更快更稳定:这就是Wasserstein GAN
Courant 数学科学研究所与 Facebook 人工智能研究所提出的 Wasserstein GAN 在标准 GAN 的基础上实现了显著的改进。机器之心技术分析师对该研究进行了解读。

论文地址:https://arxiv.org/abs/1701.07875
项目地址:https://github.com/martinarjovsky/WassersteinGAN
论文讨论:https://www.reddit.com/r/MachineLearning/comments/5qxoaz/r_170107875_wasserstein_gan/
引言
这篇论文介绍了一种名叫 Wasserstein GAN(WGAN)的全新算法,这是一种可替代标准生成对抗网络(GAN)的训练方法。这项研究没有应用传统 GAN 所用的那种 minimax 形式,而是基于一种名为“Wasserstein 距离”的新型距离指标做了某些修改。

这是基于 MLP 生成器的 WGAN(左上图)和 GAN(右上图)生成的样本,很显然,这里 WGAN 的图像质量优于标准 GAN。
简单来说,WGAN 有两个改变。第一个是取出了判别器中的 sigmoid,这是用于计算输出均值之间的差异的。第二个改变是判别器(这篇论文称之为 Critic),这就只是一个函数,其目标是让假数据有较低的预期值,让真实数据有较高的预期值。注意这些输出不再是对数概率,这样这些损失现在就与二元交叉熵无关了。
Wasserstein GAN
近期一些 GAN 论文提出了一些不同的生成对抗训练架构。但是,这些架构的一个共同点是 f-距离(包括 KL-距离、总变差散度(total variation divergence))。f-距离是真实数据分布和生成数据分布之间的密度比 P_r(x)/P_θ(x) 的函数,非常类似于 Jenson-Shannon(JS)距离。
上式是标准 GAN 的目标。在 GAN 的训练过程中,判别器的目标是最大化上述目标(最大值为 0,最小值为负无穷)。GAN 的估计可对应于 JS 距离度量。我们再看看 f-距离。如果两个分布没有显著的重叠,我们又能做什么?如果不能,那么其概率密度比将为零或无穷,而且其对整体概率估计(比如由 (0, z) 点组成的真实数据,其中 z ~ U (0,1))会有巨大的负面影响,于是样本就会从 y=0 到 y=1 沿垂直轴 x=0 均匀分布。但如果该模型生成样本 (θ, z),则其分布根本不会重叠。在这种情况下,会发生梯度消失问题,会使标准 GAN 崩溃。
所以基于这一事实,这篇论文的作者提出使用 Wasserstein 距离,而不是 JS 距离。Wasserstein 距离定义为:

我们可以这样解读这一等式:首先,所有可能的配置都会被选取,假设是 P_r(x) 和 P_g(x)。然后这些点会根据这两个分布来配对。在那之后,它会计算每组配置中配对的平均距离。这里的 inf 可以被视为最小值,这样最后它将从所有可能的配对配置中选择出最小的平均距离。这篇论文提出使用这一距离度量来替代 f-距离,这样它就不再是密度比的函数的。通过这种方式,即使两个分布没有重叠,Wasserstein 距离也仍然可以描述它们相距多远,并且通过这种方式能从根本上解决梯度消失问题。
由于初始的 Wasserstein 距离定义具有难以解决的计算复杂性,所以研究者使用了一种替代定义:

这会导致 Kantorovich-Rubinstein二元性。
值得注意的是,当且仅当 f(x) 的梯度的幅度由 K 在该空间的所有部分设定了上界时,f(x) 是 K-Lipschitz。这篇论文通过将权重限制在一定范围内,使用网络来近似建模 K-Lipschitz。这里的上界可以被视为是一个最大值(二元表达式)。理论上,其目标是寻找到一个 critic 函数,以最大化真实样本均值和伪造样本均值之间余量。
WGAN 算法

上面描述了 Wasserstein 生成对抗网络(WGAN)算法。经过前面的知识介绍之后,这个算法看起来就更简单一些了。总结如下:
- 更新 Critic n 次迭代,之后更新生成器;
- 对于 Critic 的每次迭代,基于 Wasserstein 距离更新梯度,然后剪切权重;
- 使用 RMSProp;
- 像普通 GAN 那样更新生成器。
下面给出了实现 WGAN 算法的代码示例:
# (1) update Critic Network
for p in netD.parameters():
p.requires_grad = True
netD.zero_grad()
# train with real
real_cpu, _ = data
netD.zero_grad()
batch_size = real_cpu.size(0)
input.data.resize_(real_cpu.size()).copy_(real_cpu)
errD_real = netD(input)
errD_real.backward(one)
# train with fake
noise.data.resize_(batch_size, nz, 1, 1)
noise.data.normal_(0, 1)
fake = netG(noise)
input.data.copy_(fake.data)
errD_fake = netD(input)
errD_fake.backward(mone)
errD = errD_real - errD_fake
optimizerD.step()
# (2) Update G network
for p in netD.parameters():
p.requires_grad = False # to avoid computation
netG.zero_grad()
noise.data.resize_(opt.batchSize, nz, 1, 1)
noise.data.normal_(0, 1)
fake = netG(noise)
errG = netD(fake)
errG.backward(one)
optimizerG.step()
实证实验
研究者使用 Wasserstein GAN 进行了一些定量实验,并且表明相比于标准 GAN,使用 WGAN有显著的实际好处。
他们提到了两个优势:
- WGAN 的损失表现出了收敛的特性。

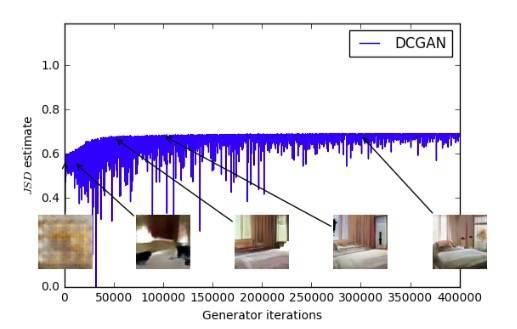
如上所示,上图为 WGAN,下图为标准 GAN。对于 WGAN,随着损失快速下降,样本质量也会增长。相比于 WGAN,标准 GAN 算法的误差曲线是不稳定的,甚至会增大。
- 优化过程的稳定性提升。

上图是使用无批归一化的该算法得到的生成器的结果。左上基于 WGAN 算法,右上基于标准 GAN 算法。标准 GAN 不能学习的地方,WGAN 依然能稳定地生成合理的样本。
分析师简评
这篇论文提出了一种名为 Wasserstein GAN 的新型生成对抗网络。它从理论上向我们说明了已有的 GAN 模型失败的原因以及 WGAN 有效的原因。相比于 DCGAN 等标准 GAN,这篇论文表明即使没有批归一化,WGAN 也能稳定地训练。但也仍然存在一些值得关注的地方。首先,在更新生成器之前他们更新了 critic n 次迭代,这意味着 critic 的迭代次数仍是人工调节的。是否存在优化两者的更好方法呢?第二,WGAN 在非常深度的网络上的泛化情况如何,比如 152 层的残差网络?第三,他们限制了权重的范围以确保 Lipschitz 连续性,但是否存在建模这种情况的方法?最后,生成对抗训练能否用于词预测等 NLP 任务,同时还能保持稳定性?