用户画像第一章(企业级360°全方位用户画像_项目集群环境搭建)
项目环境搭建
搭建好的集群:链接:
虚拟机说明:
用户名:root
密码:123456
主机名:bd001
Ip:192.168.10.20
Mysql链接: 用户:root 密码:123456
虚拟机配置10网段(根据实际情况启动虚拟网卡)
集群安装路径:/export/servers
apache-flume-1.6.0-cdh5.14.0-bin
flume
hadoop
hadoop-2.6.0-cdh5.14.0
hbase
hbase-1.2.0-cdh5.14.0
hive
hive-1.1.0-cdh5.14.0
jdk1.8.0_221
oozie
oozie-4.1.0-cdh5.14.0
scala-2.11.12
solr
solr-4.10.3-cdh5.14.0
spark
spark-2.2.0-bin-2.6.0-cdh5.14.0
sqoop
sqoop-1.4.6-cdh5.14.0
zookeeper
zookeeper-3.4.5-cdh5.14.0
软件启动:bash /root/bd.sh start/stop (启动/关闭)
2144 ResourceManager
1985 SecondaryNameNode
2933 HRegionServer
2806 HMaster
1591 QuorumPeerMain
3015 Bootstrap
3240 Jps
3049 Bootstrap
1802 DataNode
2299 JobHistoryServer
1708 NameNode
2239 NodeManager
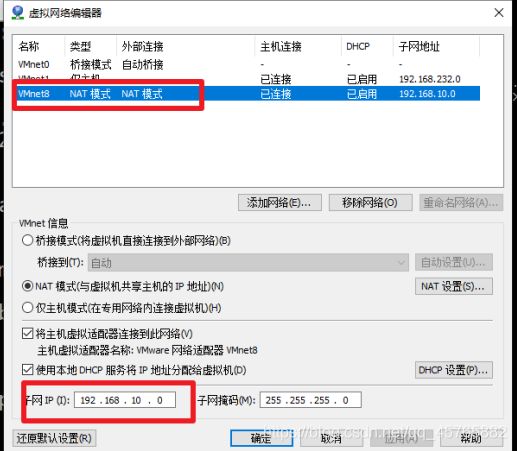
依据项目需求,使用大数据相关技术框架,安装目录及软件版本具体如下图所示:
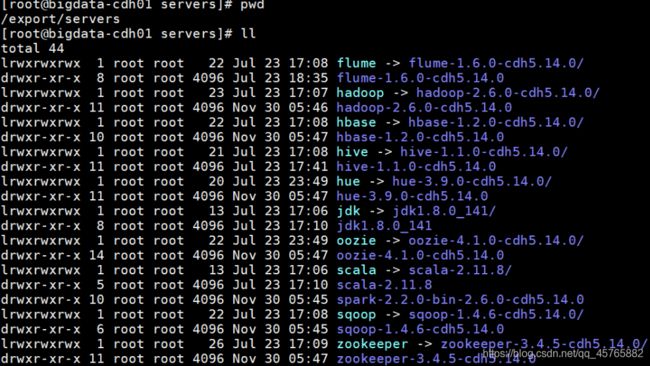
所有软件的安装以后,创建软连接,方便日后软件的升级。
ln [OPTION]… [-T] TARGET LINK_NAME
比如
ln -s /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 spark
在实际大数据项目中,大数据管理WEB界面,方便安装部署和监控大数据框架组件:
1)、ClouderaManager
CM
安装软件目录:/opt/parcells/…///…
2)、Ambari
开源
/etc/
/usr/lib/impala/
4.1、大数据平台基础环境
安装开发语言软件JDK1.8和Scala2.11及MySQL数据库。
1)、JDK 1.8
所有的大数据框架(90%)基于Java语言编写的
2)、Scala 2.11
Spark框架和Kafka框架使用Scala语言编写的
3)、MySQL
- Hive 表元数据MetaStore
- Oozie和Hue元数据
- 系统:WEB Platform
业务数据存储:tags
1)、安装JDK1.8,配置环境变量
JAVA HOME
export JAVA_HOME=/export/servers/jdk
export PATH= P A T H : PATH: PATH:{JAVA_HOME}/bin
2)、安装Scala 2.11,配置环境变量
SCALA HOME
export SCALA_HOME=/export/servers/scala
export PATH= P A T H : PATH: PATH:{SCALA_HOME}/bin
3)、安装MySQL数据库
按照MySQL数据库功能:
1)、Hive MetaStore存储
存储元数据
2)、标签系统WEB 平台数据存储
tbl_basic_tag
tbl_model
3)、Oozie 数据存储
Oozie调度Spark2应用程序
4)、Hue 数据存储
方便操作大数据平台组件
5)、业务数据: tags_dat
订单数据、订单商品表数据、会员信息数据、行为日志数据
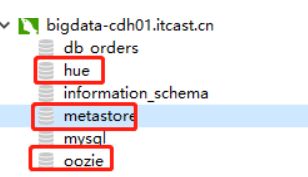
截图如下所示:
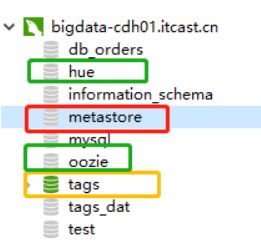
在实际项目,MySQL数据库字符编码最好是UTF-8,避免乱码出现。
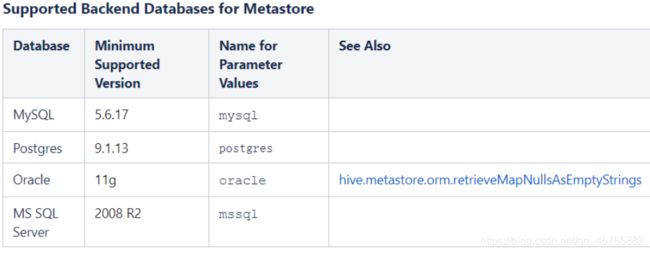
此处使用数据库版本:5.1.73,此版本较低,实际项目使用高版本(至少为**5.6.17**)版本以上。
[root@bigdata-cdh01 ~]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.1.73 Source distribution
Copyright © 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type ‘help;’ or ‘\h’ for help. Type ‘\c’ to clear the current input statement.
mysql> show databases ;
±-------------------+
| Database |
±-------------------+
| information_schema |
| db_orders |
| hue |
| metastore |
| mysql |
| oozie |
| tags |
| tags_dat |
| test |
±-------------------+
9 rows in set (0.31 sec)
设置字符集编码为utf-8,具体设置参考文档。
4.2、分布式协作服务Zookeeper
在大数据框架中为了高可用性,很多框架依赖于Zookeeper,所以先安装Zookeeper框架,单机版安装。
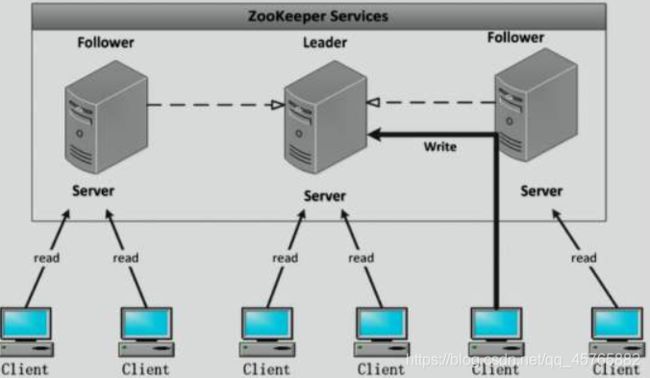
配置文件:$ZOOKEEPER_HOME/zoo.cfg
#The number of milliseconds of each tick
tickTime=2000
#The number of ticks that the initial
#synchronization phase can take
initLimit=10
#The number of ticks that can pass between
#sending a request and getting an acknowledgement
syncLimit=5
#the directory where the snapshot is stored.
#do not use /tmp for storage, /tmp here is just
#example sakes.
dataDir=/export/servers/zookeeper/datas/data
dataLogDir=/export/servers/zookeeper/datas/log
#the port at which the clients will connect
clientPort=2181
#the maximum number of client connections.
#increase this if you need to handle more clients
#maxClientCnxns=60
##server.1=bigdata-cdh01.itcast.cn:2888:3888
##server.2=bigdata-cdh02.itcast.cn:2888:3888
##server.3=bigdata-cdh03.itcast.cn:2888:3888
#Be sure to read the maintenance section of the
#administrator guide before turning on autopurge.
##http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
#Purge task interval in hours
#Set to “0” to disable auto purge feature
#autopurge.purgeInterval=1
创建数据和日志目录:
mkdir -p /export/servers/zookeeper/datas/data
mkdir -p /export/servers/zookeeper/datas/log
针对Zookeeper集群监控工具:
1)、TaoKeeper
阿里巴巴开源ZK监控工具,目前基本没人使用
2)、zkui
https://github.com/DeemOpen/zkui
https://www.jianshu.com/p/dac4c0bd1d2e
4.3、大数据基础框架Hadoop
安装大数据Hadoop框架,包含三个组件:HDFS(分布式文件系统)、YARN(集群资源管理和任务调度平台)及MapReduce(海量数据处理框架)。
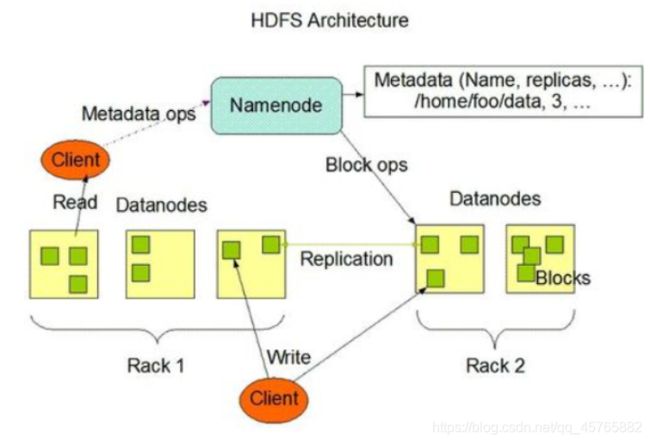
4.3.1、分布式文件系统HDFS
包含服务组件:NameNode和DataNodes,实际项目中按照HDFS HA(基于JN)。
环境变量配置:$HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/export/servers/jdk
common模块配置文件:$HADOOP_HOME/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-cdh01.itcast.cn:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop/datas</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
</configuration>
hdfs模块配置文件:$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置文件:$HADOOP_HOME/etc/hadoop/slaves
bigdata-cdh01.itcast.cn
4.3.2、分布式资源管理框架YARN
对集群资源分布式管理和调度,包含ResourceManager和NodeManagers。
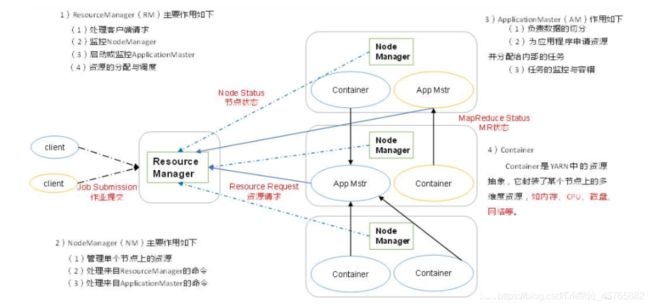
面试题:
目前来说,大数据框架Spark 主要还是运行在YANR上,所以必须掌握如下两个问题:
1)、YARN 如何资源管理和应用调度
2)、Spark on YARN:两个DeployMode提交流程与区别
必问,死背
配置文件**$HADOOP_HOME/etc/hadoop/yarn-env.sh**:
#some Java parameters
export JAVA_HOME=/export/servers/jdk
配置文件**$HADOOP_HOME/etc/hadoop/yarn-site.xml**:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-cdh01.itcast.cn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata-cdh01.itcast.cn:19888/jobhistory/logs</value>
</property>
</configuration>
4.3.3、计算处理框架MapReduce
对海量数据进行离线分析处理框架MapReduce,其中Sqoop和Oozie底层运行都是MapReduce任务,仅仅执行MapTask。
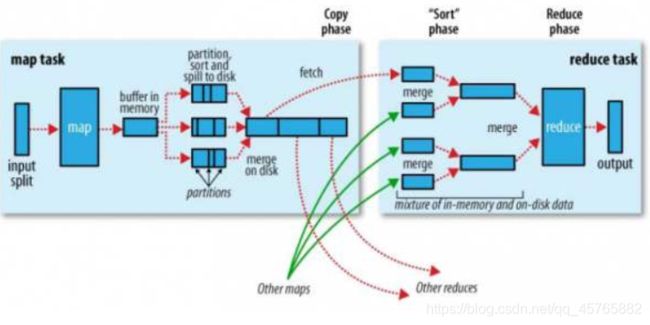
配置文件**$HADOOP_HOME/etc/hadoop/mapred-env.sh**:
export JAVA_HOME=/export/servers/jdk
配置文件**$HADOOP_HOME/etc/hadoop/mapred-site.xml**:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata-cdh01.itcast.cn:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata-cdh01.itcast.cn:19888</value>
</property>
</configuration>
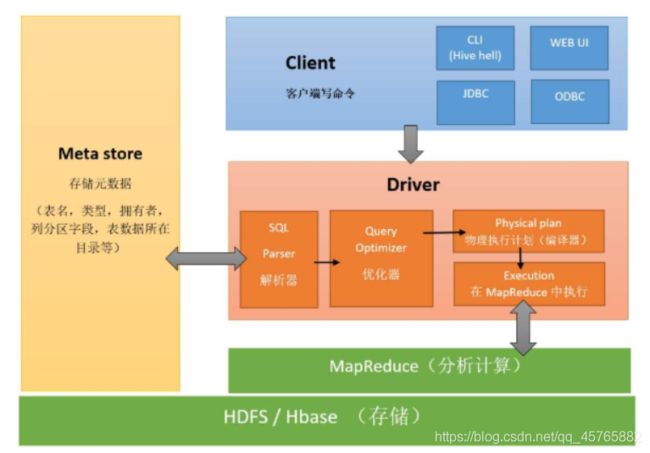
4.4、数据仓库框架Hive
基于HADOOP之上数据仓库框架Hive,在企业中使用非常广泛,底层MR计算分析数据。
针对Hive框架来说,底层计算引擎可以为三种:
1)、MapReduce(最原始)
2)、Tez
国外
3)、Spark
从Hive 2.0开始,官方建议使用Spark/Tez作为计算引擎,不推荐使用MR。
安装Hive数据仓库依赖的MySQL数据库,存储元数据MetaData,官方要求的MySQL数据库版本如下所示:
配置文件:$HIVE_HOME/conf/hive-env.sh
#Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/export/servers/hadoop
#Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/export/servers/hive/conf
配置文件:$HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata-cdh01.itcast.cn:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.mapred.mode</name>
<value>strict</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata-cdh01.itcast.cn:9083</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
注意:Hive MetaStore数据库字符编码必须使用latin,不能是utf-8,建议先创建Hive元数据数据库。
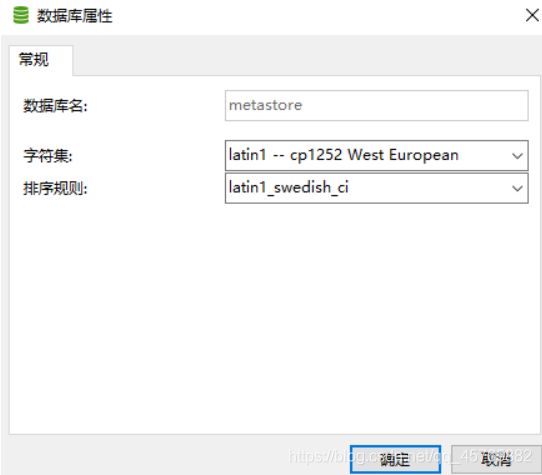
将MySQL数据库驱动包放入$HIVE_HOME/lib目录下。
1)、Hive MetaStore
可以在不同机器上启动多个,一台机器启动一个,默认口号时9083
2)、Hive 数据仓库目录
实际项目中不会使用默认值路径,需要配置
hive.metastore.warehouse.dir
/user/hive/warehouse
3)、启动HiveServer2
将Hive当做服务启动
4.5、大数据NoSQL数据库HBase
基于HDFS之上,存储海量数据NoSQL数据库HBase,面向列存储,可以存储几十亿行和百万列。
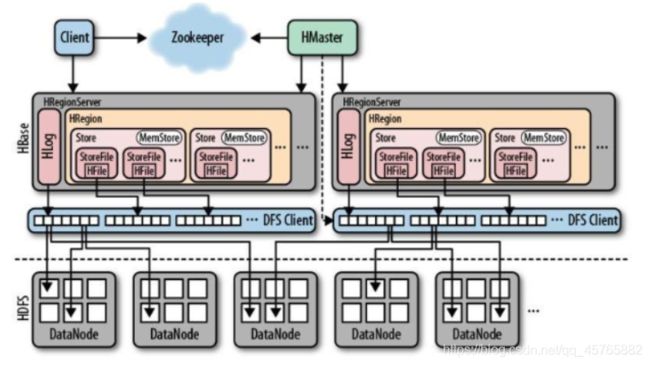
面试题:
1)、从HBase表中读写数据流程
首先连接ZK地址,找Meta表的Region所在的RegionServer地址信息
读流程:
MemStore 、StoreFile、BlockCache(读缓存)
写流程:
WAL(预写日志)、MemStore、StoreFile(Compaction:Minor、Major)
2)、HBase表的设计
就是RowKey设计:
唯一性、避免热点、前缀匹配查询
3)、HBase 性能优化
数据压缩、表预分区,JVM设置,RegionServer内存分配设置
HBase是否有单点故障:没有,可以启动多个HMaster
如果HBase集群中HMaster宕机了,短时间内是否影响Client读写表的数据:不影响
配置文件:$HBASE_HOME/conf/hbase-env.sh
#The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/export/servers/jdk
#Tell HBase whether it should manage it’s own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=false
配置文件:$HBASE_HOME/conf/hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定HBase框架运行临时目录 -->
<property >
<name>hbase.tmp.dir</name>
<value>/export/servers/hbase/data/tmp</value>
</property>
<!-- HBASE 表中数据存储在HDFS上根目录 -->
<property >
<name>hbase.rootdir</name>
<value>hdfs://bigdata-cdh01.itcast.cn:8020/hbase
</property>
<!-- HBase Cluster 集群运行在分布式模式下,伪分布式也是分布式 -->
<property >
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 告知HBase Cluster所依赖的ZK Cluster地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata-cdh01.itcast.cn</value>
</property>
<!-- 配置压缩SNAPPY和LZ4 -->
<!--
<property>
<name>hbase.master.check.compression</name>
<value>true</value>
</property>
<property>
<name>hbase.regionserver.codecs</name>
<value>lz4</value>
</property>
-->
</configuration>
配置文件:$HBASE_HOME/conf/regionservers
bigdata-cdh01.itcast.cn
4.6、大数据生态组件
生态组件中有SQOOP、FLUME、OOZIE和HUE,方便数据采集及任务调度查看。
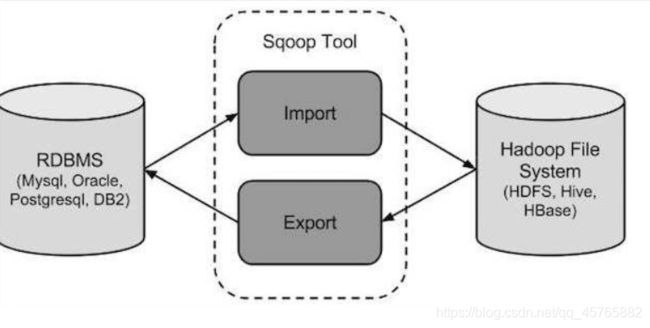
4.6.1、数据转换工具SQOOP
SQOOP底层为MapReduce程序,仅仅运行MapTask,并行的将数据在RDBMs与HDFS/HIVE/HBase之间导入导出。
4.6.2、数据实时抽取采集Flume
实时监控日志数据,将数据采集存储到HDFS上,架构图如下:
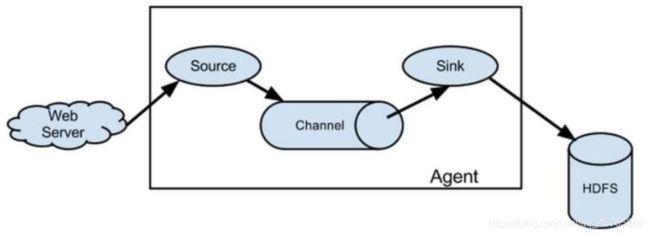
针对每个服务器产生的日志数据,启动一个Agent,实时监控数据,采集存储到HDFS上。
1)、Source
2)、Channel
3)、Sink
面试题:
Flume采集数据时,考虑架构:高可用和负载均衡
案例:
1)、Flume 高可用:
https://blog.csdn.net/jinYwuM/article/details/82594618
2)、Flume 负载均衡
https://blog.csdn.net/silentwolfyh/article/details/51165804
4.6.3、任务调度框架Oozie
使用Oozie调度执行任务(工作流WorkFlow和调度器Coordinator),架构如下:
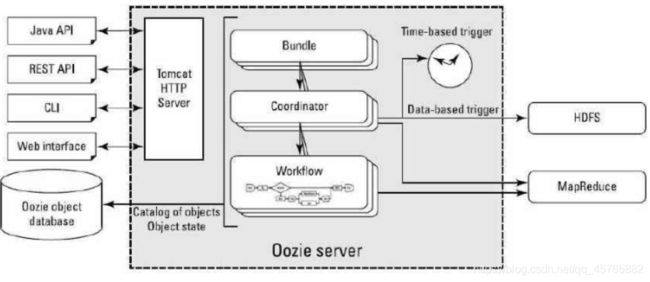
Oozie 任务调度框架:
1)、工作流WorkFlow - 简单任务调度
将每个任务封装在Workf1ow中调度执行
2)、调度器Coordinator
针对WorkFlow指定调度策略(时间,数据可用性)
3)、Bundle
批量调度执行,有点类似事务
Oozie中每个Workflow执行时都是一个MapReduce任务,仅仅只有一个MapTask,用于启动Action。
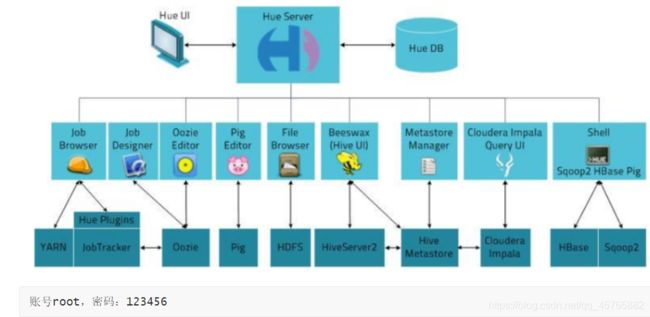
4.6.4、大数据可视化工具Hue
Hue为大数据生态系统一体可视化工具,操作HDFs、查看任务执行及集成Hive编写SQL,尤其与Oozie集成,更加方便的调度执行任务工作流。
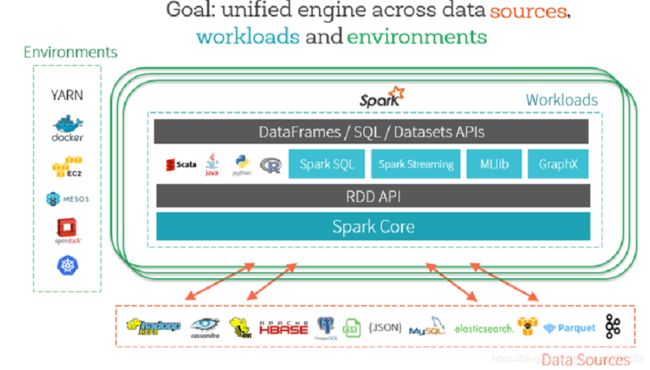
4.7、大数据分析框架Spark
大数据分析框架Spark,集成批处理、交互式分析和流式处理及高级数据分析(图计算和机器学习)为一体的框架,从Spark 2.0开始,所有应用入口为SparkSession,数据封装在DataFrame中。
配置文件:$SPARK_HOME/conf/spark-env.sh
JAVA_HOME=/export/servers/jdk
SCALA_HOME=/export/servers/scala
HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
YARN_CONF_DIR=/export/servers/hadoop/etc/hadoop
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://bigdata-cdh01.itcast.cn:8020/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
配置文件:$SPARK_HOME/conf/spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdata-cdh01.itcast.cn:8020/spark/eventLogs/
spark.eventLog.compress true
spark.yarn.jars hdfs://bigdata-cdh01.itcast.cn:8020/spark/jars/*
spark.yarn.historyServer.address bigdata-cdh01.itcast.cn:18080
spark.sql.warehouse.dir /user/hive/warehouse
运行Spark 圆周率PI程序,提交到YARN上执行:
#!/bin/bash
SPARK_HOME=/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode cluster
–class org.apache.spark.examples.SparkPi
–driver-memory 512m
–driver-cores 1
–executor-memory 512m
–executor-cores 1
–num-executors 2
–queue default
hdfs://bigdata-cdh01.itcast.cn:8020/spark/spark-examples_2.11-2.2.0.jar
10