Flink DataStream API - Connector(连接器)
Connector
- 连接器
- HDFS连接器
- Kafka
- 1.创建连接器
- 2.创建反序列化器
- 3.设置消息起始位置偏移
- 4.设置检查点周期
- 5.设置位置偏移提交方式
- 异步I/O
连接器
Source和Sink节点连接外部数据源的组件称为连接器(Connector),其中内置连接器的实现代码集成在Flink源码中,但是这些代码并没有被编译进Flink二进制程序包中。内置连接器如下,其中括号里描述的是支持Source还是Sink。
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Twitter Streaming API (source)
Flink的容错机制在出现故障时恢复程序并继续执行它们。这些故障包括机器硬件故障、网络故障、暂态程序故障等。
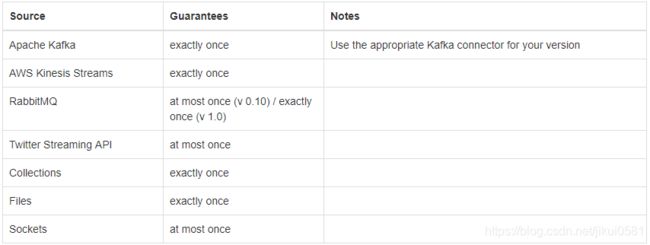
Flink可以精确地保证,只有连接器支持exactly-once语义时,一致性保障情况如下图所示:

HDFS连接器
HDFS连接器是以库的形式提供的,需在MAVEN工程中引入以下依赖:MAVEN仓库地址
org.apache.flink
flink-connector-filesystem_2.11
1.8.1
唯一需要设置的参数是存储文件的基本路径。并可以通过指定自定义bucketer、写入器和批大小来进一步配置接收器。
默认情况下,当元素到达时,BucketingSink将根据当前系统时间进行分割,并使用datetime模式(“yyyy-MM-dd–HH”)来命名桶。此模式使用当前系统时间和JVM的默认时区传递给DateTimeFormatter,以形成桶路径。用户还可以为桶指定一个时区来格式化桶路径。每当遇到新的日期,就会创建一个新的桶。例如,如果您有一个包含分钟作为最细粒度的模式,那么您将每分钟获得一个新桶。每个桶本身都是一个包含多个部件文件的目录(sink的每个并行实例将创建自己的部件文件),当部件文件变得太大时,sink还将在其他文件旁边创建一个新的部件文件。当桶变为非活动时,打开的部分文件将被刷新并关闭。当一个桶最近没有被写入时,它被认为是不活动的。默认情况下,sink每分钟检查不活动的桶,并关闭超过一分钟没有写入的桶。可以在BucketingSink上使用setInactiveBucketCheckInterval()和setInactiveBucketThreshold()配置此行为。
还可以通过在BucketingSink上使用setBucketer()指定自定义桶。如果需要,桶可以使用元素或元组的属性来确定桶目录。
默认使用StringWriter写入。这将对传入的元素调用toString(),并将它们写入用换行符分隔的部分文件中。要指定自定义写入器,请在BucketingSink上使用setWriter()。如果您想编写Hadoop sequencefile文件,您可以使用提供的SequenceFileWriter,它也可以配置为使用压缩。
有两个配置选项指定何时关闭一个桶内文件,何时启动一个新的桶内文件:
- -通过设置指定大小(默认的部分文件大小为384 MB)
- 通过设置一个固定的时间间隔(默认的随时间间隔是Long.MAX_VALUE)
当满足这两个条件之一时,将启动一个新的桶内文件。
DataStream> input = ...;
// 定义存储桶的基本路径
BucketingSink> sink = new BucketingSink>("/base/path");
sink.setBucketer(new DateTimeBucketer<>("yyyy-MM-dd--HHmm", ZoneId.of("America/Los_Angeles")));
sink.setWriter(new SequenceFileWriter());
sink.setBatchSize(1024 * 1024 * 400); // this is 400 MB,
sink.setBatchRolloverInterval(20 * 60 * 1000); // this is 20 mins
input.addSink(sink);
Kafka
Flink提供特殊的Kafka Connector,用于从/向Kafka的主题中读取和写入数据。Flink Kafka Consumer集成了Flink的检查点机制,可提供一次性处理语义。为实现这一目标,Flink并不完全依赖Kafka的消费者群体偏移跟踪,而是在内部跟踪和检查这些偏移。
请为您的用例和环境选择一个合适版本的Kafka依赖包。对于大多数用户来说,FlinkKafkaConsumer08是合适的。
然后引入依赖包 MAVEN仓库地址:
org.apache.flink
flink-connector-kafka_2.11
1.8.0
1.创建连接器
创建kafka连接器需定义Consumer属性、Topic和反序列化器,代码如下:
Properties properties = new Properties();
// 设置Broker地址,多个地址以逗号分隔
properties.setProperty("bootstrap.servers", "localhost:9092");
// 设置zookeeper地址,多个地址以逗号分隔 Kafka 0.8独有
properties.setProperty("zookeeper.connect", "localhost:2181");
// 设置Consumer组
properties.setProperty("group.id", "test");
// 创建连接器,消费主题位“topic”,反序列化器为SimpleStringSchema,消息格式为String
DataStream stream = env
.addSource(new FlinkKafkaConsumer08<>("topic", new SimpleStringSchema(), properties));
2.创建反序列化器
消息是有结构的,Flink应用程序需定义反序列化器,将Kafka中的二进制数据转换成Java/Scala对象。自定义反序列化器继承抽象反序列化器AbstractDeserializationSchema,主要接口为deserialize,用于将字节流反序列化成对象。
或使用avro反序列化器,需引入以下依赖:
org.apache.flink
flink-avro
1.8.0
3.设置消息起始位置偏移
Flink Kafka允许使用者配置Kafka分区的起始位置。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer08 myConsumer = new FlinkKafkaConsumer08<>(...);
myConsumer.setStartFromEarliest(); // 从最早的记录开始
myConsumer.setStartFromLatest(); // 从最晚的记录开始
myConsumer.setStartFromTimestamp(...); // 从固定的时间点开始
myConsumer.setStartFromGroupOffsets(); // 从Comsumer组上一次提交的位置开始
DataStream stream = env.addSource(myConsumer);
..
设置每个分区的起始位置
Map specificStartOffsets = new HashMap<>();
// 主题为myTopic的第一个分区起始点为23L(时间戳,单位ms)
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L);
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 1), 31L);
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 2), 43L);
myConsumer.setStartFromSpecificOffsets(specificStartOffsets);
4.设置检查点周期
启用Flink的检查点后,Flink将使用来自Kafka主题的记录,并以一致的方式定期检查所有Kafka偏移量以及其他操作的状态。如果作业失败,Flink将把流程序恢复到最新检查点的状态,并从检查点中存储的偏移量开始重新使用Kafka的记录。
因此,绘制检查点的间隔定义了程序在发生故障时最多需要返回多少。
Flink周期性地向Source节点插入检查点屏障,如果配置检查点周期为5秒,代码如下:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000); // checkpoint every 5000 msecs
5.设置位置偏移提交方式
在Flink启用检查点机制时,Consumer在检查点完成后可以将偏移位置提交到Zookeeper,但应用程序可以关闭这种功能:
FlinkKafkaConsumer08 myConsumer = new FlinkKafkaConsumer08<>(...);
myConsumer.setCommitOffsetsOnCheckpoints(false)
在没有启用检查点机制时,可以启动自动提交功能:
Properties properties = new Properties();
properties.setProperty("enable.auto.commit", true);
properties.setProperty("anto.commit.interval.ms", "100");
异步I/O
在从外部Source拉取数据或写出外部存储时,访问效率和网络通信延迟是流式数据处理引擎所面临的主要架构问题之一。使用异步I/O意味着多个任务可以并发地访问外部存储,着往往比提高并行度更有效,因为异步I/O可获得硬件层的支持,如DMA。

通常,异步I/O会带来乱序问题,为此I/O客户端需要复杂的处理逻辑以保证请求结果返回的顺序。
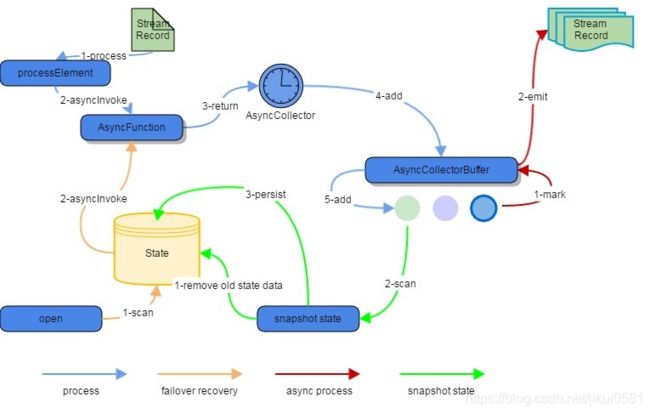
Flink异步I/O架构的核心组件为用于实现回调的请求收集器(AsyncCollector)和收集器缓存区(AsyncCollectorBuffer),应用程序通过RichFunction接口调用异步I/O。异步I/O架构:
使用异步I/O例子:
// This example implements the asynchronous request and callback with Futures that have the
// interface of Java 8's futures (which is the same one followed by Flink's Future)
/**
* An implementation of the 'AsyncFunction' that sends requests and sets the callback.
*/
class AsyncDatabaseRequest extends RichAsyncFunction> {
/** The database specific client that can issue concurrent requests with callbacks */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture> resultFuture) throws Exception {
// issue the asynchronous request, receive a future for result
final Future result = client.query(key);
// set the callback to be executed once the request by the client is complete
// the callback simply forwards the result to the result future
CompletableFuture.supplyAsync(new Supplier() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// create the original stream
DataStream stream = ...;
// apply the async I/O transformation
DataStream> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);