一.redis 中使用的字典
redis的字典是由hash表实现的,代码主要是在dict.cpp/dict.h中

ht是一个指向dictht指针数组,一般只使用ht[0],ht[1]在rehash 的时候使用,rehshidx作为是否在rehash的标志,table是一个dictEntry地址数组指针,hash算法采用的是murmur2算法(目前已出到murmur3),计算hash值并与sizemark进行取模操作得到table的index,解决冲突采用链地址法,由于dictEntry链表并没有尾指针,所以插入是头插方式,dict的结构大概是酱紫的如下图
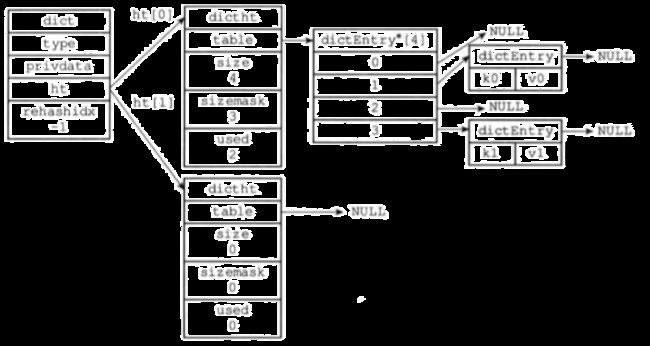
key的个数为used ,size为table长度
如果used> size and redis 没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令或者正在 执行 BGSAVE 命令或者 BGREWRITEAOF and 超过负载阈值 的情况下 允许rehash ,扩展后的table是大于原table2倍的最小2次幂,考虑是否在执行 BGSAVE 命令或者 BGREWRITEAOF 是因为作者不想在子进程执行保存操作使用写时复制时使用过多内存(for Redis, as we use copy-on-write and don't want to move too much memory around when there is a child performing saving operations.)
在负载阈值小于0.1的情况下会进行紧缩操作,紧缩后的table是大于used值的最小2次幂
在迁移的时候会生成一个新的table付给 ht[1],ht[0]被不断的迁到ht[1]中,新增操作也只在ht[1]中进行,查找会依次在两个表中进行,如果没有找到的话,不管是扩展还是紧缩操作都不会立即一次性完成,而是在redis 字典进程插入,获取等操作是进行一定数量或者一定时间片段的迁移(1毫秒),直到迁移成功,迁移完成,将ht[1]付给ht[0],ht[1]被置空
二.golang 中的map
golang 中的map是用hash表实现的,源码路径为runtime/hashmap.go
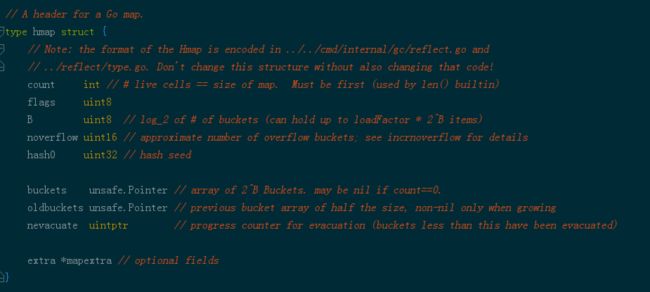
其中buckets 和 oldbuckets是map两个桶,一般只用buckets,在map过大,或者map负载过大会进行rehash,bucket大小为2^B次方大小,flag记录当前map状态
flag值为

map在hashWriting时再写会抛出错误,sameSizeGrow为假时rehash扩大原buckets的2倍,否则新的buckets和原buckets大小一致
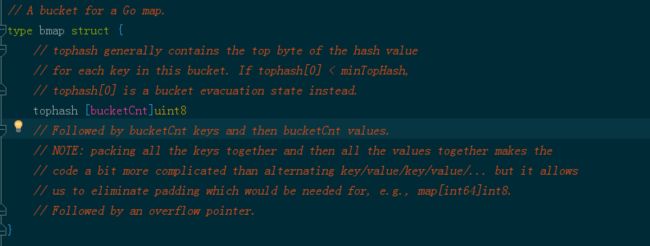
每个buckets默认存储8个key

但buckets不是直接存储key,每个key的hash值的低位表示所存储桶的索引,而高位存储在tophash数组中,每个bucket首先存储的就是一个tophash数组,用于遍历快速找到key,0到4不是有效的hash值,在tophash数组后面是key,key的后面是value,key value并不是按照我们常规的key/value/key/value/... 这样子存储而是按照key/key/..../value/value/...存储这样存储是为了节省padding空间假如 在map[int64]int8中,4个相邻的int8可以存储在同一个内存单元中。如果使用kv交错存储的话,每个int8都会被padding占用单独的内存单元(为了提高寻址速度),再后面是一个overflow指针,在默认的8个key存满之后,多出key value对会组成新的bucket挂在之前的bucket后面,由overflow指针指向,再多是同样处理,所以golang的map用的是主要还是链地址法解决冲突
如果超出扩展阈值或者太多overflow链表,map就会进行扩展,原来的bucket会变成oldbucket,新的bucket 是原bucket 的两倍,如果只是太多overflow链表而不是超过了扩展阈值则新的bucket和之前的大小一样,相当于做了个紧缩操作,函数为hashGrow()会创建新的bucket,旧的bucket会地址会赋值给oldbuckets指针,散列操作在growWork()函数 ,扩展不是一次性完成的而是在插入,删除时一次迁移一个或者两个(本次操作的bucket和上次还没有再扩展的bucket)
tophash值再0到4之间有特殊意义

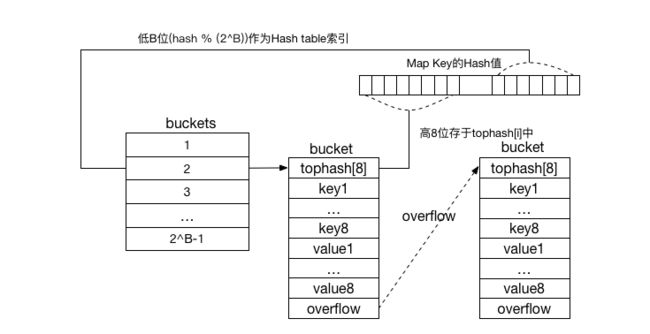
显然存储整个hash值会浪费很多空间,而且作者似乎不想每次都比较key值,bucket中只存储了hash值得高8位
总结:
相似的地方 :
1.都使用2个hashtable,其中一个一般不使用,在扩展和收缩的时候会从一个迁移到另一个
2.都是渐进的rehash,不是一次性的完成rehash操作,出于对性能的考虑,都选择了每次执行查插删改的时候顺带进行一定量的rehash的操作,这样既不会一次占用太多执行时间,也会最终把迁移完成
3.都用链地址法解决冲突,虽然实现细节上稍有不同(云风大神说lua是闭散列的我没有研究)
4.两个hashtable的长度都是2的n次幂,更容易进行取模操作,扩展操作也是2倍操作
不同的地方:
1.golang实现更复杂一些,虽然都是用链表解决冲突,但是golang更讲究对内存的管理,尽量用一段连续的内存,而redis就直接用链表了,redis用了更多内存存储链表的指针,golang虽然也存储了的指针,但只是overflow指针,但是有把hash值得高位存起来
2.因为golang的存储结构,取值基本是地址加偏移量的操作,而redis都是取地址再查找,命中率没有那么高,但是golan管理更加复杂
3.golang hash值得低位是桶索引,高位是用来快速查找key且被存储,而redis的hash值只用来定位桶,查找key是直接比较,并没有存储hash值
4.redis的hash算法是murmur2算法,golang map使用的算法是受 xxhash和cityhash启发的新算法,源码在runtime/hash32.go,runtime/hash64.go中
遗漏:
没有深看golang的map的紧缩算法,只看到在overflow链表过多而整个map没有过负载的情况下会rehash,但是新的buckets数量和原buckets大小一致
参考:
http://wudaijun.com/2016/09/go-notes-1-datastructures/
https://blog.yiz96.com/golang-map/
https://blog.codingnow.com/2013/08/reading_golang_source.html
以上,如有错误欢迎指出