ID生成器是指能产生不重复ID服务的程序,在后台开发过程中,尤其是分布式服务、微服务程序开发过程中,经常会用到,例如,为用户的每个请求产生一个唯一ID、为每个消息产生一个ID等等,ID生成器也是进行无状态服务开发的重要需求之一。
ID生成器有其特殊要求:
(1) 产生的ID不能重复,在任何情况下产生的ID都不能重复,例如:在ID生成器程序重启之后,ID生成器产生的新ID不能与重启之前产生的ID重复;
(2) ID尽可能短小,由于很多情况下,ID需要被存储或者传输,因此在满足ID不重复的基础上ID长度尽可能短小,以降低存储或传输资源的浪费;
(3) 支持高并发低延时请求,ID生成器需要应付大量的请求服务,因此要提供高并发的请求,同时要求请求响应的延时时间尽可能小,一般在10毫秒以内;
(4) 支持多ID,在实际开发过程中,有太多的情形都需要ID服务,例如:每个消息、每个用户请求、每次事务的处理等等,这些不同的应用场景都需要自己的ID,因此ID生成器需要满足同时为不各应用场景产生不同ID的服务;
(5) 在特殊场合下还需要满足ID有序,例如递增或者递减;
(6) 高可靠服务,在ID生成器的实际部署过程中,可能会遇到断电、断网、程序异常崩溃等等各种奇怪的问题,因此,如何能保证ID生成器提供稳定高效的服务,是分布式服务开发过程中,首先要解决的问题。
下面将介绍如何使用redis的INCR来快速开发一个满足上述需要的ID生成器服务,INCR命令是Redis针对value为字符串操作,它要求value的最大值为64位,每次操作将redis中的value值加1,并返回递增之后的值。其架构如下所示:

使用redis作为ID生成器的数据源,为满足ID生成器的特殊要求,需特殊部署redis:
(1) 要启用两个独立的redis,这里的两个redis需要独立部署,尽量不要和其他业务复用redis;
(2) 两个redis一个为主一个为从,主提供ID生产服务,从做持久化,从而保证数据源的高效、安全;
上述部署中,按照如下方式满足ID生成器的特殊需求:
(1) 用主redis提供产生ID服务,但不进行持久化操作,Redis本身的高性能可满足ID生成器的高性能和低延时的要求,在实际测试过程中,可产生300多万/秒的ID,且请求延时为1~2毫秒;
(2) 用从Redis做持久化,保证在master挂掉之后,slave能提供服务,主从全部挂掉之后,ID数据源也被持久化到了硬盘,从而保证重新启动redis之后,ID会从持久化的位置开始产生,就不会再产生重复的ID;
(3) redis本身的key-value机制就可以提供多种ID服务,只需要为每个需求的ID产生不同的key值即可,例如在redis中消息ID的key为“id.msg”,日志ID的key值为“id.log”等等,这样消息的ID和日志的ID就可以独自完成递增操作而互补干扰。
(4) redis的INCR和DECR两个指令,可以产生递增或者递减的ID服务;
(5) redis的ID的类型最大长度为64位,可以从0开始,依次递增产生,所产生的ID就是最短的;
如果项目紧急,使用上述方式就可以很快搭建一个ID生成器服务,但是上诉ID生成器服务还存在一些缺陷:
(1) 与应用耦合高,没有对外屏蔽掉内部实现细节,例如redis,在使用时,用户完全不需要知道ID生成器使用什么产生的ID;
(2) 扩展性差,在项目规模较大时,ID的应用会非常多,如果用一个redis无法满足需求时,不方面扩展;
真正的ID生成器服务还需解决上述问题。
前面介绍的是利用redis快速搭建一个ID生成器服务,这种方式搭建的ID生成器服务还存在一些缺陷:
(1) 与应用耦合高,没有对外屏蔽掉内部实现细节,例如redis,用户完全不需要知道ID生成器使用什么产生的ID;
(2) 扩展性差,在项目规模较大时,ID的应用会非常多,如果用一组redis无法满足需求时,不方面扩展;
下面将对上述的ID生成器进一步改进,改进方式为通过thrift将redis封装起来,形成一个独立的ID生成器服务,对外以rpc方式提供ID服务,采用thrift框架可以带来如下好处:
(1) 高性能,thrift框架提供多种服务运行方式,能提供高性能的rpc服务;
(2) 多语言支持,thrift框架对多语言支持非常好,而ID生成器本身作为一个基础的、通用性的服务,它需要为各种应用场景都能提供ID服务,因此多语言的支持对其提供服务非常有帮助。
修改之后的框架如下所示:
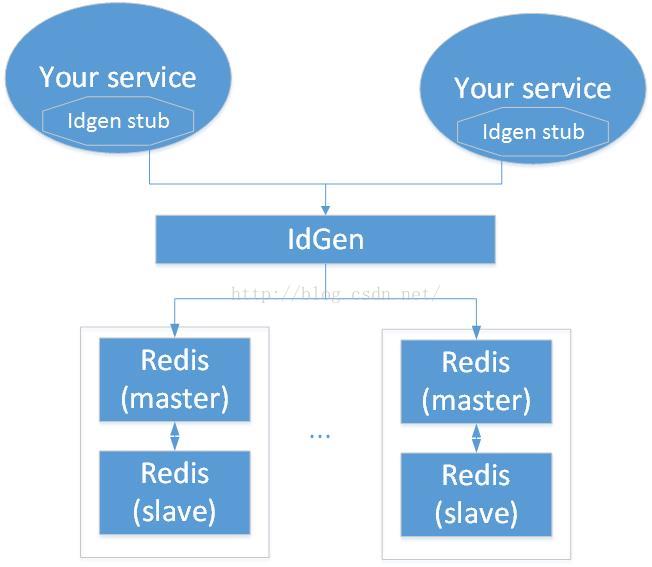
上述架构中,IdGen是通过thrift框架开发的ID生成器服务,为无状态服务,可根据需要水平扩展,它内部管理多个redis主从对,每个redis主从对都按照:主Redis提供服务不持久化,从Redis不提供服务但持久化的方式;IdGen内部屏蔽对redis的操作,并完成对redis主从对的管理,它可根据ID的类型,将不同的Id类型放在不同的redis主从对中,这样在项目规模扩大,ID的类型和请求量增加时,访问压力将会被分散到各个Redis分组中;
另外IdGen需要能动态管理数据源Redis的分组,即满足两个条件:
(1) 动态添加新的ID类型;
(2) 动态添加Redis分组;
要实现上述两种要求的方法非常多,最简单的可以采用数据库来存储Redis分组信息和ID类型与Redis分组的对应关系,如下图所示:

在该框架中,提供如下方式的RPC接口服务:
long getId(String idType)
调用方只需提供他需要的ID类型,ID生成器即可为之产生一个对应类型的ID。
前面两个ID生成器只是简单的完成功能,如果实际应用到生产环境,则对ID生成器的要求更高,具体包括但不限于以下几点:(1) 产生全局唯一、且单调递增的ID;
(2) 任何情况下ID不能重复或者回退;
(3) 具备高效率产生ID的能力;
(4) 具备提供多种ID的能力;
(5) 便于运维管理;
本文档设计的 ID生成器整个系统需要分为四个部分:web管理端、IdGen服务、redis以及mysql,其中:
(1)web管理端用于运维人员通过网页形式管理ID生成器,它可以添加/删除ID、迁移ID等;
(2)IdGen服务属于自研服务,采用Thrift框架,对外提供各种语言的调用接口,对内管理redis和mysql,可水平扩展;
(3)Redis,在本设计中,采用redis作为Id分发器,一个redis可以分发若干类型的ID,当一个redis无法承载请求量时,可以将id类型迁移到新的Redis上。
(4)Mysql,在本设计中,采用Mysql做Id的持久化存储和配置管理,只用一个mysql即可,在实际应用中,还可以采用主从配置提升数据保存的安全性,但是从Mysql只做数据保存,不提供服务,防止主mysql所在主机出现问题时,数据可以正常恢复。 如下图所示:

获取id的接口每调用一次,ID生成器就产生一个id,在接口中每次获取到一个id之后,都需要判断该分配的id值:curID;如下图所示,如果curID < updateID,这里update是更新IP段时对应的ID(当前ID段损耗达到所设置比例对应的ID值),则返回该分配的ID;如果updateID < curID < endID,则要产生一个ID更新任务,如果curID >=endID,则直接返回失败。
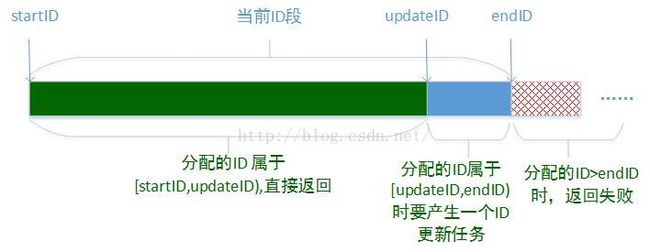
每个IdGen都有一个线程池,用于执行异步任务,在更新ID信息的任务中,该任务包含以下信息:ID的名称,该ID所属的Redis、该ID在IdGen中缓存的对象,此任务需要计算申请ID段的大小,其方法为根据当前段的使用速度来计算:(当前ID-起始ID)/(当前时间-本段加载时间) * 最大加载间隔时间如果计算的结果大于配置参数的上限,则使用上限值,反之,如果小于配置的下限值,则使用下限值。
此更新ID信息的任务将完成以下操作:
(1) 从缓存中重新读取当前id的信息,并与本地保存的信息比较,如果不一致(结束ID、更新ID和更新时间都大于本地保存的值),否则说明缓存已经被其他IdGen更新,只需将本地缓存的数据(本段ID的加载时间、起始ID、结束ID、更新ID)更新为Redis中获取的数据即可;否则,说明该ID在Redis中的数据还未更新,则继续执行;
(2)在对应Redis中,对该ID加分布式锁,如果加锁失败,说明有其他的IdGen正在更新该ID的信息,直接结束当前任务即可;否则,说明当前的IdGen获取了更新该ID信息的权利,继续执行;
(3)计算新申请ID段的大小newIdLen,从数据库中申请新的ID段,提供参数包括:newIdLen、当前系统时间curSysTime,采用存储过程完成,具体需完成对数据库的以下操作: 如果当前ID类型不是有效,则直接返回-1; 将start_id字段更新为start_id + newIdLen; 将last_range字段更新为newIdLen; 将last_load_time更新为当前系统时间; 返回新的start_id
(4)IdGen根据start_id计算该ID段的end_id、update_id,并更新Redis中该ID的相关信息end_id、update_id、当前系统时间更新为新的值,并将startid设置为当前正在分配的ID值;
(5)更新本地缓存中该ID的信息:end_id、update_id、start_id和start_time。
附带一个开源的ID生成器,该ID生成器按照此文档的设计思路开发,其源码位置为:https://github.com/xiaoyaozixyz/idgenerator