一本通提高篇 KMP算法
扯淡
这么想想 初中时第一次到高中部听学长讲课就是 K M P KMP KMP 看毛片算法
还是大哥 M i c h a e l _ B r y a n t Michael\_Bryant Michael_Bryant给我讲的呢 那应该是我跟大哥第一次奔现 正式见面
(他还搂了我好几下 现在我抱他他还说我 g a y ? gay? gay?
行了不搞了 说正事吧
K M P KMP KMP算法
K M P KMP KMP算法是用来处理字符串匹配问题的,由 D . E . K n u t h , J . H . M o r r i s D.E.Knuth,J.H.Morris D.E.Knuth,J.H.Morris和 V . R . P r a t t V.R.Pratt V.R.Pratt共同提出的。字符串匹配就是给你个大串 A A A和小串 B B B,让你求 A A A中出现了几次 B B B。其中如果 A A A中有 B B B,那么我们就称 B B B是 A A A的子串。
算法流程
假如, A = a b a b a b a a b a b a c b , B = a b a b a c b A=abababaababacb,B=ababacb A=abababaababacb,B=ababacb,我们来看一看 K M P KMP KMP是怎么工作的。我们用两个指针 i i i和 j j j分别表示, A [ i − j + 1... i ] A[i-j+1...i] A[i−j+1...i]与 B [ 1... j ] B[1...j] B[1...j]完全相等。也就是说, i i i是不断增加的,随着 i i i的增加, j j j相应地变化,且 j j j满足以 A [ i ] A[i] A[i]结尾的长度为 i i i的字符串正好匹配 B B B的前 j j j个字符,现在需要检验 A [ i + 1 ] A[i+1] A[i+1]和 B [ j + 1 ] B[j+1] B[j+1]的关系。当 A [ i + 1 ] = B [ j + 1 ] A[i+1]=B[j+1] A[i+1]=B[j+1]时, i i i和 j j j各加一;当 j = m j=m j=m时,我们就说 B B B是 A A A的子串( B B B串已经完全匹配了),并且可以根据这时的值算出匹配的位置。当 A [ i + 1 ] ≠ B [ j + 1 ] A[i+1]\neq B[j+1] A[i+1]=B[j+1], K M P KMP KMP的策略是调整 j j j的位置(减小 j j j值)使得 A [ i − j + 1... i ] A[i-j+1...i] A[i−j+1...i]与 B [ 1... j ] B[1...j] B[1...j]保持匹配且尝试匹配新的 A [ i + 1 ] A[i+1] A[i+1]与
与 B [ j + 1 ] B[j+1] B[j+1]。
口胡了这么多 相信你肯定也是一脸懵 先不说流程听没听懂 怎么代码实现啊!!??
真正演示一遍才能得出真正的答案 b i l i b i l i bilibili bilibili上有个大哥讲的可好了 我第二次听 K M P KMP KMP就是跟他学的
传送门
 o k k okk okk看完了相信你一定会了 那么我们直接上题吧
o k k okk okk看完了相信你一定会了 那么我们直接上题吧
诶诶别揍我 哥我错了
先粘一道洛谷的模板题
P3375 【模板】KMP字符串匹配
分两步走 先求 n e x t next next数组再进行 K M P KMP KMP
需要注意到的是 跟视频不同的一点 我们的 n e x t next next数组整体右移了一位,这样不仅方便求解 n e x t next next数组,在 K M P KMP KMP匹配中我们也不用调用前一位的 n e x t next next值
求解 n e x t next next数组:
void get_nxt(){
int j=0;
for(int i=1;i<l2;i++){
while(j&&s2[i+1]!=s2[j+1])j=nxt[j];
if(s2[i+1]==s2[j+1])nxt[i+1]=++j;
}
}
都说可以把求解 n e x t next next数组理解成自我匹配,但我感觉更像一个贪心算法
下面是 K M P KMP KMP的过程:
int j=0;
for(int i=0;i<l1;i++){
while(j&&s1[i+1]!=s2[j+1])j=nxt[j];
if(s1[i+1]==s2[j+1])j++;
if(j==l2){
j=nxt[j];
printf("%d\n",i+2-l2);
}
}
没什么好说的 视频里说的真是太详细了 除了字幕是机翻之外真没啥毛病
上这个题的代码:
#include看了看网上的题解 自认为写的算是比较简洁的了
那么现在我们上一本通里的题吧:
剪花布条
题目描述
一块花布条,里面有些图案,另有一块直接可用的小饰条,里面也有一些图案。对于给定的花布条和小饰条,计算一下能从花布条中尽可能剪出几块小饰条来呢?
输入
输入中含有一些数据,分别是成对出现的花布条和小饰条,其布条都是用可见ASCII字符表示的,可见的ASCII字符有多少个,布条的花纹也有多少种花样。花纹条和小饰条不会超过1000个字符长。如果遇见#字符,则不再进行工作。
输出
输出能从花纹布中剪出的最多小饰条个数,如果一块都没有,那就老老实实输出0,每个结果之间应换行
样例输入
abcde a3
aaaaaa aa
样例输出
0
3
提示
你猜
S o l u t i o n : K M P Solution:KMP Solution:KMP果题 注意细节就是花布条剪完了就不能再匹配了,所以相较模板要把匹配时的 j = n x t [ j ] j=nxt[j] j=nxt[j]改成 j = 0 j=0 j=0
#includeRadio Transmission
题面
S o l u t i o n : Solution: Solution:手动写写画画不难发现 n − n x t [ n ] n-nxt[n] n−nxt[n]的值就是答案
#includePeriods of Words
题面
S o l u t i o n : Solution: Solution:本题的考察点主要是阅读理解 其次是 K M P KMP KMP算法
将题面转换成类人话:
一个字符串 A A A 它的一个子串 B B B如果满足 A A A是 B B BB BB的子串 就称 B B B是 A A A 的一个周期。如下图
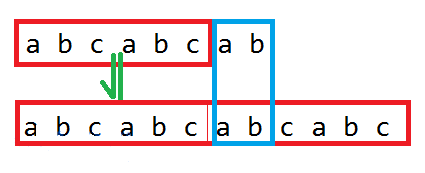
给定一个字符串,求它的所有前缀的最大周期长度之和
这个题要用到 n x t nxt nxt数组的一个性质:长度为 n x t [ i ] nxt[i] nxt[i]的前缀和后缀相等
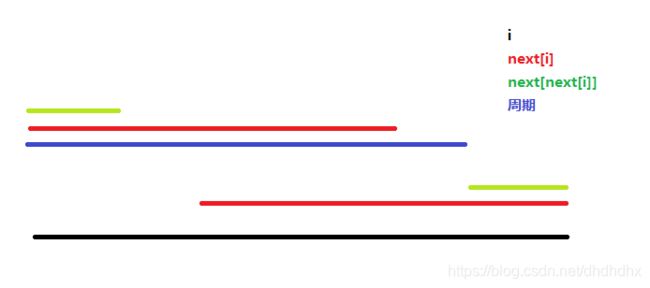
那么不难发现 如果长度为 i i i字符串 A A A的长度为 n x t [ i ] nxt[i] nxt[i]的前缀有一个长度为 j j j的前后缀 那么字符串 A A A就有一个长度为 i − j i-j i−j的周期
所以对于每一个前缀 i i i我们要找到最小的 j j j 周期 i − j i-j i−j最大
那就每次递归到 0 0 0之前的一个 n x t nxt nxt数组的值 显然这时候的 j j j最小
好像还有一个很可行的优化 就是每次找到 j j j之后 直接把 n x t [ i ] nxt[i] nxt[i]改成 j j j,就像并查集路径压缩一样
因为现在我们不匹配,不需要让 n x t nxt nxt数组最大来保持时间复杂度,反而 n x t nxt nxt数组越小递归层数越小时间复杂度越优
P S . PS. PS.建议开 l o n g l o n g long \,\,long longlong,其实可以试试不开的!
#include似乎在梦中见过的样子
题面
哇这个题真的狗
我想了差不多一天多的时间
首先想到的是 O ( n 3 ) O(n^3) O(n3)的做法 枚举每个左端点 在求 n x t nxt nxt值的过程中枚举右端点 对于每个子串 递归 n x t nxt nxt当 j = n x t j=nxt j=nxt时 如果满足 k ≤ j k\le j k≤j且 2 j < i 2j2j<i,那么 a n s + + ans++ ans++
这显然是 O ( n 3 ) O(n^3) O(n3)的算法 那么我们怎么优化一下呢?
跟上一道题一样 对于每次递归 我们可以相当于给他路径压缩一下
设 f [ x ] f[x] f[x]为在右端点为 x x x时 可以满足条件的最小的长度 如果没有则为 i n f inf inf
那么我们每次更新 f [ x ] = m i n { x , f [ n x t [ x ] ] } f[x]=min\{x,f[nxt[x]]\} f[x]=min{x,f[nxt[x]]} 这样显然可以 O ( 1 ) O(1) O(1)转移和求值 复杂度就降到了 O ( n 2 ) O(n^2) O(n2)
代码
#include什么傻逼玩意 调了一个小时 艹
Censoring
题面
听说是 k m p kmp kmp加栈 但是我不想打 心情极度不爽 现在只想打哈希
算了 哈希也得加栈 写 K M P KMP KMP吧
记录一个 f [ i ] f[i] f[i]表示 i i i这里能匹配到的最大的 j j j
栈里放的是数组下标 每次如果成功匹配到就把 t o p − = l e n top-=len top−=len, j = f [ t o p ] j=f[top] j=f[top]
完事 上代码
#include唉做完这道题其实我心里挺不是滋味的
![]()
还记得当时贯通部来高中上体验课时 那时刚在高中网站拿到账号时 自己因为有 O I OI OI基础所以刷题数比大家都多
后来 n s y nsy nsy把我超了 然后那天我一下子超过他 50 50 50多道题哈哈哈
还开玩笑说 你超我一道 我超你十道 h h h hhh hhh想想那时课真是快乐
再后来 牛哥好像钟爱上了动态规划 加上自己主动&被动刷水题 网站名次早就落得我远远的 (其实他有抄代码的嫌疑
再再后来 我也进入了颓废不学习不做题的初二 自从那年过去 我再也没能有机会在榜上的排名骄傲起来 但是我也没因为这个虚心学习…真是可惜hhh
今天做完这五道题刚好超了牛哥 如果不是意外的话 想想以牛哥找水题的速度 我应该一天就被拉出去好几道题哈哈
2333 人生无常 珍惜现在
希望大家都能有个好的未来吧…
)//有左括号不能没有右括号
总结
K M P KMP KMP算法是一个很牛掰的算法 但是真考验思维…想到正解你会发现 K M P KMP KMP这么有用! 想不到正解你会认为 K M P KMP KMP真是垃圾
P S : PS: PS:今天 11.26 11.26 11.26祝我们的宝贝儿 l y s s lyss lyss生日快乐!!!
连续两晚加班终于搞完了
尽请关注下一章的 t r i e trie trie树 可能以后会越来越墨迹 我可能会跳章写