一行代码引发的思考 之 @Tranactional(Spring注解式事务)
一.假设一个一个业务场景
- SSM框架,MySQL数据库InnoDB存储引擎
- 某个业务需要将student表中student_id = 3 的 type 修改成 1,条件是这个学生所在班级的其它学生的type都不等于 1 .也就是先查询在修改.

- 且有可能产生并发.
二.分析问题
- 根据问题的描述,我们貌似直接在service层里定义个方法,写个查询,然后if判断修改就ok了,事务是具有隔离性的,解决了并发问题.ok,就是这样的,然后我们写了两个sql.
//第一个sql, 我们查询这个学生所在班级是不是type都不等于1
select count(student_id)
from student
where class_id = 1001 and type = 1
//我就想知道这个班级的学生有没有type = 1 的,如果有,我就不做修改, 如果没有的话,我就修改,
update student
set type = 1
where student_id = 3
-
从理论上讲,我们利用了事务隔离性,将查询和修改做为一个事务包裹起来. 解决了并发的问题.
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。 -
看起来好像没什么问题了,可仅仅是看起来,真的没有问题么?
三. 下面开始我们的重点内容,涉及的范围可能比较广(没有耐心的同学请慎入!!!)
-
首先我们来看看数据库的事务的四大特性(摘自百度百科)
ACID性质
并非任意的对数据库的操作序列都是数据库事务。数据库事务拥有以下四个特性,习惯上被称之为ACID特性。
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。 [1] -
到这里看起来是没什么问题的,我们利用了事务的原子性将两段sql包裹起来执行,利用了事务的隔离性解决并发问题.没问题,那么我们在具体看看事务的隔离性.
事务的隔离级别及可能出现的问题:
数据库的四个隔离级别除了最后一个串行化之外,其它三个都有可能出现一些对应的问题,当你用@Tranactional声明注解式事务的时候你知道你使用的是对应的哪一个隔离级别么?我们当前要解决的问题需要那个级别呢?一会在说,还是先说一下这些对应的问题都是什么意思吧.
脏写: 脏写是指事务回滚,其它事务对事务项的已提交修改.假设两个事务并发执行,事务一先将student_id = 3的type修改成 1,事务二因为某些原因失败了,需要进行回滚,将student_id = 3 的 type 值 又回滚成 0 .这就是脏写.事务二回滚了事务一的已提交数据.
脏读: 脏读是指一个事务读取了另一个事务未提交的数据.假设两个事务并发执行,事务一要将student_id = 3 的type修改成 1, 但是还没有修改呢.这个时候事务二过来读取student_id = 3 的type值,读取的是 0 ,事务二读取完之后,事务一提交了修改,这就是脏读,事务二读取了事务一的未提交的数据.
不可重复读: 不可重复读是指一个事务对对同一数据的读取结果前后不一致.假设两个事务,事务一先读取了student_id = 3 的type 值等于 0 ,此时事务二对student_id = 3 的type值进行修改并且已经提交,事务一因为业务需要,在事务二提交修改之后再次读取student_3 的 type 的值, 这个时候事务一读取的就是事务二修改之后的值, 造成事务一两次读取的数据不一致,这就是不可重复读.
幻读: 幻读是指事务读取某个范围的数据时,因为其他事务的操作,导致前后两次读取的结果不一致.还是假设两个事务,事务一现在查询class_id = 1001 的学生有几个, 结果是三, 此时,事务二又给class_id这个班增减了一个学生,事务一因为业务需要,再次查询class_id = 1001 的学生人数, 变成4了,这就是幻读.
丢失更新: 丢失更新是指事务覆盖了其它事务对数据的已提交修改,导致这些修改好像丢失了一样.假设两个事务,事务一将student_id = 3 的 type 值 修改成 1 ,并且成功提交了, 此时事务二也对这条数据进行了修改,也提交了, 事务二的提交结果覆盖了事务一的提交结果,事务一的更新就丢失了,这就是丢失更新.
-
@Tranactional 使用的什么隔离级别?
默认使用的是数据库中的默认隔离级别,这个我们后续讨论,
如果不使用默认的隔离级别,我们可以通过配置参数来指定隔离级别.@Tranactional配置参数及意义:
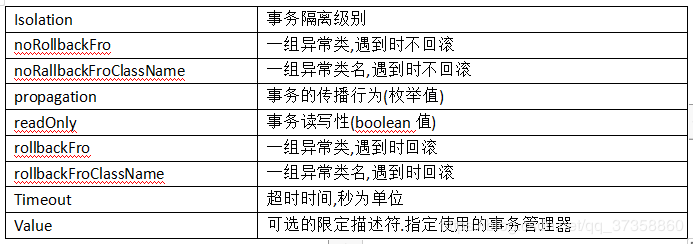
这里我们重点说一下事务隔离级别isolation的几个值,上面表格是我用word写的,输入法问题有的大小写可能不对,需要注意DEFAULT: 使用数据库默认的隔离级别
READ_UNCOMMITTED: 读未提交
READ_COMMITTED: 读已提交
REPEATABLE_READ: 可重复读
SERIALIZABLE: 串行化
/**
* Use the default isolation level of the underlying datastore.
* All other levels correspond to the JDBC isolation levels.
* @see java.sql.Connection
*/
DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
/**
* A constant indicating that dirty reads, non-repeatable reads and phantom reads
* can occur. This level allows a row changed by one transaction to be read by
* another transaction before any changes in that row have been committed
* (a "dirty read"). If any of the changes are rolled back, the second
* transaction will have retrieved an invalid row.
* @see java.sql.Connection#TRANSACTION_READ_UNCOMMITTED
*/
READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
/**
* A constant indicating that dirty reads are prevented; non-repeatable reads
* and phantom reads can occur. This level only prohibits a transaction
* from reading a row with uncommitted changes in it.
* @see java.sql.Connection#TRANSACTION_READ_COMMITTED
*/
READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
/**
* A constant indicating that dirty reads and non-repeatable reads are
* prevented; phantom reads can occur. This level prohibits a transaction
* from reading a row with uncommitted changes in it, and it also prohibits
* the situation where one transaction reads a row, a second transaction
* alters the row, and the first transaction rereads the row, getting
* different values the second time (a "non-repeatable read").
* @see java.sql.Connection#TRANSACTION_REPEATABLE_READ
*/
REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
/**
* A constant indicating that dirty reads, non-repeatable reads and phantom
* reads are prevented. This level includes the prohibitions in
* {@code ISOLATION_REPEATABLE_READ} and further prohibits the situation
* where one transaction reads all rows that satisfy a {@code WHERE}
* condition, a second transaction inserts a row that satisfies that
* {@code WHERE} condition, and the first transaction rereads for the
* same condition, retrieving the additional "phantom" row in the second read.
* @see java.sql.Connection#TRANSACTION_SERIALIZABLE
*/
SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
给出的代码是源码中的枚举类可以自行查看注释
-
别跑偏了,我们知道了默认的隔离级别是什么,也知道了怎么指定隔离级别,那么我们需要什么样的隔离级别呢?
我们现在要解决的问题是先查询,然后在修改,做为一个事务,保证并发,的时候能够正常运行,那么指定串行化的事务隔离级别不就可以了么?没问题,只要隔离级别设置成串行化,那么就什么脏读,幻读,等等什么问题都不用考虑了,万事ok.
那么你知道指定了串行化隔离级别的数据库(本文是以MySQL数据库的InnoDB存储引擎为例)具体是怎么实现的么?首先串行化的隔离级别需要谨慎的使用,他能够保证的是完全隔离,但是并发处理性能可以说是最低的,我们这个业务肯定是不能使用串行化的,然后说默认的隔离级别,默认的隔离级别在这个业务中有可能会造成死锁,所以我们也需要慎重考虑.所以说到这里我们的问题还是没有解决,需要继续深究的问题还很多,比如:
MySQL数据库InnoDB存储引擎的默认隔离级别是什么
MySQL数据库InnoDB存储引擎的各个隔离级别是怎么实现的
乐观锁,悲观锁,共享锁,排他锁,行级锁,表锁,都什么鬼,MVCC版本控制是什么东西,表扫描?索引… -
写本文的目的主要是想体现知识的点,线,面的关系,希望自己能够把书读薄,从任何一个知识点入手,只要你想,你都能够去探索一条知识线,从而得到成体系的知识架构.当你掌握的知识点够多,连成线了,编织成面了,有了自己的知识体系的时候,你才算把说读薄了,你才能够说这个业务两行代码就可以搞定,加个事务就行了,使用乐观锁就行了…而不是你听别人说,使用什么,你也跟着说,或者你做了个简单的测试,然后没问题,你就这样说.做技术,我们要有匠人精神,不但要知其然,更要知其所以然.我愿意用我时间和精力去一点一点探索,向着远方独自前行,未完待续…