StringBuffer的内存溢出实例(转自Ahuaxuan的文章)
Ahuaxuan在公司属于大牛级别的人物,技术理解深入,口才更好,人品也好。
转载这篇文章,想做个JVM方面的专题:
Ahuaxuan的这篇文章写得很好,做个转载,过段时间准备制成PDF。
/*
- @author: ahuaxuan
- @date: 2010-4-30
- /
在内存充裕的情况下的OOM
理解本文的前提是理解JVM的内存模型:包括
perm, old, young(eden, from(s0), to(s1)),
然后理解young中的垃圾搜集算法(拷贝算法,尤其是eden, from(s0),
to(s1)它们分别扮演什么样的角色,为什么任意时间中from和to中必须要有一个是空的), old里的垃圾搜索算法(常见的有:标记压缩算法).
正文:
最近一台测试服务器抛出了OOM的错误,本着不放过一切问题的原则,ahuaxuan把这个OOM研究了一番,最后得出了令人意想不到的结论.
charpter 1, 现象
看到这个OOM的信息之后,ahuaxuan的第一反应是,内存是否真的不够用了,于是使用jmap查看了一下内存的情况,如下:
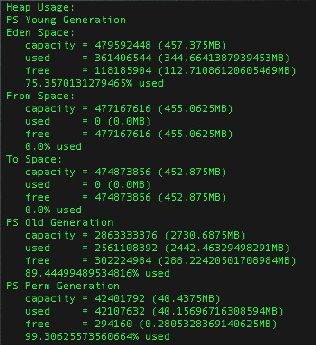
我们的测试服务器给JVM进程分配的空间是4G,但是从上图中,我们可以看出内存并没有完全用完,尤其是From和TO这两个suvivor空间居然还有900M的空间剩余. Eden 也有112M的空间剩余,Old有288M的空间剩余.
这个不像是空间不足的情况.除非我们的对象真的有这么大,大到超过288M,不管eden还是old都放不下.一个对象要超过300M,那这是一个什么样的对象呀,初步分析,这个对象应该是一个byte数组或者char数组.
charpter2 大对象来源
为了追到这个问题,接下来就是把heap的dump信息拿出来,通过 jmap -dump:format=b,file=heap.bin
然后用MAT打开一看.
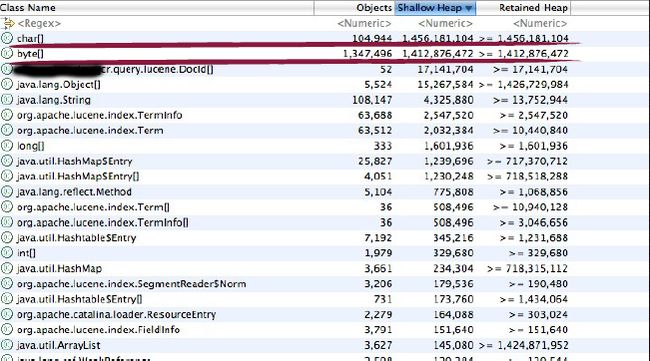
内存基本被byte和char霸占了.寻找这些byte和char的root.得到
![]()
![]()
嘿,好家伙,360M的对象,还不在少数(还有其他的图,包含了其他的大对象,就不列出了,主角就是上面的char[]), 而且这些对象是由Lucene创建的,经查,lucene会将索引中的field装载入内存,看似也是合理的,但是不合理的地方是它出现在了 RAMInputStream这个类中,因为按照jackrabbit的逻辑(ahuaxuan曾经写过17篇文章来阐述jackrabbit中的搜索模 块,详情查看: http://ahuaxuan.iteye.com/category/65829 ).这里ahuaxuan稍微阐述一下jackrabbit的搜索模块中是怎么使用RAMDirectory的:
新 的索引请求到达索引模块,建索引完成之后,jackrabbit不会立即将索引数据刷入磁盘, 而是放在内存中,然后当内存中的数据满足一定量之后(可以在配置文件中设置),这批数据会被一起刷到磁盘中,也就是从RAMDirectory中刷到 FSDirectory中,而刚才讲到满足一定的量,其实默认值是100, 也就是说RAMDirectory中最多保持了100个Document.
问题就在这里,100个Document能有360M的field?
这个可能性微乎其微. 如果不是这360M的量有问题,那么就是这100个Document的数量有问题,也许根本就超过了100个.
回过头来我们再来看看上面的逻辑:
1.为每个建立索引数据,存放在内存中
2.如果内存中document满100,刷入磁盘
3.删除内存中的document.
试想,在这个流程中,如果第二步出错.会导致什么情况? 内存中的索引数据不能输入到磁盘上,然后内存中的数据也不能删除(因为代码执行不到下面),所以内存中的数据越来越多 ,也就是RAMDirectory的数据越来越多.在索引数据不停的增加的过程中,char[]也在越来越大,由 于char[]是不能扩容的,所以每次扩容必须新建更大的char[],然后把老的char[]中的数据copy过去,那么问题就是,要建一个比360M 的char[]还大的char[]谈何容易? 因为我们的eden只有100M, old只有288M了, 于是OOM应运而生.
charpter 3 验证
查看服务器索引目录,发现确实索引目录的空间的使用率已经到达100%, 于是接着想查看日志文件,想找出IOException之类的异常,可惜的是QA已经将前一天的日志删除,现在的日志所有都是OOM的错误.真是死无对证,这个是比较遗憾的地方.
于是重启服务器,但是并不清空索引目录,不一会,程序又开始出错,打开dump,发现又是类似的问题,RAMDirectory的量还在增加,但是还没有到OOM的阶段(查看RAMDirectory中document的量,已经达到8000多个).
再次验证大对象的问题,写代码创建30m的对象,得到的内存图如下:

当 eden不够的时候(共80M,但是已经使用了57M,而我们的新对象是30M),对象没有经过so(from)和s1(to)而直接进入了Old.如果 old已经是286M,那么Old也放不下这个对象了,JVM直接抛出了OOM(该例子的系统平台是Mac os 10.5)
charpter 4 处理
将索引目录清空,重启服务器,重新查看dump文件,一切正常,于是跟QA约定保留5天之内的日志数据.从这个一点可以初步确定,OOM产生的原因就是因为磁盘空间不足,导致:
2.如果内存中document满100,刷入磁盘
3.删除内存中的document.
这个流程不能完成,结果就是内存中的数据悦来越多. 最终在为char[n]申请char[m](m >> n)的时候的产生了OOM
charpter 5 延伸
1. 为何from space 和to space都达到了450M, 因为它的理论值应该是8:1:1,也就是如果young区有1G, 那么eden应该是800M, from和to都是100M. 也就是说jvm会动态的调整from 和to的值,这个应该也和大对象相关,比如说我们有300m大对象在young区,这个时候要执行copy算法,那么对象需要进入from或者to区,但 是from 或者to的容量并不足以容纳这个对象,那么jvm可能会就会调整from和to的大小.以执行拷贝算法.
2.我们可以让生命周期较长的大对象直接进入old而无须进入young么.因为这些对象在young区会经过多次拷贝,然后才能进入Old,有时候并无必要.我们可以通过以下参数来设定:
XX:PretenureSizeThreshold=
be set to limit the size of allocations in the young generation. Any allocation larger than this will
not be attempted in the young generation and so will be allocated out of the old generation.
• Objects are now directly created in the older generation if the size of the young generation is
small, and the size of objects are big. The option -XX:PretenureSizeThreshold=
concurrent collector that can be enabled to indicate the threshold for direct creation in the
older generation. This could effectively be used for creation of caches, lookup tables, etc. which
are long lived and do not have to go through a promotion cycle of being created in the younger
generation and then being copied to the older generation. Use this option with care, since it can
degrade performance instead of improving it. The default value is 0 i.e., no objects are created
directly in the older generation.
• If an allocation fails in the young generation and the object is a large array that does not
contain any references to objects, it can be allocated directly into the old generation. In some
select instances, this strategy was intended to avoid a collection of the young generation by
allocating from the old generation.
如果不设置这个参数,那么不管多大的对象都会在在young 区申请空间,如果设置了这个参数,那么超过规定的大小,这个对象就会直接在old区生成. 但是需要注意的是,如果你的大对象生命周期很短,那么让他们进入old区的必要性也不是很大.
3.关于大的char数组扩容,ahuaxuan这里还有一个例子,是关于char数组的,详情请见
二、
/*
*author: ahuaxuan
*date: 2010-05-14
*/
介绍:
在前面的一篇文章中http://ahuaxuan.iteye.com/blog/662629 , ahuaxuan遇到了一个在内存相对充裕的情况下发生OOM的场景,具体的文章见:
然后时隔不久,该问题再次出现,但是出现在不同的场景下,现象有非常雷同之处.但是这次更离谱:
在某个他人的项目中, eden区还有300m空间的时候发生了OOM.
而 在前面一篇文章中,ahuaxuan揭示了在jackrabbit原有的搜索模块中出现的问题,其中主要的问题是大的char[]对象需要扩容的时候,虽 然在这个项目中和lucene没有任何关系,但是问题表现出来的现象非常相似,不出意外的话,应该也是大的char[]或者byte[]达到极限所带来的 问题. 思考一下,我们常见的char[]的应用有哪些, 无非就是StringBuilder,StringBuffer.
从 他的日志来看,问题主要出现在StringBuilder的expandCapacity方法上,看到log里的expandCapacity, ahuaxuan马上知道问题所在了.(问题很简单,一说大家就都明白了,但是为了显示出我们的学问,我们也要适时的更加深入一点,不能这么草草了事,是 吧,开个玩笑),我们知道StringBuilder内部其实是维护了一个
-
- * The value is used for character storage.
- */
- char value[];
/**
* The value is used for character storage.
*/
char value[];
而数组是无法扩容的,所以当数组空间不够的时候,将会创建一个更大的数组,然后把原来数组的数据全部都拷贝到新的数组中:
-
- int newCapacity = (value.length + 1 ) * 2 ;
- if (newCapacity < 0 ) {
- newCapacity = Integer.MAX_VALUE;
- } else if (minimumCapacity > newCapacity) {
- newCapacity = minimumCapacity;
- }
- value = Arrays.copyOf(value, newCapacity);
- }
void expandCapacity(int minimumCapacity) {
int newCapacity = (value.length + 1) * 2;
if (newCapacity < 0) {
newCapacity = Integer.MAX_VALUE;
} else if (minimumCapacity > newCapacity) {
newCapacity = minimumCapacity;
}
value = Arrays.copyOf(value, newCapacity);
}
接着再把新的数据追加到到新的char数组的后面.
-
- int newCount = count + str.length;
- if (newCount > value.length)
- expandCapacity(newCount);
- System.arraycopy(str, 0 , value, count, str.length);
- count = newCount;
- return this ;
- }
public AbstractStringBuilder append(char str[]) {
int newCount = count + str.length;
if (newCount > value.length)
expandCapacity(newCount);
System.arraycopy(str, 0, value, count, str.length);
count = newCount;
return this;
}
原理很简单,这里也许你要问,这样是不是性能的消耗很大??
其实这里有两个考虑:
1.如果算单次扩容,那么确实这里的代价会比较大.
2.如果算在整个StringBuilder的生命周期中,那么这个扩容操作只占整个生命周期的一小部分.
它的理论基础就是均摊理论,也就是说如过把这次扩容操作所消耗的代价平均分配到每次对这个StringBuilder的操作上,那么这个平均下来的代价的增长是微小的.
如果听到ahuaxuan上面山寨的解释不足以让你理解的话, 那这里再引用一下书上的原话来解释一下均摊的问题:
当然,同样的问题也会出现在StringBuffer, ArrayList等等我们常见的类中.
下 面我们来详细考量一下该理论在StringBuilder类的空间复杂度和时间复杂度. 假设我们有100个char需要放到一个stringbuilder中,根据它的实现,一共会有3次”扩容”, 并且有100次append操作, 假设一次”扩容”(建更大的数组,然后执行拷贝) , 假设扩容的时间消耗是m, append操作的时间消耗是n, 那么我们在这次StringBuilder的使用过程中,总的时间消耗是cost= (3*m + 100 * n) / 100. 而且m >> n. 所以我们在使用StringBuilder的过程中,要思考的是如何降低cost的值.当然降低3 * m是最好的, 但是对于m我们无能为力, 那么就对’3’下手把, 如果我们已知我们char的总数,我们就可以把这个3降下来,只要通过StringBuilder sb = new StringBuilder(100),这样就可以避免了3次扩容, 这样cost = (100 * n) / 100 = n.
这 时间问题是我们避免3次扩容的最佳理由么, 不是! 为什么,因为看上去 (3*m + 100 * n) / 100 并不比 n高到哪里去,所以在ahuaxuan的case中,性能并不是这样的差. 既然时间复杂度还不是最佳理由, 我们的目光自然而然的转到空间复杂度上.
其实刚才书上的均摊定义对于StringBuilder之类的实现来说只解释了时间复杂度的问题,但是并没有涉及到空间复杂度. 由于我们并不能直接操作内存的分配,所以在jvm中问题要显得更加神秘一点(一般的java程序远对于计算机科学的理解还是非常有待提高的).
继 续上面一个case, 第一次扩容时, char[16]不够,重新新建了一个 char[(16+1)*2], 第二次扩容char[(34 + 1) * 2], 第三次扩容char[(70 + 1)*2].这个时候一共产生了4个数组对象, char[16], char[34], char[70], char[142].其实我们只是append了100个char而已,我们消耗的空间最大却有可能达到262个char.
262个char还不至于消耗多少空间,因为我们只做了100次append, 如果我们有1000k的char呢.
我们来算一下时间的消耗和空间消耗.总的扩容次数为16(1000k个char的情况下)
时间消耗 : (16 * m + 1000k * n )/1000k
空间消耗 : 34 + 70 + ..... + 294910 + 589822 + 1179646 = 2359244
再 整个操作的生命周期内总共会消耗2359244个char的空间,但是由于我们的gc作用,所以同一时刻,我们最大的消耗至少为 589822+ 1179646 = 1769468. 空间消耗几乎至少翻倍(为啥是至少? 因为前面创建的char[]如果还没有被回收,那么消耗的空间就会更大,最大的会达到 2359244个char.如果是多线程在做这样的事情,那么消耗的空间数还要乘以线程数,比如说原来一条线程这样的操作只浪费了一个2M, 但是100条线程其实就浪费了200M这样的空间)
再深入考虑 , 难道我们这样做只是增加了空间的消耗吗? 绝不是. 我们还可以从JVM的角度再来考虑一下这个问题. 前面15个char[]的创建,对于jvm的young区的拷贝算法来说也是个不必要的负担,因为如果我们有100个线程在做这个任务,同一时间可能产生 15 * 100 = 1500个多余的对象.在gc的时候,这些对象需要mark, copy(前面临时的charp[]至少要copy一次,也就是说它们必须进入一次from or to space),其实在一些场景下,这种操作完全避免,避免的手段就是给StringBuilder一个合理的值.
如果你恰好看过我的第一篇”内存充裕下的OOM”,那么也不难理解在某些情况下(比如说200M以上的文本, 想象一下最后的一次扩容需要多少的申请多少的容量??)StringBuilder也会出现”内存充裕下的OOM”了.
相信看了ahuaxuan的这篇文章之后,在使用StringBuilder的时候你会更胸有成竹了. 同样,在使用ArrayList, StringBuffer, 还有HashMap(不但要数组翻倍,还要resize)之类的实现时也有同样的问题.
总结, 本文ahuaxuan主要解释了以下问题.
在StringBuilder之类的实现在扩容的时候, 带来的
1. 时间消耗.
2. 空间消耗.
3. 对jvm的影响.
通过这几个方面的剖析可以让我们更好的使用java SDK中类似的实现类.写出性能更高,更健壮的代码.
当然古人说授之以鱼不如授之以鱼, 事实上凡是以数组作为数据结构实现的类中,基本上都存在均摊的问题,同时也都存在对JVM有不必要影响的因素,所以需要大家更多的深入理解我们常用的类.