笔试总结(五)
1、假设时钟周期为T,寄存器时钟端到数据输出端的延迟为Tcq,时钟到第一级寄存器的时钟端的延迟为Tcd1,时钟到第二级寄存器时钟端的延迟为Tcd2,两级寄存器之间的组合逻辑延迟为Tpd,寄存器的建立时间为Tsetup,Tpd的最大延迟为(D)
A Tpd ≤ T - Tsetup - Tcq -(Tcd2 - Tcd1)
B Tpd ≤ T - Tsetup + Tcq -(Tcd2 - Tcd1)
C Tpd ≤ T - Tsetup + Tcq -(Tcd1 - Tcd2)
D Tpd ≤ T - Tsetup - Tcq -(Tcd1 - Tcd2)
时序分析的方法主要有两种,一种是静态时序分析,另一种是动态时序分析。静态时序分析是通过设计好电路中的已知参数,利用EDA工具提高的模型分析出时钟和数据的关系。而动态时序分析是把设计好电路中的所有延时都考虑进来,在EDA仿真工具中把延时参数都加上,然后观察仿真的波形并测量Ts(建立时间:采样时钟的上升沿到达数据的起始位置的时间),Th(保持时间:采样时钟上升沿到达数据结束位的时间)是否满足时序的要求,需要电路模拟跑起来。
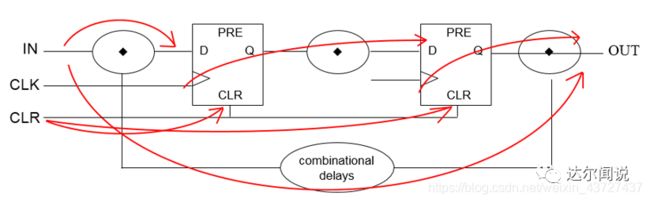
如上图所示分析需要关心路径有以下几点:
(1)、从输入到输出的路径
(2)、从输入到寄存器的路径
(3)、从寄存器到输出的路径
(4)、从寄存器到寄存器的路径
(5)、异步清零信号和时钟存在异步的进入和退出的时序问题
**时序问题是如何引入的?**以寄存器到寄存器之间的路径分析为例,如下图所示,时钟的上升沿在寄存器REG1的时钟端和数据稳定在寄存器REG1的D端在图中蓝色竖线的位置是同时进行的,但数据要从图中①所示的数据路径到寄存器REG2的D端,而时钟则从图中③所示的路径到寄存器REG2的时钟端 ,也就是说数据和时钟所经过的路径是不同的,这会使得数据和时钟到达寄存器REG2的D端和时钟端的相位关系发生变化,在某些情况下会导致刚好如下图建立时间违例和保持时间违例所示的情况,即时钟在数据不稳定的情况下对数据进行了违例,这会导致我们采集到的数据是错误的。做约束的目的就是要解决这些问题,让时钟采集到稳定的数据。
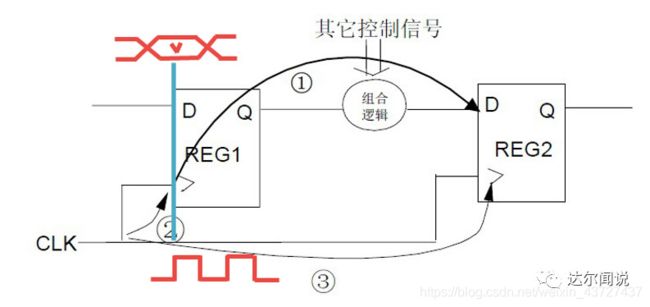
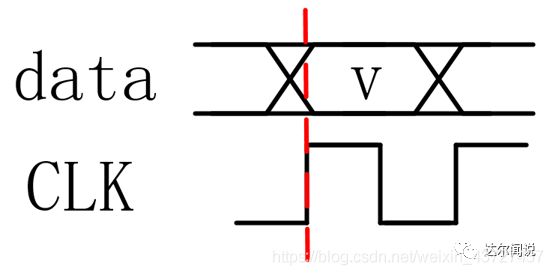
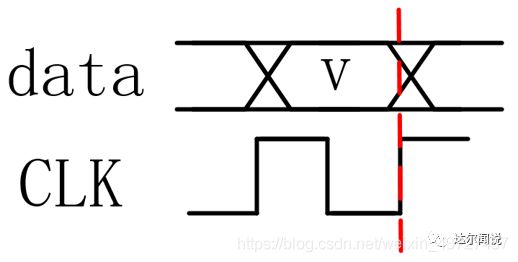

上图中T1为数据路径的延迟,等于上图中①所示的路径,它包括寄存器REG1时钟端到寄存器REG1数据输出端Q的延迟为Tco与两级存器之间的组合逻辑与布线延迟Tdata之和。
上图中△T为时钟偏移,等于上图时钟到第二级寄存器时钟端的延迟T③与时钟到第一级寄存器REG1的时钟端的延迟T②之差。
上图中Ts为建立时间,Th为保持时间,Tcycle为时钟周期
建立时间公式为:Ts = T_cycle - T1 + △T = T_cycle - (Tco + Tdata) + △T
保持时间公式为: T1 - △T = (Tco + Tdata) - △T
T_setup:时钟沿来到之前数据必须保持稳定的最小时间,芯片选定即决定,和制作工艺有关。
T_hold:时钟沿来到之后数据必须保持稳定的最小时间,芯片选定即决定,和制作工艺有关。
Sslack(建立时间的余量)≥ 0
= Ts – T_setup ≥ 0
= [T_cycle –(Tco + Tdata)+ △T] – T_setup ≥ 0
Hslack(保持时间的余量)≥ 0
= Th – T_hold ≥ 0
= [(Tco + Tdata)–△T] – T_hold ≥ 0
下面这种模型是Quartus和Vivado中的时序分析工具常用的模型,我们需要新引入一个概念,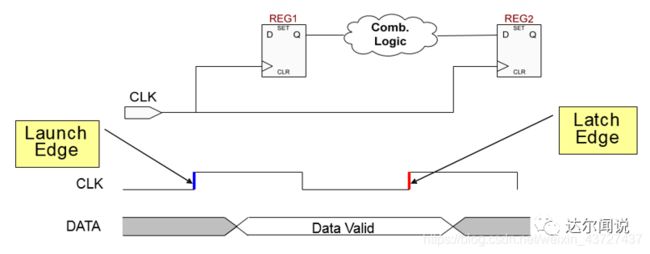
(1)Launch Edge(发射沿):管脚传进来同步于数据的时钟的沿,也被认为是0时刻。
(2)Latch Edge(锁存沿):目的地寄存器REG2锁存数据的沿,相对于发射沿延后1个时钟周期后的起始位置。
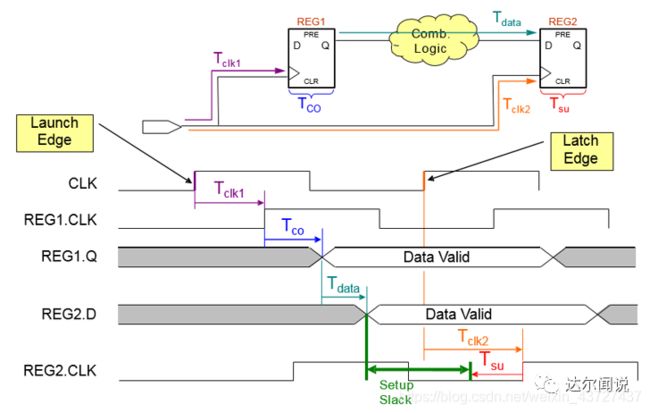
我们引入数据到达寄存器的时间Data Arrival Time,就是说数据从Launch Edge开始到寄存器REG2的D端所用的时间: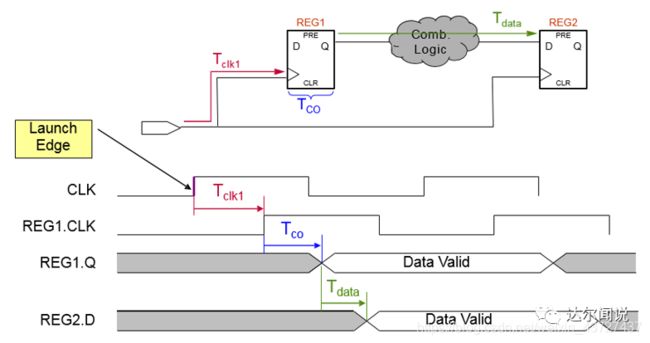
(1)建立时间的Data Arrival Time(当前数据开始到达的时间) = launch edge + Tclk1 + Tco + Tdata
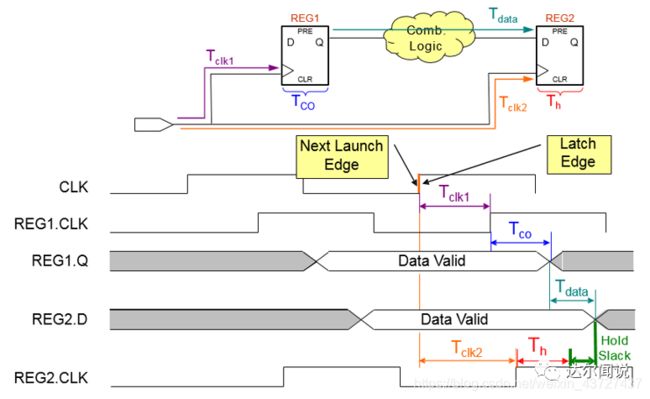
(2)保持时间的Data Arrival Time(当前数据结束到达时间,也就是下一个数据开始到达的时间) = next launch edge + Tclk1 + Tco + Tdata
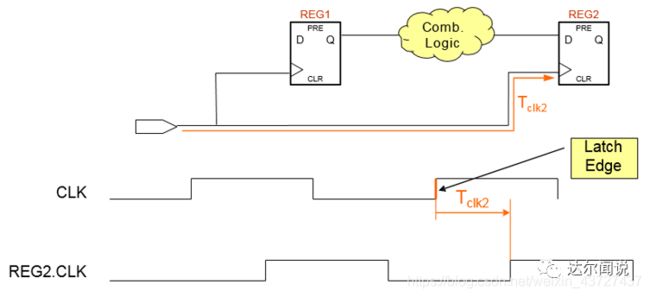
下图是采样时钟到达的时间clock Arrival Time,也就是说时钟从latch edge到寄存器REG2的时钟端所用的时间:
clock arrival time = latch edge + Tclk2
下图是建立时间数据要求到达的时间Data Required Time ,就是说要满足建立时间数据必须在此之前到达寄存器REG2的D端:
Data Required time = clock arrival time -Tsu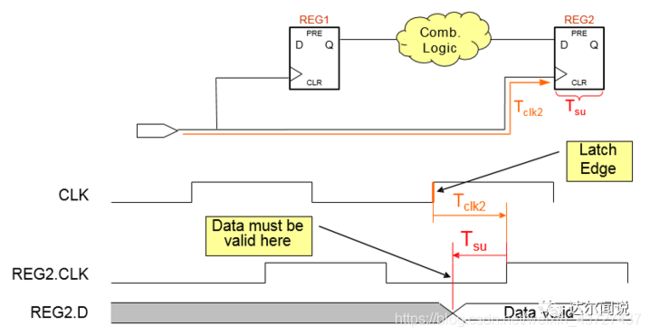
下图是保持时间数据要求达到的时间Data Required Time,就是说要满足保持时间数据必须要在此之后到达寄存器REG2的D端:Data Required Time = Clock Arrival Time + Th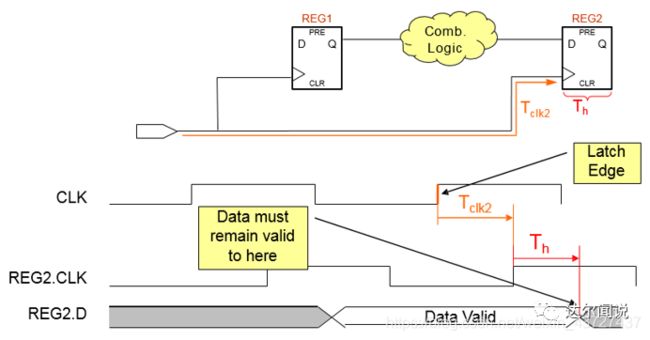
建立时间余量(Sslack),用数据要求到达的时间减去数据实际到达的时间,公式推导为:
Sslack(建立时间余量) ≥ 0
=Data Required Time - Data Arrival Time ≥ 0
=(clock Arrival Time - Tsu) - (launch edge + Tclk1 + Tco + Tdata)≥ 0
=(latch edge + Tclk2 - Tsu) - (launch edge + Tclk1 + Tco + Tata) ≥ 0
Hslack(保持时间的余量)为数据实际到达的时间减去数据要求到达的时间,公式推导为:
Hslack(保持时间的余量)≥0
= data Arrival Time - data required time ≥ 0
=(next launch edge + Tclk1 + Tco + Tdata) - (clock arrival time) ≥ 0
=(next launch edge + Tclk1 + Tco + Tdata) - (latch edge + Tclk2 + Th) ≥ 0
时序分析工具中的模型推导的公式进行化简:
(1)Sslack(建立时间的余量)≥0
= data Required Time - data arrival time ≥ 0
=(clock arrival time - Tsu) - (launch edge + Tclk1 + Tco + Tdata) ≥ 0
=(latch edge + Tclk2 - Tsu) - (launch edge + Tclk1 + Tco + Tdata) ≥ 0
= latch edge + Tclk2 - Tsu -launch edge - Tclk1 - Tco - Tdata ≥0
=(latch edge - launch edge) - (Tco + Tdata) + (Tclk2 - Tclk1) - Tsu ≥ 0
=[T_cycle - (Tco + Tdata) + △T] - Tsu ≥ 0
(2)Hslack(保持时间的余量))≥ 0
= Data Arrival Time–Data Required Time ≥ 0
=(next launch edge + Tclk1 + Tco + Tdata)–(Clock Arrival Time + Th)≥ 0
=(next launch edge + Tclk1 + Tco + Tdata)–(latch edge + Tclk2 + Th)≥ 0
= next launch edge + Tclk1 + Tco + Tdata–latch edge-Tclk2-Th ≥ 0
=(next launch edge–latch edge)+(Tco + Tdata)+(Tclk1-Tclk2)-Th ≥ 0
=[(Tco + Tdata)-△T] - Th ≥ 0
2、以下是对cache-主存-辅存三级存储系统中各级存储器的作用,速度、容量的描述,其中完全正确的是(B)
A主存用于存放CPU正在执行的程序,速度慢,容量极大
Bcache用于存放cpu当前访问频繁的程序和数据,速度快,容量小
C加大cache的容量可以使主存储能够存放更多的程序和数据
D辅存用存放需要联机保存但暂不执行的程序和数据,速度快,容量大
当前计算机一般都采用高速缓存-主存-辅存三级存储结构。高速缓存也称为cache,它位于cpu与主存之间的一种高速存储器,cache分为片内cache和片外cache,片内cache速度已接近cpu的速度,cache由SRAM组成,存储量最小,速度最快。
常用有一级缓存(L1)、二级缓存(L2)、三级缓存(L3)。设置cache的目的在于将当前程序运行中快速使用的一组数据或即将执行的一组指令由主存复制到cache中,使cpu可以从cache中快速地获取所需要的指令和数据,当CPU访问存储器,首先检查cache,如果要访问的信息已经在Cache中则CPU可以快速地获取信息,若不在,CPU必须访问主存,同时把包含所访可的信息的数块复制到Cache中更新,即Cache用来改善主存与CPU的速度匹配回题。
所以主存是电脑中主要部件,是CPU能直接寻址的存储空间,计算机中的主存储器主要由存储体、控制线路、地址寄存器、数据寄存器和地址译码电路五部分组成,它与辅助存储器相比有容量小、读写速度快;与Cache相比容量大、读写速度慢,所以总的来说容量适中,速度适中,所以A选项错误。主存一般采用半导体存储单元,包括随机存储器(RAM)、只读存储器(ROM)。
辅存为外部存储器,如硬盘、U盘、光盘等,它不能直接被CPU直接访问,一般用于存放暂时不用或主存放不下的程序和数据。当CPU处理信息时,首先查看所需要的数据是否在内存,若已经在则直接访问,此时称Cache命中。若不在,由辅助软硬件将有关信息从辅存上分段或分页调入内存,再由CPU访问。辅助存储器用于扩大存储空间
Cache-主存和主存-辅存的相同点:都是在CPU的控制下进行信息交换Cache-主存和主-存辅存的不同点:前者是主机内部进行信息交换;后者是主机与外部设备之间进行信息交换。
3、信号无失真传输的条件是:(B)
A相位特性是一通过原点的直线
B幅频特性等于常数,相位特性是一通过原点的直线
C幅频特性是一通过原点的直线,相位特性等于常数
D幅频特性等于常数
无失真传输是指只有幅度的大小与出现的时间先后不同,波形上没有变化的系统的输出信号或输入信号。
失真传输是主要传输特性通常可以用其幅频曲线和相频曲线来描述。无失真传输要求振幅特性与频率无关,即其振幅频率特性曲线是一条直线;要求其相位特性是一条通过原点的直线,或者等效地要求其传输群时延与频率无关。
2、主机与设备传输数据时,采用哪种方式CPU的效率最高(B)
A中断方式
BDMA方式
C软件查询方式
D程序查询方式
中断方式:检查条件不占CPU时间,当满足条件时,就会进入中断子程序,这时CPU就要进行中断处理,所以处理需占CPU时间。
DMA(Direct Memory Access)是一种不经过CPU而直接与数据交换的数据模式。在DMA方式下,CPU只需向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样很大程度上减轻了CPU资源占用率。比如在一些示波器中,瞬时要处理很多数据,这时就会采用DMA的方式进行数据传输。
**程序查询方式:**程序直接控制方式,这是主机与外设间进行信息交换的最简单方式,输入和输出完全是通过CPU执行程序来完成的,也是需要占用CPU时间。
建立时间(Setup Time):触发器的时钟信号上升沿到来之前,数据保持稳定不变的时间。
保持时间(Hold Time):触发器的时钟信号有效沿到来之后,数据保持稳定不变的时间
3、以下哪些方式可以减少PCB表层相邻信号间串扰影响(ABC)
A 信号线上传输信号的上升时间变快
B 将表层相邻走线改成内层相邻走线
C 减少相邻信号线耦合长度
D减少相邻信号线间距
串扰是因为相邻两条信号线之间因为有较长的平行布线,会有耦合、信号线之间的互感和互容,这样会引起信号线上的噪声。串扰是电磁干扰传播的主要途径。异步信号线、控制线、和I/O口走线上,严重时它会使电路或元件出现功能不正常的现象。
串扰在高速高密度的PCB设计中普遍存在,串扰对系统的影响一般是负面的。为减少串扰,最基本的就是让干扰源网络与被干扰源网络之间的耦合越小越好。在高密度复杂PCB设计中完全避免串扰是不可能的,但在系统设计中设计者应该在考虑不影响系统其它行呢的情况下,选择适当的方法来力求串扰的最小化。
解决串扰问题主要从以下几个方面考虑:
(1)、在布线条件允许的条件下,尽可能拉大传输线间的距离;或者尽可能减少相邻传输线间的平行长度(累积平行长度),最好是在不同层间走线。
(2)、相邻两层的信号层(无平面层隔离)走线方向应该垂直,尽量避免平行走线以减少层间的串扰。
(3)、在确保信号时序的情况下,尽可能选择转换速度低的器件,使电场与磁场的变化速率变慢,从而降低串扰。
(4)、在设计层叠时,在满足特征阻抗的条件下,应使得布线层与参考平面(电源或地平面)间的介质层尽可能的薄,因而加大了传输线与参考平面间的耦合,减少相邻传输线的耦合。
(5)、由于表层只有一个参考平面,表层布线的电场耦合比中间层的要强,因而串扰较敏感的信号应该尽量布在内层。
(6)、通过端接,使传输线的远端和近端终端阻抗与传输线匹配,可大大减少串扰的幅度。信号上升时间对信号完整性的影响很大。有实验表明,上升沿的串扰的影响相当大,随着上升的时间变短,特别是当平行线走线长度小于饱和长度时,串扰电压幅度将迅速减小。
4、对于高速逻辑电平应用,下面说法正确的有(ABD)
A TTL与CMOS电平不适合高速应用的原因,一方面电平幅度较大,信号边沿变化所需的时间较长,不适合高速信号应用;另一方面传输路径上易受到干扰,不利于远距离传输。
B LVDS-LVDS逻辑电平互联的直流耦合方式比较简单,仅需要在接收端使用100欧姆电阻实现短接即可。
C 高速逻辑电平采用交流耦合方式进行互联时,无需考虑输入端共模偏置电平的要求
D 差分对内两信号走线等长,该要求是基于时序和共模噪声的要求而提出的。
TTL(晶体管-晶体管逻辑)属于双极性逻辑门,速度快,抗干扰能力和带负载能力强。功耗较大,集成度低,不适合做成大规模集成电路,主要有54/74系列标准TTL、高速型TTL(H-TTL)、低功耗型TTL(L-TTL)、肖特基型TTL(S-TTL)、低功耗肖特基型TTL(LS-TTL)五个系列。
TTL电路的传输速度快,传输延迟时间短(5-10ns);COMS电路的速度慢,传输延迟时间长(25-50ns)。
CMOS逻辑门属于单极性逻辑门,CMOS电路具有制造工艺简单,功耗小,集成度高,无电荷存储效应等优点。与TTL电平相比,CMOS的逻辑电平范围较大,而TTL只能工作在5v一下。
LVDS是一种低压、差分信号传输方案,主要用于高速数据传输。
LVDS信号传输一般由三部分组成:差分信号发生器,差分信号互联器,差分信号接收器。
差分信号发生器:将非平衡传输的TTL信号转换成平衡传输的LVDS信号。
差分信号接收器:将平衡传输的LVDS信号转换成非平衡传输的TTL信号。
差分信号互联器: 包括连接线(电缆,PCB走线),终端匹配阻抗。
直流耦合(DC Coupling)方式,就是直通,交流直流一起过。由于在接收器的输入端相对于接收器的地是共模电压。这个共模范围是+0.2V+2.2V。即直流偏置电压要求不高:+0.2V+2.2V都可以。所以,可以直接使用源端的直流偏置电压,即无论是高速低速、板间、板内,最好都使用直流耦合方式。但是当干扰很大的板间,直流偏置不在范围内的则采用交流耦合。
交流耦合方式(AC Coupling),即隔直流,通交流。线路上需要耦合电容,匹配电阻,还需要加直流偏置电压──V_BIAS,若芯片内部不提供直流偏置的话要在外面接成这个样子,而不能只是简单的匹配电阻了。
差分信号和普通的单端信号走线相比,最明显的优势体现在以下三个方面:
a:抗干扰能力强。因为两根差分走线之间的耦合很好,当外界存在噪声干扰时,几乎是同时被耦合到两条线上,而接收端关心的只是两信号的差值,所以外界的共模噪声可以被完全抵消。
b:能有效抑制EMI。同样的道理,由于两根信号的极性相反,它们对外辐射的电磁场可以相互抵消,耦合的越紧密,泄放到外界的电磁能量越少。
c:时序定位精确。由于差分信号的开关变化是位于两个信号的交点,而不像普通单端信号依靠高低两个阈值电压判断,因而受工艺、温度的影响小,能降低时序上的误差,同时也更适合于低幅度信号的电路。目前流行的LVDS(low voltage differential signaling)就是指这种小振幅差分信号技术。