4.1 Hadoop-dijkstra(狄克斯特拉)算法-计算最短距离
dijkstra(狄克斯特拉)算法:
从一个顶点到其余各顶点的
最短路径
算法,解决的是有向图中最短路径问题。迪杰斯特拉算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止,常用在地图和社交
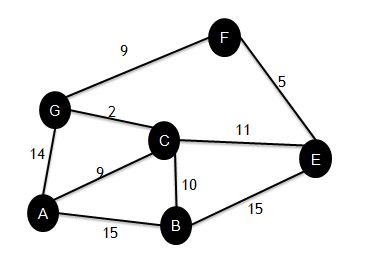
–步骤:
–A为起始点。首先标记它到自已的距离为0。到其他节点的距离为无穷大
–进入迭代:
•第一次迭代,从数据中取出起点A,找到A的邻接点B, C..,并更新到B, C的距离。
•第二次迭代,分别从扩张点B,C,G找到与他们相邻的点,这时发现A经C到G的距离比直接到G的距离要短,于是更新到G的距离为11,以此类推。
•一直所有点都有一个最短距离。而不是无穷大。结束迭代。

工程结构:
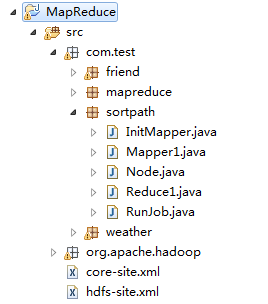
InitMapper:
|
package com.test.sortpath;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 初始化数据的Mapreducer
*
* @author root
*
*/
public class InitMapper extends Mapper
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
String fn = context.getConfiguration().get("my.firstNode");
String node = key.toString();
if (node.equals(fn)) {
context.write(new Text(node + "\t" + 0+"\t"), value);//第一次初始化标记它到自已的距离为0。到其他节点的距离为无穷大
} else {
context.write(new Text(node + "\t" + Integer.MAX_VALUE+"\t"), value);
}
}
}
|
Mapper1:
|
package com.test.sortpath;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import com.test.sortpath.RunJob.PathCounter;
/**
* 层层往外扩展的Mapreducer
*
* @author root
*
*/
public class Mapper1 extends Mapper
private Text outKey = new Text();
private Text outValue = new Text();
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
Node node = Node.fromMR(value.toString());//value :0 B:7 C:9 G:14
context.write(key, value);// 原始数据不做任何处理,输出 key:A value:0 B:7 C:9 在后面的reduce中会用到原始数据
// G:14
if (node.isDistanceSet()) {//开始往外扩展
context.getCounter(PathCounter.MyCOUNT).increment(1);// i++
// 获得任务的计数器。记录一共读到几个点。每读到一个点加1.
String backpointer = node.constructBackpointer(key.toString());//构造一个路径
for (int i = 0; i < node.getAdjacentNodeNames().length; i++) {//开始扩展
String neighbor = node.getAdjacentNodeNames()[i];
// our neighbors are just a hop away
//
int neighborDistance = node.getDistance()
+ Integer.parseInt(neighbor.split(":")[1]);
// output the neighbor with the propagated distance and
// backpointer
//
outKey.set(neighbor.split(":")[0]);//以节点的名字为key
Node adjacentNode = new Node()
.setDistance(neighborDistance).setBackpointer(
backpointer);
outValue.set(adjacentNode.toString());
System.out.println(" output -> K[" + outKey + "],V["
+ outValue + "]"); // key: B value:7 A
context.write(outKey, outValue);
}
}
}
}
|
Reduce1:
|
package com.test.sortpath;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Reduce1 extends Reducer
private Text outValue = new Text();
public void reduce(Text key, Iterable
throws IOException, InterruptedException {
int minDistance = Node.INFINITE;
Node shortestAdjacentNode = null;
Node originalNode = null;// 原始数据
for (Text textValue : values) {
System.out.println(" input -> V[" + textValue + "]");
Node node = Node.fromMR(textValue.toString());
if (node.containsAdjacentNodes()) {
// the original data
//
originalNode = node;
}
if (node.getDistance() < minDistance) {
minDistance = node.getDistance();// 如果发现相加之后的距离小于原来记录的距离。则最小距离被修改
shortestAdjacentNode = node;
}
}
if (shortestAdjacentNode != null) {
originalNode.setDistance(minDistance);
originalNode.setBackpointer(shortestAdjacentNode
.getBackpointer());
}
outValue.set(originalNode.toString());
context.write(key, outValue);
}
}
|
Node:
|
package com.test.sortpath;
import java.io.IOException;
import java.util.Arrays;
import org.apache.commons.lang.StringUtils;
/**
* 解析value的对象。value:0 B:7 C:9 G:14
* @author root
*
*/
public class Node {
public static int INFINITE = Integer.MAX_VALUE;
private int distance = INFINITE;
//上一个节点
private String backpointer;
//与该节点相邻的其他节点数组
private String[] adjacentNodeNames;
public static final char fieldSeparator = '\t';
public int getDistance() {
return distance;
}
public Node setDistance(int distance) {
this.distance = distance;
return this;
}
public String getBackpointer() {
return backpointer;
}
public Node setBackpointer(String backpointer) {
this.backpointer = backpointer;
return this;
}
/**
* A -> B
* @param name
* @return
*/
public String constructBackpointer(String name) {
StringBuilder backpointers = new StringBuilder();
if (StringUtils.trimToNull(getBackpointer()) != null) {
backpointers.append(getBackpointer()).append("->");
}
backpointers.append(name);
return backpointers.toString();
}
public String[] getAdjacentNodeNames() {
return adjacentNodeNames;
}
public Node setAdjacentNodeNames(String[] adjacentNodeNames) {
this.adjacentNodeNames = adjacentNodeNames;
return this;
}
public boolean containsAdjacentNodes() {
return adjacentNodeNames != null;
}
public boolean isDistanceSet() {
return distance != INFINITE;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(distance)
.append(fieldSeparator)
.append(backpointer);
if (getAdjacentNodeNames() != null) {
sb.append(fieldSeparator)
.append(StringUtils
.join(getAdjacentNodeNames(), fieldSeparator));
}
return sb.toString();
}
public static Node fromMR(String value) throws IOException {
String[] parts = StringUtils.splitPreserveAllTokens(
value, fieldSeparator);
if (parts.length < 2) {
throw new IOException(
"Expected 2 or more parts but received " + parts.length);
}
Node node = new Node()
.setDistance(Integer.valueOf(parts[0]))
.setBackpointer(StringUtils.trimToNull(parts[1]));
if (parts.length > 2) {
node.setAdjacentNodeNames(Arrays.copyOfRange(parts, 2,
parts.length));
}
return node;
}
}
|
RunJob:
|
package com.test.sortpath;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static String firstNode = "A";
public static enum PathCounter {
MyCOUNT// 计数器名字。定义一个计数器的名字
}
public static void main(String[] args) {
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://node1:9000");
config.set("my.firstNode", firstNode);
// config.set("mapred.jar",
// "C:\\Users\\Administrator\\Desktop\\wc.jar");
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("wc");
job.setJarByClass(RunJob.class);// job的入口类
job.setMapperClass(InitMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);// 没有reduce任务,也没有洗牌。
job.setInputFormatClass(KeyValueTextInputFormat.class);
// 定义job任务输入数据目录和输出结果目录
// 把wc.txt上传到hdfs目录中/usr/intput/wc.txt
// 输出结果数据放到/usr/output/wc
FileInputFormat.addInputPath(job, new Path("/usr/input/data.txt"));
// 输出结果数据目录不能存在,job执行时自动创建的。如果在执行时目录已经存在,则job执行失败。
Path output = new Path("/usr/output/init_shortpath");
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
boolean f = job.waitForCompletion(true);
if (f) {
System.out.println("job执行成功!");
int i = 0;// 迭代的次数
long nodecount = 0;// 节点统计数据
while (true) {
i++;
// 开始迭代
job = Job.getInstance(config);
job.setJobName("sp" + i);
job.setJarByClass(RunJob.class);// job的入口类
job.setMapperClass(Mapper1.class);
job.setReducerClass(Reduce1.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
if(i==1){
FileInputFormat.addInputPath(job, new Path(
"/usr/output/init_shortpath"));
}else{
FileInputFormat.addInputPath(job, new Path(
"/usr/output/shortpath"+(i-1)));
}
// 输出结果数据目录不能存在,job执行时自动创建的。如果在执行时目录已经存在,则job执行失败。
output = new Path("/usr/output/shortpath"+i);
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
f = job.waitForCompletion(true);
nodecount= job.getCounters().findCounter(PathCounter.MyCOUNT).getValue();//从计数器中拿到节点的总数
if (nodecount == 6) {
System.out.println("一共执行了"+i+"次Mapreducer");
break;
}
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
|