FCN-alexnet操作实战
之前,读过很多大神的FCN数据集制作与训练地博客,也成功地开始了训练与测试。最近由于换电脑后,FCN模型等文件全部丢失,不得不重头训练。花费了3个多小时终于重新开始训练,现在把从数据准备到开始训练的操作过程以及遇到的问题详细地描述一下,以方便自己下次使用的时候可以加快速度。(测试过程待更新)
1.首先是装Caffe,这个过程现在已经有很快、很方便的方法可以装了。不过我还是比较喜欢老式的安装方法,新的还有待尝试。老的安装方法可见:https://blog.csdn.net/jydada/article/details/88871783
2.装好了Caffe之后,去gitlhub上下载FCN的包:https://github.com/shelhamer/fcn.berkeleyvision.org
3.这个包里有很多模型,你可以自由选择,我选择的是FCN-alexnet模型。(本人非常喜欢用AlexNet,原因估计也不用多说,大家都懂的)
选择好模型后,就可以开始整个流程。
数据集的制作
我们的数据集都是使用的原图片,没有转化为mat等其他格式的文件,但原FCN模型中程序设置为需要输入mat文件,所以我们对其进行修改
我们先打开fcn下voc_layers.py这个文件,里面我们可以看到 class VOCSegDataLayer(caffe.Layer):和 class SBDDSegDataLayer(caffe.Layer) 这两个类,第一个是测试时数据输入调用的python类,第二个是训练时数据输入调用的python类。而这类里面,分别是对输入数据的一些预处理操作。
我们只要进入class VOCSegDataLayer(caffe.Layer)这个类,copy出def load_label(self, idx):这个函数, 
将其复制到class SBDDSegDataLayer(caffe.Layer)类下,并注释掉原代码,并修改voc_dir为sbdd_dir
这下就直接读取图像文件而不用转换成mat了。
然后就是修改路径了, 
根据每个人的情况修改SegmentationClass这个路径,大家可以看到其前后各有两个{},后面的idx为图片名称,根据生成的txt来读取。
这里我用的都是.tif格式,只要把.png改成.tif即可,十分方便。(制作images和labels的过程就不介绍了,images就是原图,labels就是我们制作的索引图,也称为标签图,格式我用的是uint8)
下面就是我的数据集的截图,test文件夹里面的一样。
预加载权值模型
caffemodel-url中是训练之前预加载的权值模型的下载地址,打开这个文件,并下载这个模型
deploy.protptxt是训练好模型之后,进行图片预测的网络模型
net.py是生成网络模型的文件,暂时用不到
solve.py和solve.prototxt是网络训练之前一些数据路径和参数的设置
train.prototxt和val.prototxt不用说了,一个是训练模型,一个是训练过程中测试的模型
好下面开始修路径,打开solve.py,修改如下图所示:
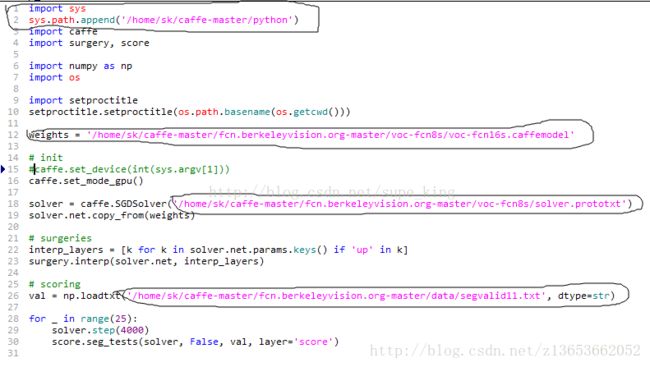
见图中画框的部分,第一个框是加载你python与caffe的接口部分路径,第二个框是你下载的训练之前的权值模型,第三个框是不用解释,至于第四个框是你的训练数据data里面的一个路径,至于segvalid11.txt这个文件你可能没有,没有关系后面给出。还有就是注释了一条caffe.set_device(int(sys.argv[1]))!!!!
注:如果不想用已有model进行fine-tune,注释掉19行solver.net.copy_from(weights),后面还需要根据你分的类数进行prototxt文件的修改,这个后面会提到。
修改完这个文件,打开solver.prototxt,修改如下: 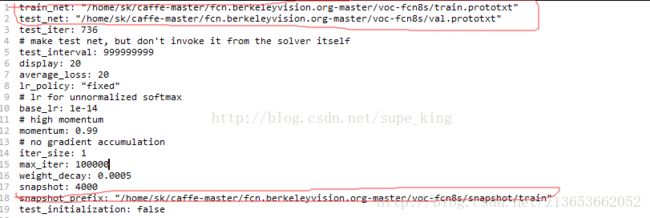
第一个框不用说是什么路径很明显,第二个框是你训练时保存的模型地址。其中参数:
test_iter是测试时,一次会测试多少张图片
display是训练多少次,终端中展示一次loss值
max_iter是最多训练多少次(但是似乎这里不管用,前面solver.py里面那个才循环是关键,有兴趣的自己可以看看)
snapshot是训练到多少次保存一次
其他参数,见> http://blog.csdn.net/q6324266/article/details/52451088
这个设置完成之后,就差最后一步路径设置了 打开train.prototxt: 
修改路径到dataset的位置,这个dataset就是我们构建的训练集,后面详细介绍
同理打开val.prototxt,修改路径同train.prototxt。
注:这里介绍一下param_str这一行,这里面有4个参数(sbdd_dir,seed,split,mean),sbdd_dir为数据集的路径(train.prototxt和val.prototxt的这一参数一样,因我们把训练集和测试集都放到这一路径下),split为生成的txt文件名(训练集生成一个,测试集生成一个)。其他参数还没有仔细研究
训练
1 $ cd cd siftflow-fcn32s/
2 $ python solve.py这里会遇见几个问题:
(1)No module named surgery,score

原因是下载的fcn源码解压根目录下有两个文件:surgery.py和score.py。这两个文件是下载下来就自带的,并不是caffe自带的,也不是前边我安装caffe时需要配置的。由于我是在/fcn根目录/siftflow-fcn32s/这个文件夹下执行的,会导致找不到这两个文件。所以,解决方案就是:
cp surgery.py score.py ./siftflow-fcn32s/将surgery.py和score.py拷贝到siftflow-fcn32s下。
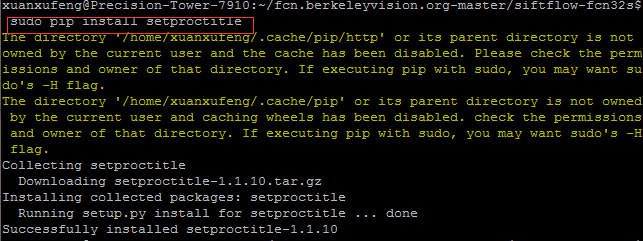
(2)ImportError: No module named setproctitle

解决方案是:安装setproctitle! sudo pip install setproctitle
(3)IndexError: list index out of range

解决方案:修改GPU编号为0号GPU

(4)No modulw named siftflow_layers

解决方案:疯了,干错把根目录下边的所有.py文件全拷贝到siftflow-fcn32s里边去吧。

好了,现在可以开始训练了!看看训练过程: