
什么是 Apache Hadoop ?
Apache Hadoop软件库是一个框架,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集。它旨在从单个服务器扩展到数千台机器,每台机器提供本地计算和存储。该库本身不是依靠硬件来提供高可用性,而是设计用于在应用层检测和处理故障,从而在一组计算机之上提供高可用性服务,每个计算机都可能出现故障。
Hadoop 项目包括以下几个模块:
Hadoop Common:支持其他Hadoop模块的常用工具。
Hadoop分布式文件系统(HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
Hadoop YARN:作业调度和集群资源管理的框架。
Hadoop MapReduce:一种用于并行处理大型数据集的基于YARN的系统。
搭建前期工作
Redhat Linux :链接:https://pan.baidu.com/s/1TdDLWHwRSazXjsa5QiS_PA 密码:tarv
VMware 12 :链接:https://pan.baidu.com/s/17_7bsbVkZjRT3vrrhYQJiA 密码:3wdm (压缩包内附带序列号破解)
JDK Linux:可参考Oracle官网
SecureCRT(该软件用于在Windows下操作Linux):链接:https://pan.baidu.com/s/1JEHWaVnTovqpmkDPQO3pnw 密码:qd4o
搭建进行时
虚拟机安装完毕后打开SecureCRT , 在Redhat中通过ifconfig 命令获取虚拟机IP地址。
输入虚拟机的ip地址与用户名后,通过系统提示输入虚拟机的用户密码,待连接成功后,即可通过本软件对Linux虚拟机进行操作。
通过SecureCRT的Sftp功能将下载好的Hadoop文件与JDK文件上传至Linux中。
1. 创建目录
使用 root 用户在 / 目录下创建soft 文件, mkdir soft
2. tar 开文件jdk压缩文件与Hadoop压缩文件
找到上传的jdk文件与Hadoop文件,并将其tar开。
tar -xzvf jdk-xxx
tar -xzvf hadoop-xxxx
将tar开的文件移至 /soft 目录下
mv jdk /soft
mv hadoop /soft
3.配置环境变量
1. 配置Java环境变量
在root用户下,nano /etc/profile

4. 检测JDK 与是否安装成功
敲击命令行 java -version

注(Hadoop 3.0 必须安装jdk1.8 否则Hadoop无法安装)
敲击命令行 hadoop version

5. 更改Hadoop配置文件
在Hadoop配置文件中引入java环境变量,进入/soft/hadoop/etc/hadoop/ 目录下 找到hadoop-env.sh 文件 通过配置文件引入java环境变量。如图所示:

编辑core-site.xml 文件 如图

编辑 hdfs-site.xml 文件,如图:

编辑yarn-site.xml 文件,如图:

编写works 文件,Hadoop 3.0 works文件与2.x中的slave文件一致 其中存储从机的名称。

6. 克隆从机与配置IP
通过 VMware 中 虚拟机 --> 管理中克隆 克隆完整虚拟机(注 : 每个虚拟机应当存放在对应的文件夹下,不应两个虚拟机共存于一个文件夹,否则会产生冲突)克隆三台虚拟机作为完全分布式的从机
更改IP :
在主机上通过ifconfig 命令行获取ip地址。将三台从机的ip改为与主机IP区段。
更改IP方式: 使用root用户进入 /etc/sysconfig/newwork-scripts/ 文件下, 找到ifcfg-ehxx文件更改其内容如:

更改hosts 文件,hosts 文件在/etc/ 目录下,

通过ping 命令查看虚拟机是否互通,如若不互通则代表IP为配置成功,

7. 初始化Hadoop 集群
通过hadoop namenode -format 命令初始化其集群配置

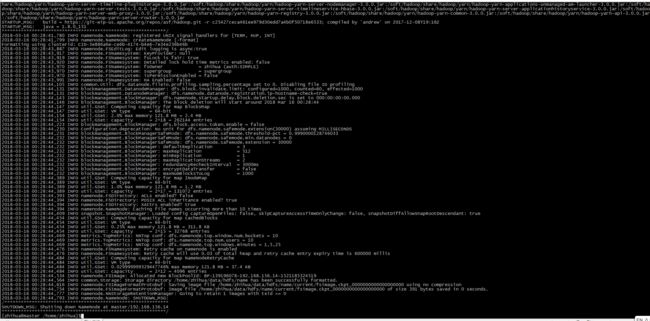
若未出现报错则代表Hadoop 集群初始化成功,若出现报错则通过/soft/hadoop/logs/ 日志文件查找错误并解决,
8. 启动Hadoop 集群
通过start-all.sh 命令启动Hadoop集群

通过jps 查看Hadoop集群进程
master机器有: namenode 、 ResourceManager 、 SecondaryNamenode
slave1 、slave2 、slave3 机器有: datanode 、 nodemanager
则集群开启成功。