音频分类综述
一、几种常用的音频分类算法
最小距离法、神经网络、支持向量机、决策树方法、隐马尔可夫模型等典型算法。
1. 最小距离法
最小距离分类法的优点是概念直观,方法简单,有利于建立多维空间分类方法的几何概念。在音频分类中应用的最小距离分类法有k近邻(k-Nearest Neighbor,简称K-NN方法和最近特征线方法(Nearest Feature Lin,简称NFL等。
K近邻方法的思想是根据未知样本X最近邻的k个样本点的类别来确定X的类别。为此,需要计算X与所有样本X的距离d(X,X),并且从中选出最小的k个样本作为近邻样本集合KNN,计算其中所有属于类别W的距离之和,并且按照以下判别规则进行分类:
C(x)=argmin∑d(x,xi),其中xi∈ kNN,C(xi)=wj,wj∈c,C为类别集合C={W1,… ,Wn}
由于k近邻方法利用了更多的样本信息确定它的类别,k取大一些有利于减少噪声的影响。但是由于k近邻方法中需要计算所有样本的距离,因此当样本数目非常大的时候,计算量就相当可观。取k=1时,k近邻方法就退化为最近邻方法。
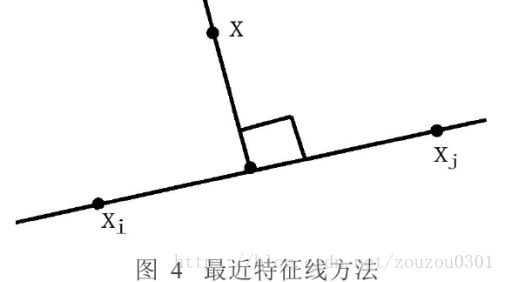
最近特征线方法是从每一类的样本子空间中选取一些原型(Prototype)特征点,这些特征点的两两连线称为特征线(Feature Line),这些特征线的集合用来表示原先每一类的样本子空间。
设类C的原型特征点集合:Xc={X|1≤i≤Nc},其中Nc为类C的原型特征点数目,则对应的特征线的数目为Kc=Nc(Nc- 1)/2,而类C的特征线集合Sc{XX|
1≤i,j≤Nc,i≠j}构成类C的特征线空间,它是类C的特征子空间。一般所选取的原型特征点的数目比较少,因此特征线的数目也比较少。未知样本X与特征线
XX的距离定义为X在XX上的投影距离,如图4所示,而X与类别C的距离为X与类C的特征线空间中的所有特征线的最短距离。
2.神经网络(NeuralNetwork)
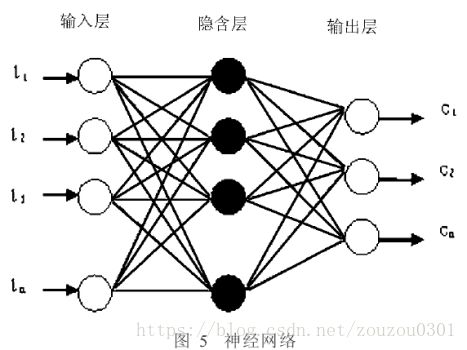
在使用神经网络进行音频分类时,可以令输入层的节点与音频的特征向量相对应,而输出层的节点对应于类别C,如图5所示。在训练时,通过对训练样本集中的样本进行反复学习来调节网络,从而使全局误差函数取得最小值。这样,就可以期望该网络能够对新输入的待分类样本T输出正确的分类C。
3.支持向量机(SupportVectorMachine,简称为SVM)
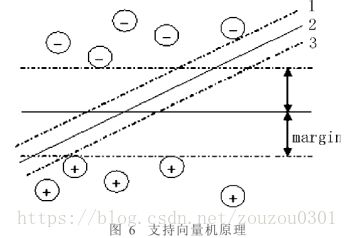
支持向量机是Vapnik等人提出的以结构风险最小化原理(Structural Risk Minimization Principle)为基础的分类方法。该方法最初来自于对二值分类问题的处理,其机理是在样本空间中寻找一个将训练集中的正例和反例两类样本点分割开来的分类超平面,并取得最大边缘(正样本与负样本到超平面的最小距离),如图6所示。该方法根据核空间理论将低维的输入空间数据通过某种非线性函数(即核函数)映射到一个高维空间中,并且线性判决只需要在高维空间中进行内积运算,从而解决了线性不可分的分类问题。
4.决策树方法。
决策树是一种结构简单、搜索效率高的分类器。这类方法以信息论为基础,对大量的实例选择重要的特征建立决策树。
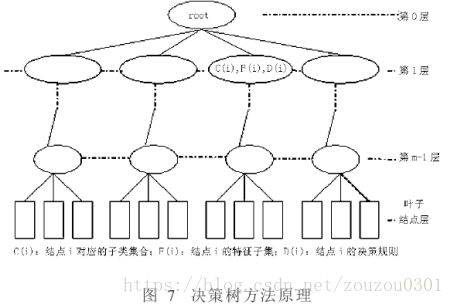
最优决策树的构造是一个NP完全(NP Com-pleteness)问题,其设计原则可以形式化地表示为minP(T,F,d|D),δ(T,F,d),其中T为特定的决策树结构,F和d分别为分枝结点的特征子集和决策规则,D为所有的训练数据,P(T,F,d|D),为在数据集合D上选取特征集合F和决策规则d训练得到的结构为T的决策树的分类错误ε的条件概率。因此,决策树的构造过程可以分为三个问题:选取合适的结构,为分枝结点选取合适的特征子集和决策规则。常用的决策树构造方法有非回溯的贪心(Greedy)算法和梯度上升算法。
5.隐马尔可夫模型(Hidden Markov Model,简称HMM)方法
隐马尔可夫模型(HMM)的音频分类性能较好,它的分类对象是语音(speech)、音乐(music)以及语音和音乐的混合(speech + music)共3类数据,根据极大似然准则判定它们的类别,最优分类精度可达90.28%。
HMM本质上是一种双重随机过程的有限状态自动机(stochastic finite-state automata),它具有刻画信号的时间统计特性的能力。双重随机过程是指满足Markov分布的状态转换Markov链以及每一状态的观察输出概率密度函数,共两个随机过程。HMM可以用3元组来表示:λ=(A,B,π),其中A是状态Si到Sj的转换概率矩阵,B是状态的观察输出概率密度,π是状态的初始分布概率。
二、研究意义 随着计算机技术、网络技术和通讯技术的不断发展,图像、视频、音频等多媒体数据己成为信息处理领域中重要的信息媒体形式,其中音频信息占有很重要
的地位。如何对海量音频信息进行处理、组织分析和利用是信息处理领域中的一个重要课题,而音频分类是其中的关键技术之一。
音频是多媒体中的一种重要媒体,我们能够听见的音频频率范围是60Hz到20kHz,其中语音大约分布在300Hz到4000 Hz之内,而音乐和其它自然声响是全范围分布。声音经过模拟设备记录或再生,成为模拟音频,它们经数字化成为数字音频。数字化时的采样率必须高于信号带宽的二倍,才能正确恢复信号,样本可用8位或16位比特表示。
三、音频信息检索分类
1.语音检索
以语音为中心的检索,采用语音识别等处理技术.例如电台节目、电话交谈、会议录音等。
利用大词汇语音识别技术进行检索 这种方法是利用自动语音识别(ASR)技术把语音转换为文本,从而可以采用文本检索方法进行检索。
1. 音乐检索
以音乐为中心的检索,利用音乐的音符和旋律等音乐特性来检索。例如检索乐器、声乐作品等。
检索音乐利用的是诸如节奏、音符、乐器特征.节奏是可度量的节拍,是音乐中一种周期特性和表示。音乐的乐谱典型地是以事件形式描述,例如以起始时间、持续时间和一组声学参数(基音、音高、颤音等)来描述一个音乐事件。
2. 音频检索
以波形声音为对象的检索,这里的音频可以是汽车发动机声、雨声、鸟叫声,也可以是语音和音乐等,这些音频都统一用声学特征来检索[2]。
音频数据的训练、分类和分割方便音频数据库的浏览和查找,基于听觉特征的检索为用户提供高级的音频查询接口。音频检索是针对广泛的声音数据的检索,分析和检索的音频可以包含语音和音乐,但是采用的是更一般性的声学特性分析方法。