ConcurrentHashMap 无锁读
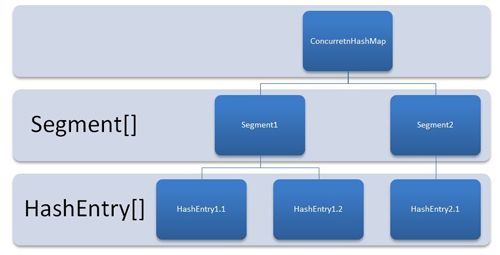
ConcurrentHashMap 可以做到无锁读,而写使用分段锁机制,把整个哈希表切分成段segment(默认为16段),每段有一个锁,最多可以同时有16个写线程。而读不受限制。
下文转自http://taozeyu.com
ConcurrentHashMap是一个线程安全的哈希实现类,它不但能使多线程同时操作该类时保证线程是安全的,同时为了保证对Map的读操作的高效,完全不使用同步锁。
实现单线程,或简单通过加锁来实现线程安全的一个哈希表所用到的数据结构知识是很普通的,但如果不加锁,也能保证线程安全,则需要用到一些“奇技淫巧”了。
编写JDK的程序员正是这么一些掌握了这种“奇技淫巧”的人。,而ConcurrentHashMap类正是运用了这些技巧的一个实现类。本文将用图片的形式,展现这些技巧。毕竟源代码的阅读是枯燥的。
Java如何实现HashMap
Java规定只有对象才能作为哈希表的Key或Value,这意味着基本数据类型只能存它们的封装对象。一切Java对象都继承自Object,而Object有两个与HashMap紧密相关的方法:
int hashCode()
boolean equals(Object o)
哈希表通过Key对象的hashCode()获取该Key的哈希索引,再通过哈希函数将索引映射到哈希表的某个偏移地址。哈希索引和它经过哈希函数处理后的结果是一个多对一的关系。即同一个哈希索引只可能映射到唯一一个偏移地址上,但同一个偏移地址可能映射到多个哈希索引。
如果多个Key对象被映射到同一个偏移地址(哈希表的设计应该尽量避免这种情况,但有必须对这种情况进行必要的处理) ,称之为冲突。Java解决冲突的方法是拉链法。即多个节点通过链表的形式,占用同一个偏移地址。最终结果可能是这个样子。
当哈希表需要将一个输入的Key对象映射到特定的节点上时,会以如下方式进行映射:
- 通过Key对象的hashCode()方法获取哈希索引。
- 用哈希函数算出索引对应的偏移地址。ava实现的哈希函数很简单,令哈希索引除以数组长度,取余数即为偏移地址。
但Java不是简单的取余,它令数组的长度永远是2的整次幂,并以下列式子计算偏移地址。这种算法等价于取余,但效率更高。
hashCode & (hashTable.length-1) - 在数组中查看偏移地址信息,如果为空,则没有找到。否则则找到一条链表。
- 遍历这条链表,对于链表每一个节点记录的Key对象调用equals方法尝试是否与输入的Key对象相等。
- 如果找到,则停止遍历。如果遍历完链表尚未找到,则宣布没有找到。
由此可见,一切存入HashMap中的Key对象,如果想要重写hashCode与equals方法中的任意一个,则必须两个都配套重写。任何企图只重写其中一个方法,或使两个方法不匹配的,都会令程序产生不可预料的结果。
ConcurrentHashMap的实现
但凡单线程的哈希表实现都是很简单的,其知识无外乎《数据结构》中那些要领。但要实现无锁的线程安全的哈希表,则需要一些“巧力”了。让我们看看JDK的程序员是如何做的吧。
ConcurrentHashMap 对于所有的读操作,都不加锁。它仅仅对写操作加锁。这意味着仅仅写操作是互斥的,而读操作则完全不可预测。
首先让我们来看看HashMap中的节点,Entry对象。严格的Entry泛型定义应该是Entry
在 ConcurrentHashMap中,写入的Entry通过无比巧妙的方式,保证了随时可能进行的读操作的安全。我将一一介绍它们的具体实现,并配上图片。
我在配图的时候将用颜色区分不同的节点:
绿色:一切线程都可以看到的对象,因此这些对象必须假定它随时都被访问。
红色:写入线程独占的对象,只有写入线程可见,对于其他任何线程都是透明的。(由于写入线程持有了锁,因此实际上只有一个线程可以访问到这些对象。)
蓝色:即将回收的对象。这些对象可能可见,但是很快随着方法的返回,这些对象将最终变得不可达,而被垃圾回收期搜集处理掉。
(1)put方法
put方法如果发生在Key已存在的情况下,则仅仅是定位Entry,并将它的Value替换成新的。这种情况下完全不需要加锁,且能保证线程安全。因此,我不打算讨论这种情况。我要讨论的是当put发生在Key不存在的情况下的实现。
这种情况下,写入线程首先将找到偏移地址,并遍历整个链表,但发现链表中没有一个Key是可以匹配的,因此线程必须建立一个新的节点。
这种技巧的关键在于,在最后一步完成前,写入线程做造成的影响全部都是“红色”的,即外界不可见的。如果你忽视掉“红色”的方块,则会发现绿色的方块在整个过程中都没有发生任何改变。正是这个特征保证了线程的安全。
(2)remove方法
写入线程首先,找到需要删除的节点。再将需要删除的节点所在链表的前趋全部复制一遍,但直接前趋的Next是指向需要删除节点的后继的。最后,将复制的前趋替换掉之前的前趋。
这种做法等于将待删节点,以及它的前趋的全部前趋都删除掉了(因为变得不可达了),但却为其前趋做了副本,因此真正被删除掉的只有待删节点本身而已。
注意第三部中蓝色的方块,此时如果有线程正在遍历蓝色的方块,对于这条线程而言完全读到任何差异。线程依然是安全的。蓝色的方块只有当所有的线程都不再依赖的时候才会被垃圾回收期搜集。
(3)哈希扩容
哈希表极力降低冲突的概率,因此当哈希表容纳的Entry过多时,会自动扩容。 哈希的扩容后的容量一定为原来的两倍,因此只要哈希表的初始容量是2的整次幂(实际上就是如此),那么哈希表容量一直是2的整次幂。
ConcurrentHashMap使用了一种巧妙的方法,令哈希表即便是在扩容期间,也能保证无锁的读。
第一步将分配新的table,长度为原来的2倍。在遍历原table的每一项,并对链表进行操作(此处将只演示对某一条链表的操作)。首先取出链表最某段的连续的一组节点,此组节点的hashCode在新table中对应的偏移位置(Index)是相同的。
(注:原来一个桶的Entry只可能被重新哈希到两个位置)
再令新table中对应的偏移地址处指向之前选取组的首节点。
将该组节点的前趋全部复制,并各自通过哈希函数计算其在新table中的位置,并插入到该位置上。
这一步仅仅改变指向table的指针,导致原来的旧table以及被复制节点的本体变得不可达了。这些节点最终将被垃圾回收器回收。整个扩容过程即便耗时很长,但对于其他线程都是透明的。
http://taozeyu.com/software/2014/03/14/concurrent-hash-source-code-analyze.html