论文笔记——FEELVOS:Fast End-to-End Embedding Learning for Video Object Segmentation
论文题目:Fast End-to-End Embedding Learning for Video Object Segmentation
论文链接:https://openaccess.thecvf.com/content_CVPR_2019/papers/Voigtlaender_FEELVOS_Fast_End-To-End_Embedding_Learning_for_Video_Object_Segmentation_CVPR_2019_paper.pdf
这是19年cvpr上的一篇文章,主要是做的半监督VOS的task。半监督VOS就是给定视频序列第一帧的mask,然后预测后续frame中该instance的mask的位置。以往一些比较经典的方法,都是要在inference阶段,针对第一帧进行微调。这个做法显然是耗费时间的。
本文提出的FEELVOS不需要在第一帧进行微调,所以可达到fast;模型结构简单,仅采用了一个神经网络(18年Davis挑战赛冠军模型PReMVOS用了四个网络),所以比较simple;针对视频中多个instance,可以end-to-end训练;该模型的J&F值表现不错,可以说是strong。
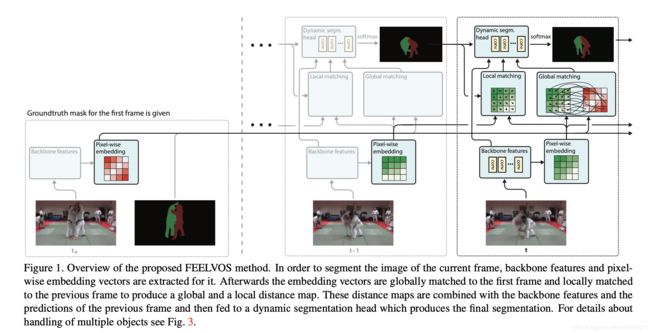
上图是FEELVOS的总览图,首先通过deeplabv3(拿掉最后的output层)得到特征图;在后面加入一个embedding层,将feature map映射到embedding空间的向量;根据这个embedding向量,计算两个distance map:分别是local matching和global match,前者利用当前帧和前一帧的embedding,后者利用当前帧和第一帧的embedding,计算各自的distance map。最后将feature map(不是embedding),两个distance map,和前一帧的预测这四部分作为输入,送入dynamic segmentation head(也是一个多层的CNN)。
值得注意的是,需要对第一帧出现的每一个instance进行上述预测。网络实现了对多目标分割的end-to-end训练,并且在embedding方面,并没有显式地用损失函数进行约束,而是作为了一种internal guidance。
下面分别介绍每一部分的细节:
Semantic Embedding
对于deeplabv3(去掉输出层)提取出的feature map,引入到一个embedding layer(深度分离卷积),对特征图上的每一个点,提取其embedding向量。这每一点对应的embedding向量代表着该点的类别信息。如果两个pixel属于同一类别,那么两个pixel对应的embedding向量之间的距离就比较近;如果两个pixel不属于同一类别,那么对应的embedding向量之间的距离就会比较远。这个距离的定义如下:

该距离在0-1之间。其中p表示当前帧的特征图pixel,而q表示之前帧特征图的pixel(第一帧的或是前一帧的)。在定义出embedding向量的距离以后,我们就可以求解两个distance map了。当q表示第一帧的某像素时,就可以求解global matching;当q表示前面一帧的时候,此时可以求解local matching。
Global Matching
假设 P t P_{t} Pt表示第t帧的像素集合(stride为4), P t , o ⊆ P t P_{t,o}\subseteq P_{t} Pt,o⊆Pt表示第t帧属于, p ∈ P t p\in P_{t} p∈Pt表示第t帧中的某一个像素,而 G t , o ( p ) G_{t,o}(p) Gt,o(p)表示p像素对应的global matching distance的值,其计算公式如下:
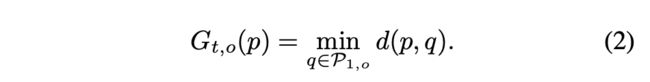
因此,如果想得到完整的global matching distance map,需要对当前帧的每一个像素点p,都采用第一帧属于类别o的区域的embedding,来计算两者之间的距离(公式(1)),计算完所有距离之后取最小值。
Local Previous Frame Matching
其实这个计算过程和global的差不多,其计算公式如下:
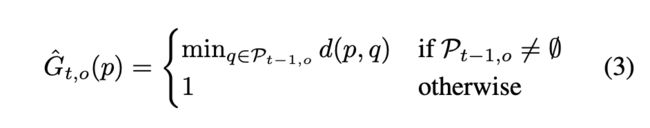
不同的是这里有一个分支:t-1帧可能不存在该instance,所以这种情况下设定其值为最大的1。我们知道,相邻的两帧之间物体的变动不会太大,因此如果对于整张图上进行计算,则开销太大。所以这里选择了一个k邻域,只计算和当前像素附近k邻域范围内的embedding之间的distance,然后取最小。
需要注意的是,DAVIS2017数据集中,存在多目标的情况。在这种情况下,需要将每一个目标过一遍网络,而且上面的两个distance map只是针对当前目标的matching,如果有多个目标,则需要根据上述公式对每一个目标都计算其两个distance map。
Dynamic Segmentation Head
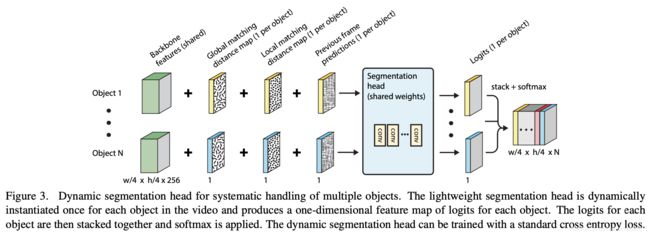
这个head网络的输入包括四部分:feature map(非embedding),两个distance map,和前一帧的预测。对于每一个目标,都预测一张一维的feature map,每个点表示属于这类物体的概率大小。每一个instance预测一张一维的map,最后将它们stack起来,再经softmax归一化,最后用cross entropy来计算loss。
Training procedure
随机选取mini-batch个视频,在每一个视频中随机选取三帧:一个作为reference,即上述的第一帧;另外两个相邻的帧,一个作为previous,一个作为current frame,计算的loss只包括当前帧的loss。这里是用previous帧的ground truth来计算local matching;并通过逐像素的将该物体区域设定为1,而其他物体区域的像素设定为0,来定义previous frame的prediction
Inference
对于每一帧来说,只需要简单的前向传播即可。首先给定一个视频序列和第一帧的ground truth,将第一帧输入得到embedding向量。然后对后续的每一帧,都计算其feature map和embedding向量,通过和前一帧的embedding进行对照,得到local matching;通过和第一帧的embedding向量进行对照,得到global matching。随后分别将每个object输入到dynamic segmentation head中(我的理解是:输入有4部分,但对于每一个物体来说,不同的地方包括previous prediction以及两个distance map(共3个维度),而feature map(256维)是一个共享的特征),因此对于每一个目标,就可以得到一张表示logits的特征图。每个object过一遍网络,将所有的feature map做stack,随后用逐像素的argmax做最终的segmentation。
实现细节
backbone:DeepLabv3+,基于Xception-65,得到的特征图stride为4;
embedding层:feature后接深度可分离卷积,33独立通道的卷积,加上11卷积将每个pixel映射到100维的embedding空间;
segmentation head:采用深度可分离卷积,大的卷积核77,维度为256,最后接11卷积来提取维度为1的logits;
在global matching的计算中,如果对所有符合条件的像素进行计算,开销会非常大。因此作者对每个目标,在第一帧中最多采样1024个点,可简化计算;
local matching中k临近区域的k=15.
实验部分
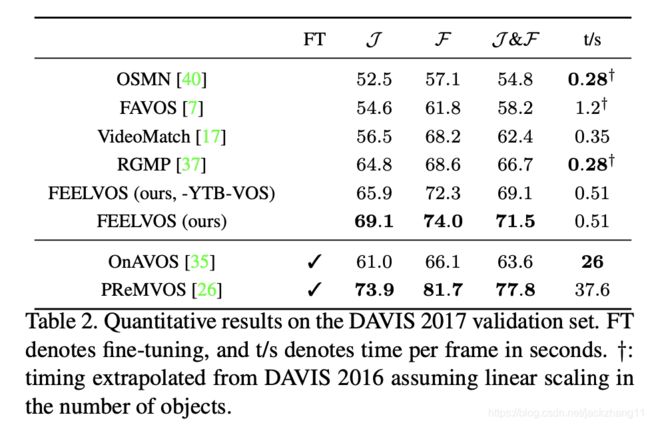
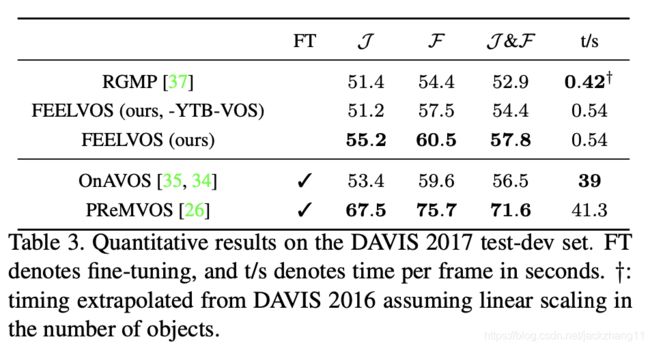
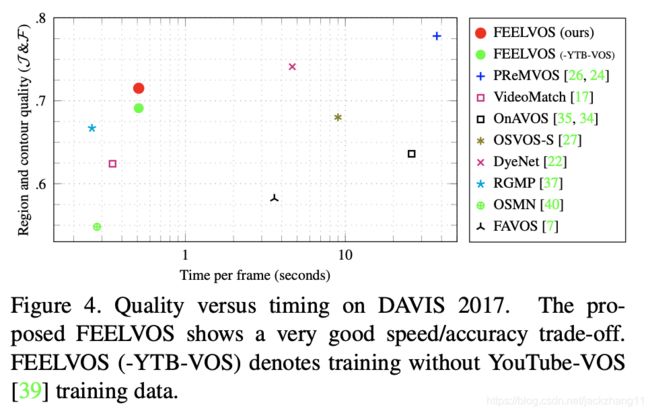
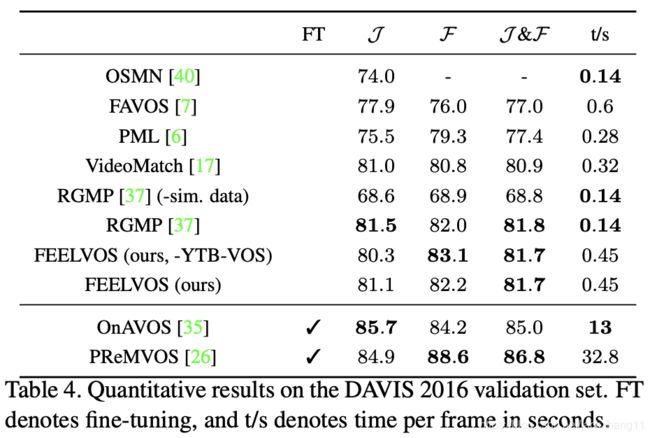
消融实验: