块比候选框生成的方法具有更少的参数量,并且上下文模块可以在WIDER数据集上的AP提升0.5个百分点 。
利用上下文信息,或者目标之间建立联系
小目标,特别是像人脸这样的目标,不会单独地出现在图片中(想想单独一个脸出现在图片中,而没有头、肩膀和身体也是很恐怖的)。像[PyramidBox](PyramidBox: A Context-assisted Single Shot Face Detector[4])方法,加上一些头、肩膀这样的上下文Context信息,那么目标就相当于变大了一些,上下文信息加上检测也就更容易了。

这里顺便再提一下通用目标检测中另外一种加入Context信息的思路,[Relation Networks](Relation Networks for Object Detection[5])虽然主要是解决提升识别性能和过滤重复检测而不是专门针对小目标检测的,但是也和上面的PyramidBox思想很像的,都是利用上下文信息来提升检测性能,可以归类为Context一类。
在扩大感受野方面而言,RFB模块和PyramidBox的CPM模块都能达到扩大感受野的能力。具体用那个比较好,需要实验才能知道。
CPM模块代码
class CPM(nn.Module):
"""docstring for CPM"""
def __init__(self, in_plane):
super(CPM, self).__init__()
self.branch1 = conv_bn(in_plane, 1024, 1, 1, 0)
self.branch2a = conv_bn(in_plane, 256, 1, 1, 0)
self.branch2b = conv_bn(256, 256, 3, 1, 1)
self.branch2c = conv_bn(256, 1024, 1, 1, 0)
self.ssh_1 = nn.Conv2d(1024, 256, kernel_size=3, stride=1, padding=1)
self.ssh_dimred = nn.Conv2d(
1024, 128, kernel_size=3, stride=1, padding=1)
self.ssh_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
self.ssh_3a = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
self.ssh_3b = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out_residual = self.branch1(x)
x = F.relu(self.branch2a(x), inplace=True)
x = F.relu(self.branch2b(x), inplace=True)
x = self.branch2c(x)
rescomb = F.relu(x + out_residual, inplace=True)
ssh1 = self.ssh_1(rescomb)
ssh_dimred = F.relu(self.ssh_dimred(rescomb), inplace=True)
ssh_2 = self.ssh_2(ssh_dimred)
ssh_3a = F.relu(self.ssh_3a(ssh_dimred), inplace=True)
ssh_3b = self.ssh_3b(ssh_3a)
ssh_out = torch.cat([ssh1, ssh_2, ssh_3b], dim=1)
ssh_out = F.relu(ssh_out, inplace=True)
return ssh_out
RFB模块
class BasicRFB(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, scale=0.1, map_reduce=8, vision=1, groups=1):
super(BasicRFB, self).__init__()
self.scale = scale
self.out_channels = out_planes
inter_planes = in_planes // map_reduce
self.branch0 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2 * inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1), groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 1, dilation=vision + 1, relu=False, groups=groups)
)
self.branch1 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2 * inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1), groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 2, dilation=vision + 2, relu=False, groups=groups)
)
self.branch2 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, (inter_planes // 2) * 3, kernel_size=3, stride=1, padding=1, groups=groups),
BasicConv((inter_planes // 2) * 3, 2 * inter_planes, kernel_size=3, stride=stride, padding=1, groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 4, dilation=vision + 4, relu=False, groups=groups)
)
self.ConvLinear = BasicConv(6 * inter_planes, out_planes, kernel_size=1, stride=1, relu=False)
self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
out = self.ConvLinear(out)
short = self.shortcut(x)
out = out * self.scale + short
out = self.relu(out)
return out
两阶段检测小技巧:ROI pooling被ROI align替换
具体看
Jarvix贾博士:ROI Pooling和ROI Align[6]
GAN
Perceptual Generative Adversarial Networks for Small Object Detection中用使用感知生成式对抗网络(Perceptual GAN)提高小物体检测率,generator将小物体的poor表示转换成super-resolved的表示,discriminator与generator以竞争的方式分辨特征。Perceptual GAN挖掘不同尺度物体间的结构关联,提高小物体的特征表示,使之与大物体类似。包含两个子网络,生成网络和感知分辨网络。生成网络是一个深度残差特征生成模型,通过引入低层精细粒度的特征将原始的较差的特征转换为高分变形的特征。分辨网络一方面分辨小物体生成的高分辨率特征与真实大物体特征,另一方面使用感知损失提升检测率。在交通标志数据库Tsinghua-Tencent 100k及Caltech上实验。具体可以参考博客
目标检测“Perceptual Generative Adversarial Networks for Small Object Detection”[7]
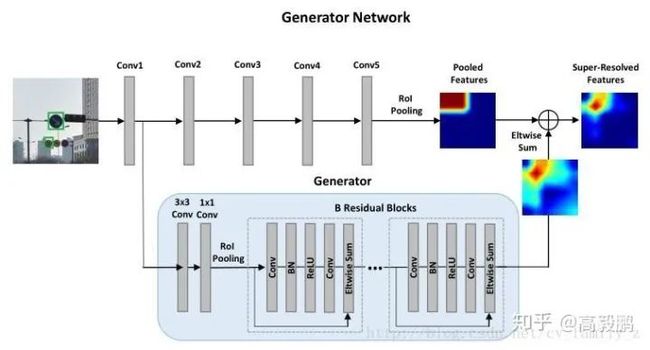
提升图像分辨率
增大输入分辨率来提升小目标的检测能力。
锚点设计
匹配策略,不用IoU
参考:
[1]小目标检测中的数据扩展(Augmentation for small object detection): https://blog.csdn.net/abrams90/article/details/89371797
[2]深度学习笔记(十)Augmentation for small object detection(翻译): https://www.cnblogs.com/xuanyuyt/p/11328548.html
[3][FPN]([Feature Pyramid Networks for Object Detection: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1612.03144
[4]PyramidBox]([PyramidBox: A Context-assisted Single Shot Face Detector: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1803.07737
[5]Relation Networks]([Relation Networks for Object Detection: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1711.11575
[6]Jarvix贾博士:ROI Pooling和ROI Align: https://zhuanlan.zhihu.com/p/73138740
[7]目标检测“Perceptual Generative Adversarial Networks for Small Object Detection”: https://blog.csdn.net/c2a2o2/article/details/78619614
目标检测系列秘籍一:模型加速之轻量化网络秘籍二:非极大值抑制及回归损失优化秘籍三:多尺度检测秘籍四:数据增强秘籍五:解决样本不均衡问题秘籍六:Anchor-Free视觉注意力机制系列Non-local模块与Self-attention之间的关系与区别?视觉注意力机制用于分类网络:SENet、CBAM、SKNetNon-local模块与SENet、CBAM的融合:GCNet、DANetNon-local模块如何改进?来看CCNet、ANN
语义分割系列一篇看完就懂的语义分割综述最新实例分割综述:从Mask RCNN 到 BlendMask超强视频语义分割算法!基于语义流快速而准确的场景解析CVPR2020 | HANet:通过高度驱动的注意力网络改善城市场景语义分割
基础积累系列卷积神经网络中的感受野怎么算?
图片中的绝对位置信息,CNN能搞定吗?理解计算机视觉中的损失函数深度学习相关的面试考点总结
自动驾驶学习笔记系列 Apollo Udacity自动驾驶课程笔记——高精度地图、厘米级定位 Apollo Udacity自动驾驶课程笔记——感知、预测 Apollo Udacity自动驾驶课程笔记——规划、控制自动驾驶系统中Lidar和Camera怎么融合?
竞赛与工程项目分享系列如何让笨重的深度学习模型在移动设备上跑起来基于Pytorch的YOLO目标检测项目工程大合集目标检测应用竞赛:铝型材表面瑕疵检测基于Mask R-CNN的道路物体检测与分割
SLAM系列视觉SLAM前端:视觉里程计和回环检测视觉SLAM后端:后端优化和建图模块视觉SLAM中特征点法开源算法:PTAM、ORB-SLAM视觉SLAM中直接法开源算法:LSD-SLAM、DSO视觉SLAM中特征点法和直接法的结合:SVO
2020年最新的iPad Pro上的激光雷达是什么?来聊聊激光SLAM