「AI初识境」近20年深度学习在图像领域的重要进展节点
https://www.toutiao.com/i6694432730714735117/
这是专栏《AI初识境》的第3篇文章。所谓初识,就是对相关技术有基本了解,掌握了基本的使用方法。
这是本系列的最后一篇非技术文章,我们总结一下深度学习技术在图像领域的重要历史性节点,本来打算语音,自然语言处理一起的,文章太长以后再谈。
作者&编辑 | 言有三
1 前深度学习时代
从早期的全连接神经网络到卷积神经网络CNN,跨度超过半个世纪,我们在上一期文章中进行过回顾,大家感兴趣的可以回过头去看。
几个重要的节点是:
1943年:MP模型的提出。
1960~1980年:视觉机制的发现。
1979年:Neocognitron的提出,卷积神经网络的萌芽。
1986年:反向传播算法被用于神经网络的优化并开始流行,同期动量算法提出被用于加速SGD。
1990年:TDNN模型,卷积神经网络被用于语音识别。
1992年:Max-pooling被提出,此后成为卷积神经网络标准组件。
1997年:LSTM被提出,促进了语音,自然语言处理等领域等发展。
1998年:LeNet5和MNIST数据集被提出和整理,两者可以说各自是卷积神经网络和图像数据集的“Hello World”,总会被拿出来说一说。
所谓深度学习,是以人工神经网络为基本架构的特征学习方法,涵盖监督学习,无监督学习,半监督学习,增强学习等,模型结构以卷积神经网络为代表,它不仅被用于图像,也被用于语音,自然语言处理等各种领域。
2 深度学习时代
以2006年为分水岭,下面尽量挑重点的,在学术界和工业界有重大意义,同时又广为人知的来说。
2006年Hinton等人在science期刊上发表了论文“Reducing the dimensionality of data with neural networks”,揭开了新的训练深层神经网络算法的序幕。利用无监督的RBM网络来进行预训练,进行图像的降维,取得比PCA更好的结果,通常这被认为是深度学习兴起的开篇。

2006年,NVIDIA推出CUDA,GPU被用于训练卷积神经网络,是当时的CPU的训练速度的四倍。到现在,GPU是研发强大算法必备的条件,这也是大公司屡屡取得突破而小公司只能亦步亦趋跟随的一个很重要的原因。NVIDIA的GeForce系列,搞深度学习的谁还没有呢?

2006~2009年,在图像MNIST数据集,语音TIMIT数据集以及一些垂直领域的小比赛比如TRECVID也取得了不错的进展,但是还算不上突破性的,所以也不怎么为人所知。
2009年,CIFAR10和CIFAR100数据集被整理。由于MNIST是一个灰度图像数据集,而大部分现实的任务为彩色图像,所以Alex Krizhevsky等学者从TinyImage数据集中整理出了CIFAR10和CIFAR100。与MNIST一样CIFAR10数据集也有60000张图像,不过图像为彩色。图像大小是32×32,分为10个类,每类6000张图。其中50000张用于训练,另外10000用于测试。CIFAR100则分为100个类,每一类600张图像。
这两个数据集与MNIST一样,在评测方法时非常常见。

2009年,ImageNet数据集被整理,并于次年开始每年举办一次比赛。ImageNet 数据集总共有1400多万幅图片,涵盖2万多个类别,为计算机视觉领域做出了巨大的贡献,至今我们仍然使用着Imagenet来评估算法,以及预训练其他任务的模型。

2009年前后几年时间,属于融汇贯通各种技术,数据和装备,典型的蓄力阶段,辅以小数据集和若干比赛的突破。
2011年,CNN以0.56%的错误率赢得了IJCNN 2011比赛并超过了人眼,这是一场交通标志的识别比赛,研究者开始对深度学习在自动驾驶中的应用前景展现出浓厚的兴趣,毕竟在上个世纪90年代无人车的研究就已经开始了。现在无人车是非常大的一个应用前景。
2011年,Glorot等人提出ReLU激活函数,有效地抑制了深层网络的梯度消失问题,现在最好的激活函数都是来自于ReLU家族,简单而有效。
2012年,经典书籍《大数据时代》出版,作者维克托•迈尔•舍恩伯格在书中指出大数据时代来了,我们应该放弃对因果关系的追求,而关注相关关系,从“为什么”开始转变到“是什么”,这不就是统计学习人工智能学派的基础工具深度学习最擅长做的吗。
也就是从那个时候开始,人们大喊,大数据来了,一时之间,数据科学家,数据挖掘工程师成为热门。

2012年,Hinton的学生Alex Krizhevsky提出AlexNet网络,以低于第2名10%的错误率赢得了ImageNet竞赛。当时Alex Krizhevsky使用了两块显卡GTX580,花了6天时间才训练出AlexNet,我相信如果有更多的资源,AlexNet一定是一个更好的AlexNet。
2013年Hinton的学生Zeiler和Fergus在研究中利用反卷积技术引入了神经网络的可视化,提出了zfnet,对网络的中间特征层进行了可视化,为研究人员检验不同特征激活及其与输入空间的关系成为了可能,慢慢地大家也开始都关注起深度学习的作用机制。

2013年,Ross Girshick等人提出了目标检测模型RCNN,开创了CNN用于目标检测的基准之一。随后研究者针对该系列提出Fast RCNN,Faster RCNN等等。

2014年,GoogLeNet和VGGNet分别被提出,获得ImageNet分类赛的冠亚军。VGGNet很好的展示了如何在先前网络架构的基础上通过简单地增加网络层数和深度就可以提高网络的性能,GoogleNet模型架构则提出了Inception结构,拓宽神经的宽度,成为了计算效率较高的深层模型基准之一。

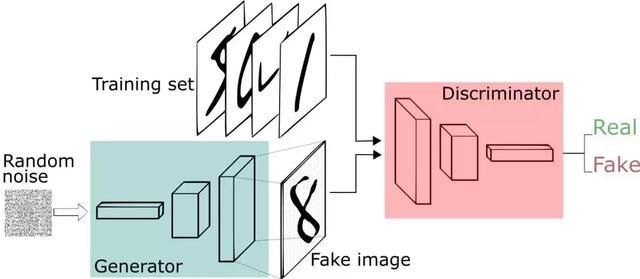
2014年,无监督学习网络GAN横空出世,独立成了一个新的研究方向,被LeCun誉为下一代深度学习,此后GAN在各大领域,尤其是图像领域不断“建功立业”,并与各类CNN网络结构进行了融合。
2015年,ResNet获得了ImageNet2012分类任务冠军,以3.57%的错误率表现超过了人类的识别水平,并以152层的网络架构创造了新的模型记录,自此残差连接在CNN的设计中随处可见。
2015年,全卷积网络Fully Convolutional Networks被提出用于图像分割,自此图像分割领域也即迎来大爆发。
2014年,Google启动AlphaGo的研究,2015年10月AlphaGo击败欧洲围棋冠军樊麾成为第一个无需让子即可击败围棋职业棋手的计算机围棋程序。2016年3月,AlphaGo在一场世界瞩目的比赛中4:1击败顶尖职业棋手李世石,2017年5月23至27日在乌镇围棋峰会上,AlphaGo和世界第一棋手柯洁比试全胜。

AlphaGo的成功,对人工智能的普及工作意义非常深远,让不仅是从业者,外行人也开始领略到人工智能的强大,而背后就有卷积神经网络的功劳。
此后便是卷积神经网络在计算机视觉各大领域攻城略地,无往而不胜。关于都有哪些方向,可以参考这个。
「AI白身境」一文览尽计算机视觉研究方向
重要的节点通常都承前启后,不管是作为谈资,还是设身处地地站在当时的节点来思考一番,都是受益良多的。
本文是有史以来罕见的短文,一是为了给大家留出更多的思考空间,另一方面也是希望大家认真去翻翻我们以前的文章,信息量很大。