1. 背景
XGBoost模型作为机器学习中的一大“杀器”,被广泛应用于数据科学竞赛和工业领域,XGBoost官方也提供了可运行于各种平台和环境的对应代码,如适用于Spark分布式训练的XGBoost on Spark。然而,在XGBoost on Spark的官方实现中,却存在一个因XGBoost缺失值和Spark稀疏表示机制而带来的不稳定问题。
事情起源于美团内部某机器学习平台使用方同学的反馈,在该平台上训练出的XGBoost模型,使用同一个模型、同一份测试数据,在本地调用(Java引擎)与平台(Spark引擎)计算的结果不一致。但是该同学在本地运行两种引擎(Python引擎和Java引擎)进行测试,两者的执行结果是一致的。因此质疑平台的XGBoost预测结果会不会有问题?
该平台对XGBoost模型进行过多次定向优化,在XGBoost模型测试时,并没有出现过本地调用(Java引擎)与平台(Spark引擎)计算结果不一致的情形。而且平台上运行的版本,和该同学本地使用的版本,都来源于Dmlc的官方版本,JNI底层调用的应该是同一份代码,理论上,结果应该是完全一致的,但实际中却不同。
从该同学给出的测试代码上,并没有发现什么问题:
//测试结果中的一行,41列
double[] input = new double[]{1, 2, 5, 0, 0, 6.666666666666667, 31.14, 29.28, 0, 1.303333, 2.8555, 2.37, 701, 463, 3.989, 3.85, 14400.5, 15.79, 11.45, 0.915, 7.05, 5.5, 0.023333, 0.0365, 0.0275, 0.123333, 0.4645, 0.12, 15.082, 14.48, 0, 31.8425, 29.1, 7.7325, 3, 5.88, 1.08, 0, 0, 0, 32];
//转化为float[]
float[] testInput = new float[input.length];
for(int i = 0, total = input.length; i < total; i++){
testInput[i] = new Double(input[i]).floatValue();
}
//加载模型
Booster booster = XGBoost.loadModel("${model}");
//转为DMatrix,一行,41列
DMatrix testMat = new DMatrix(testInput, 1, 41);
//调用模型
float[][] predicts = booster.predict(testMat);上述代码在本地执行的结果是333.67892,而平台上执行的结果却是328.1694030761719。
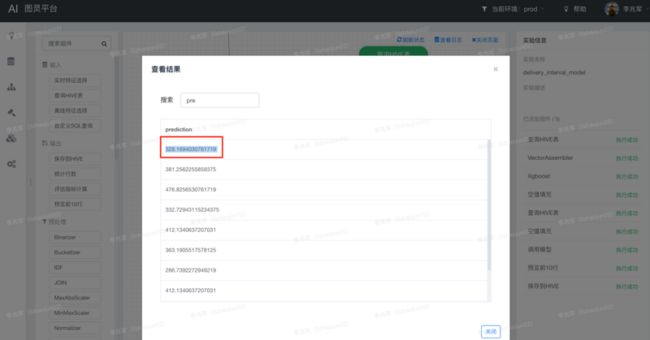
两次结果怎么会不一样,问题出现在哪里呢?
2. 执行结果不一致问题排查历程
如何排查?首先想到排查方向就是,两种处理方式中输入的字段类型会不会不一致。如果两种输入中字段类型不一致,或者小数精度不同,那结果出现不同就是可解释的了。仔细分析模型的输入,注意到数组中有一个6.666666666666667,是不是它的原因?
一个个Debug仔细比对两侧的输入数据及其字段类型,完全一致。
这就排除了两种方式处理时,字段类型和精度不一致的问题。
第二个排查思路是,XGBoost on Spark按照模型的功能,提供了XGBoostClassifier和XGBoostRegressor两个上层API,这两个上层API在JNI的基础上,加入了很多超参数,封装了很多上层能力。会不会是在这两种封装过程中,新加入的某些超参数对输入结果有着特殊的处理,从而导致结果不一致?
与反馈此问题的同学沟通后得知,其Python代码中设置的超参数与平台设置的完全一致。仔细检查XGBoostClassifier和XGBoostRegressor的源代码,两者对输出结果并没有做任何特殊处理。
再次排除了XGBoost on Spark超参数封装问题。
再一次检查模型的输入,这次的排查思路是,检查一下模型的输入中有没有特殊的数值,比方说,NaN、-1、0等。果然,输入数组中有好几个0出现,会不会是因为缺失值处理的问题?
快速找到两个引擎的源码,发现两者对缺失值的处理真的不一致!
XGBoost4j中缺失值的处理
XGBoost4j缺失值的处理过程发生在构造DMatrix过程中,默认将0.0f设置为缺失值:
/**
* create DMatrix from dense matrix
*
* @param data data values
* @param nrow number of rows
* @param ncol number of columns
* @throws XGBoostError native error
*/
public DMatrix(float[] data, int nrow, int ncol) throws XGBoostError {
long[] out = new long[1];
//0.0f作为missing的值
XGBoostJNI.checkCall(XGBoostJNI.XGDMatrixCreateFromMat(data, nrow, ncol, 0.0f, out));
handle = out[0];
}XGBoost on Spark中缺失值的处理
而xgboost on Spark将NaN作为默认的缺失值。
/**
* @return A tuple of the booster and the metrics used to build training summary
*/
@throws(classOf[XGBoostError])
def trainDistributed(
trainingDataIn: RDD[XGBLabeledPoint],
params: Map[String, Any],
round: Int,
nWorkers: Int,
obj: ObjectiveTrait = null,
eval: EvalTrait = null,
useExternalMemory: Boolean = false,
//NaN作为missing的值
missing: Float = Float.NaN,
hasGroup: Boolean = false): (Booster, Map[String, Array[Float]]) = {
//...
}也就是说,本地Java调用构造DMatrix时,如果不设置缺失值,默认值0被当作缺失值进行处理。而在XGBoost on Spark中,默认NaN会被为缺失值。原来Java引擎和XGBoost on Spark引擎默认的缺失值并不一样。而平台和该同学调用时,都没有设置缺失值,造成两个引擎执行结果不一致的原因,就是因为缺失值不一致!
修改测试代码,在Java引擎代码上设置缺失值为NaN,执行结果为328.1694,与平台计算结果完全一致。
//测试结果中的一行,41列
double[] input = new double[]{1, 2, 5, 0, 0, 6.666666666666667, 31.14, 29.28, 0, 1.303333, 2.8555, 2.37, 701, 463, 3.989, 3.85, 14400.5, 15.79, 11.45, 0.915, 7.05, 5.5, 0.023333, 0.0365, 0.0275, 0.123333, 0.4645, 0.12, 15.082, 14.48, 0, 31.8425, 29.1, 7.7325, 3, 5.88, 1.08, 0, 0, 0, 32];
float[] testInput = new float[input.length];
for(int i = 0, total = input.length; i < total; i++){
testInput[i] = new Double(input[i]).floatValue();
}
Booster booster = XGBoost.loadModel("${model}");
//一行,41列
DMatrix testMat = new DMatrix(testInput, 1, 41, Float.NaN);
float[][] predicts = booster.predict(testMat);3. XGBoost on Spark源码中缺失值引入的不稳定问题
然而,事情并没有这么简单。
Spark ML中还有隐藏的缺失值处理逻辑:SparseVector,即稀疏向量。
SparseVector和DenseVector都用于表示一个向量,两者之间仅仅是存储结构的不同。其中,DenseVector就是普通的Vector存储,按序存储Vector中的每一个值。
而SparseVector是稀疏的表示,用于向量中0值非常多场景下数据的存储。
SparseVector的存储方式是:仅仅记录所有非0值,忽略掉所有0值。具体来说,用一个数组记录所有非0值的位置,另一个数组记录上述位置所对应的数值。有了上述两个数组,再加上当前向量的总长度,即可将原始的数组还原回来。
因此,对于0值非常多的一组数据,SparseVector能大幅节省存储空间。
SparseVector存储示例见下图:
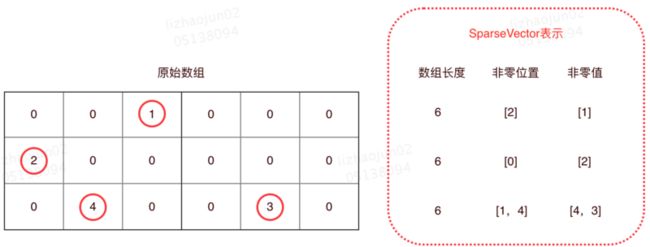
如上图所示,SparseVector中不保存数组中值为0的部分,仅仅记录非0值。因此对于值为0的位置其实不占用存储空间。下述代码是Spark ML中VectorAssembler的实现代码,从代码中可见,如果数值是0,在SparseVector中是不进行记录的。
private[feature] def assemble(vv: Any*): Vector = {
val indices = ArrayBuilder.make[Int]
val values = ArrayBuilder.make[Double]
var cur = 0
vv.foreach {
case v: Double =>
//0不进行保存
if (v != 0.0) {
indices += cur
values += v
}
cur += 1
case vec: Vector =>
vec.foreachActive { case (i, v) =>
//0不进行保存
if (v != 0.0) {
indices += cur + i
values += v
}
}
cur += vec.size
case null =>
throw new SparkException("Values to assemble cannot be null.")
case o =>
throw new SparkException(s"$o of type ${o.getClass.getName} is not supported.")
}
Vectors.sparse(cur, indices.result(), values.result()).compressed
}不占用存储空间的值,也是某种意义上的一种缺失值。SparseVector作为Spark ML中的数组的保存格式,被所有的算法组件使用,包括XGBoost on Spark。而事实上XGBoost on Spark也的确将Sparse Vector中的0值直接当作缺失值进行处理:
val instances: RDD[XGBLabeledPoint] = dataset.select(
col($(featuresCol)),
col($(labelCol)).cast(FloatType),
baseMargin.cast(FloatType),
weight.cast(FloatType)
).rdd.map { case Row(features: Vector, label: Float, baseMargin: Float, weight: Float) =>
val (indices, values) = features match {
//SparseVector格式,仅仅将非0的值放入XGBoost计算
case v: SparseVector => (v.indices, v.values.map(_.toFloat))
case v: DenseVector => (null, v.values.map(_.toFloat))
}
XGBLabeledPoint(label, indices, values, baseMargin = baseMargin, weight = weight)
}XGBoost on Spark将SparseVector中的0值作为缺失值为什么会引入不稳定的问题呢?
重点来了,Spark ML中对Vector类型的存储是有优化的,它会自动根据Vector数组中的内容选择是存储为SparseVector,还是DenseVector。也就是说,一个Vector类型的字段,在Spark保存时,同一列会有两种保存格式:SparseVector和DenseVector。而且对于一份数据中的某一列,两种格式是同时存在的,有些行是Sparse表示,有些行是Dense表示。选择使用哪种格式表示通过下述代码计算得到:
/**
* Returns a vector in either dense or sparse format, whichever uses less storage.
*/
@Since("2.0.0")
def compressed: Vector = {
val nnz = numNonzeros
// A dense vector needs 8 * size + 8 bytes, while a sparse vector needs 12 * nnz + 20 bytes.
if (1.5 * (nnz + 1.0) < size) {
toSparse
} else {
toDense
}
}在XGBoost on Spark场景下,默认将Float.NaN作为缺失值。如果数据集中的某一行存储结构是DenseVector,实际执行时,该行的缺失值是Float.NaN。而如果数据集中的某一行存储结构是SparseVector,由于XGBoost on Spark仅仅使用了SparseVector中的非0值,也就导致该行数据的缺失值是Float.NaN和0。
也就是说,如果数据集中某一行数据适合存储为DenseVector,则XGBoost处理时,该行的缺失值为Float.NaN。而如果该行数据适合存储为SparseVector,则XGBoost处理时,该行的缺失值为Float.NaN和0。
即,数据集中一部分数据会以Float.NaN和0作为缺失值,另一部分数据会以Float.NaN作为缺失值! 也就是说在XGBoost on Spark中,0值会因为底层数据存储结构的不同,同时会有两种含义,而底层的存储结构是完全由数据集决定的。
因为线上Serving时,只能设置一个缺失值,因此被选为SparseVector格式的测试集,可能会导致线上Serving时,计算结果与期望结果不符。
4. 问题解决
查了一下XGBoost on Spark的最新源码,依然没解决这个问题。
赶紧把这个问题反馈给XGBoost on Spark, 同时修改了我们自己的XGBoost on Spark代码。
val instances: RDD[XGBLabeledPoint] = dataset.select(
col($(featuresCol)),
col($(labelCol)).cast(FloatType),
baseMargin.cast(FloatType),
weight.cast(FloatType)
).rdd.map { case Row(features: Vector, label: Float, baseMargin: Float, weight: Float) =>
//这里需要对原来代码的返回格式进行修改
val values = features match {
//SparseVector的数据,先转成Dense
case v: SparseVector => v.toArray.map(_.toFloat)
case v: DenseVector => v.values.map(_.toFloat)
}
XGBLabeledPoint(label, null, values, baseMargin = baseMargin, weight = weight)
} /**
* Converts a [[Vector]] to a data point with a dummy label.
*
* This is needed for constructing a [[ml.dmlc.xgboost4j.scala.DMatrix]]
* for prediction.
*/
def asXGB: XGBLabeledPoint = v match {
case v: DenseVector =>
XGBLabeledPoint(0.0f, null, v.values.map(_.toFloat))
case v: SparseVector =>
//SparseVector的数据,先转成Dense
XGBLabeledPoint(0.0f, null, v.toArray.map(_.toFloat))
}问题得到解决,而且用新代码训练出来的模型,评价指标还会有些许提升,也算是意外之喜。
希望本文对遇到XGBoost缺失值问题的同学能够有所帮助,也欢迎大家一起交流讨论。
作者简介
- 兆军,美团配送事业部算法平台团队技术专家。
招聘信息
美团配送事业部算法平台团队,负责美团一站式大规模机器学习平台图灵平台的建设。围绕算法整个生命周期,利用可视化拖拽方式定义模型训练和预测流程,提供强大的模型管理、线上模型预测和特征服务能力,提供多维立体的AB分流支持和线上效果评估支持。团队的使命是为算法相关同学提供统一的,端到端的,一站式自助服务平台,帮助算法同学降低算法研发复杂度,提升算法迭代效率。
现面向数据工程,数据开发,算法工程,算法应用等领域招聘资深研发工程师/技术专家/方向负责人(机器学习平台/算法平台),欢迎有兴趣的同学一起加入,简历可投递至:[email protected](注明:美团配送事业部)