大家好,我是赵洋。我是DataStax数据库团队的软件工程师。我主要关注的方向包括索引、Streaming和物化视图。今天很高兴可以和大家分享Materialized View物化视图的设计和实现。我会主要讨论为什么要用物化视图、物化视图的更新、一致性以及使用物化视图的注意事项。

我们都知道,Cassandra是一种非关系型数据库,即NoSQL数据库。它与关系型数据库不同,所以我们不能用关系型数据库的方式来建表。在Cassandra数据库中如果建表不合理,很可能导致表的性能下降,甚至失去伸缩性。所以我们在Cassandra数据库中一般使用denormalization(反范式)的方式建模。也就是说,我们会根据我们的读请求来建表,即使是在不同的表之间会导致数据冗余(duplication)。
比如在PPT中,我们有一个user表。其中user_id是它的主键,除此之外也包含一些其它信息,即名字name和年龄age。然而有些业务可能需要根据用户姓名来查询用户信息,但是用户姓名name并不是user表的主键,所以我们需要新建一个user_by_name表并将名字name变成这个表的主键的一部分。当创建新用户时,我们会在客户端分别向两个表插入数据记录,之后根据业务需求再从不同的表读取数据。这样可以保证低延迟和集群的伸缩性。
但是这种解决方案存在一个问题:当我们需要更改用户信息的时候,我们需要维护多个表。比如你要更改年龄,你需要从user表中读取某一个user的age,之后再到user_by_name表中更新相应的数据。其实这样的情况下,用户已经在客户端实现了类似于物化视图的功能。既然如此,我们完全可以把这种功能在数据库中实现,从而提高性能和一致性。
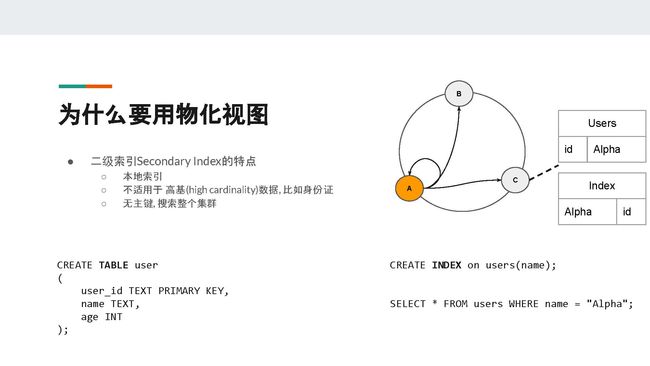
讲到这里,可能有人会问,为什么不用二级索引?
二级索引是Cassandra中的一个不错的功能,但是也有其局限性。二级索引(或称为“本地索引”)的数据和基表数据存储在同一个节点。通过下面的例子,我们将更好地说明二级索引的局限性。
在PPT中,我们在users表上选取name这个字段创建一个二级索引。当用户想要查询name = "Alpha"时,因为name并非分区键partition key,所以集群的协调者coordinator(即点A)并不知道哪个节点存有相关数据。在最坏的情况下,点A可能需要联系集群中的所有节点从而保证找到name = "Alpha"这条数据。
所以二级索引并不适用于高基(high cardinality)数据,比如身份证等。因为像是身份证这类数据,一般只存在于集群中一两个非常少的节点上面。这样会导致读的性能很低,速度也很慢,继而导致高延迟。集群的节点数量越大,这种读请求就会越慢。
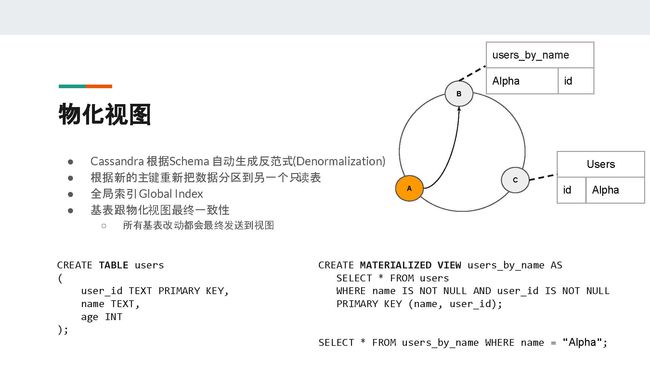
简单来说,物化视图就是把原本的数据根据新的分区键重新分到不同的表,然后由服务端(server)维护视图的更新。故此,物化视图有另外一个名字,叫做global index(全局索引)。对于客户端(client)来说,物化视图就像是一个只可以读的表。这个表的数据插入是根据基表的更新来维护的。
在PPT中提到的例子里,我们用name这个字段来创建一个物化视图,然后把name这个字段作为物化视图的主键。这样一来,这个物化视图的数据就会根据name这个字段重新分区。当客户端搜索name = "Alpha"时,作为协调者(coordinator)的节点A可以根据一致性哈希算法直接知道节点B存有值为Alpha的主键的信息。
从上面的例子中,我们可以看到物化视图是可以保证集群的伸缩性以及读请求的低延迟。因为不管集群有多少节点,协调者只需联系固定数量的副本来满足读请求。Cassandra物化视图的设计中,最重要的特点就是基表跟物化视图的最终一致性。在我们的例子中,所有对基表user的改动,最终都会被应用到它的物化视图users_by_name中。
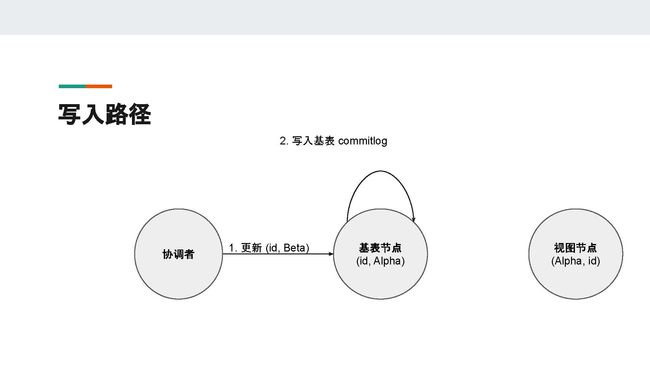
为了实现这个目标,Cassandra做了很多设计和取舍。为了更清楚地解释这些,我们先了解一下物化视图的写入路径。
为了说明清楚,我们先假设集群只有一个数据副本。和普通的写入一样,协调者收到客户端的请求之后会用一致性哈希算法,根据请求中的分区键找到相应的基表节点。
在图中,id是分区键,它对应的基表节点是右边的这个节点。到这时,协调者把客户端的请求转发到基表节点。在基表节点收到协调者的请求之后,基表节点不能马上更新它的本地数据,因为基表节点的本地数据可能有对应的、存在另一个节点(即图中的视图节点)上的物化视图数据。
现有的基表节点有一条数据,它的主键是id,name字段的值为Alpha。而在视图节点,有一条数据,它的主键是name字段,值为Alpha,另外还有一个值为id的user_id字段。所以当我们更新基表节点中user_id = id这条记录的name字段,将它从Alpha变成Beta时,基表节点需要读出现有的数据,然后对物化视图进行相应的维护。
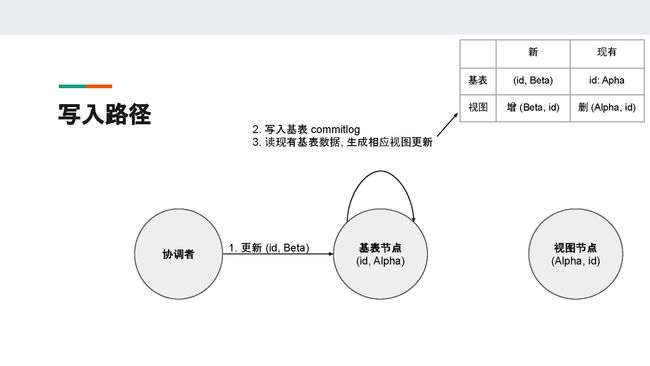
所以基表节点收到更新之后,它会把已有的数据先读取出来,然后将之与更新的数据进行比较。这时,基表节点会发现它需要删除已有的name = Alpha的视图数据,再新增一条name = Beta的视图数据。
但是又因为Cassandra是无主架构,所以我们必须考虑并发写入的情况。假设此时有另一个协调者(coordinator)将name这个字段更新为Delta,在没有并发控制的情况下,很可能这两个更新都会读到基表节点现有的数据name = Alpha,然后生成不一样的视图主键name = Beta和name = Delta。
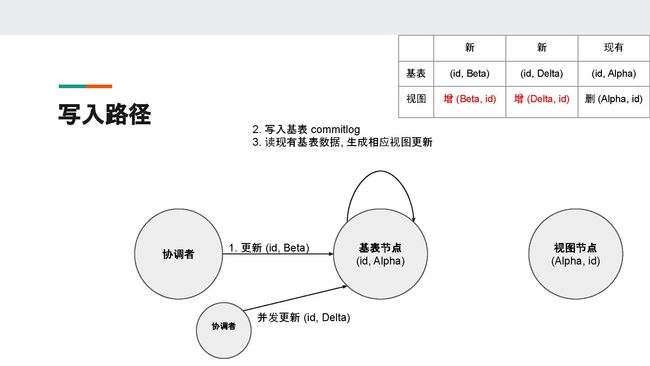
对于基表来说,在并发操作完成后,基表根据时间戳来判定谁是最新的数据,然后只会留下最新的数据。然而对于物化视图来说,由于name是主键,就可能同时留下两条数据,并且它们很有可能储存在不同的视图节点。
所以我们必须加一个锁,来保证基表节点的更新是序列化的。在读取基表数据之前,我们必须先获取分区锁(partition lock),这样可以避免刚才所说的并发更新的情况。
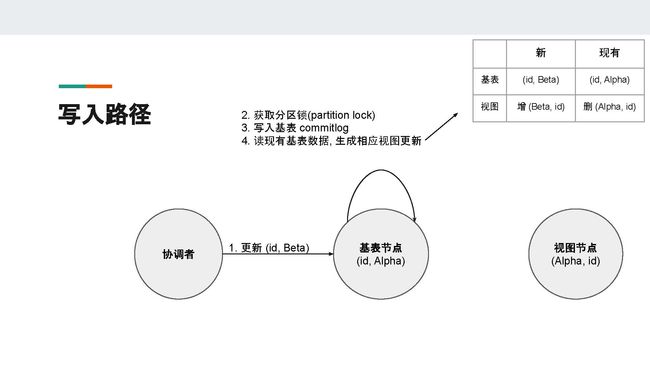
在基表节点获取了数据更新之后,我们有两种更新视图节点的选择。
一种是常见的同步更新,即基表节点同步发送request到视图节点,然后等待至视图节点更新完毕。此种方式的弊端在于视图节点的可用性会直接影响到基表节点的可用性。假设一个基表有很多物化视图,很有可能任意少数视图节点的超时或宕机就会影响到当前基表的写入。
所以Cassandra采用的是另一种更新视图节点的方式——异步更新。基表节点会先把视图更新写到本地的batchlog,然后基表节点会进行异步的视图更新,即发送异步的request给相应的视图节点。如果异步更新成功,基表节点就会删除本地的batchlog;如果异步更新失败,基表节点默认在10秒钟之后重新尝试根据本地的batchlog更新视图,从而保证视图的一致性。
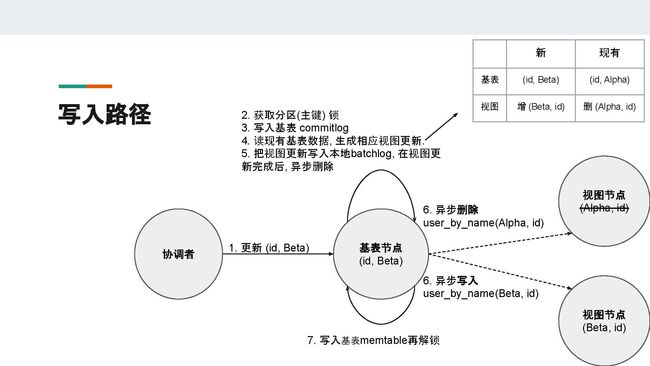
所以,batchlog使得在视图节点超时或宕机时,视图的数据还能保证最终一致性。
异步更新完成后,基表节点就会把基表数据的改动写入基表的memtable,然后再解锁,之后再返回客户端。
但是我们要注意,因为视图的更新是异步完成的,所以很有可能当基表的写请求完成并返回客户端之后,视图的数据还没有更新完成。也就是说,物化视图不能提供read-your-write(读你所写)的保证。
以上就是单副本情况下Cassandra利用分区(主键)锁以及读后写和batchlog来保证视图节点最终一致性的设计方案。
接下来,我们来看看在多副本的情况下,Cassandra是如何处理写请求的。

当集群有多个副本时,每个分区键会对应多个节点。在图中,id分区对应的是基表节点1、2、3,Alpha分区对应的是视图节点1、2、3。为了减少更新视图的开销,Cassandra会把每个基表节点和对应的视图节点进行一对一配对,基表节点只会更新和它配对的视图节点。
这个配对的算法很简单,就是计算每个节点在token ring上面的序号,序号相同的节点就会被配对。图中,基表节点1与视图节点1配对,基表节点2与视图节点2配对,以此类推。如果基表节点同时也是视图节点,它会优先与自己配对,从而达到提高性能的目的。
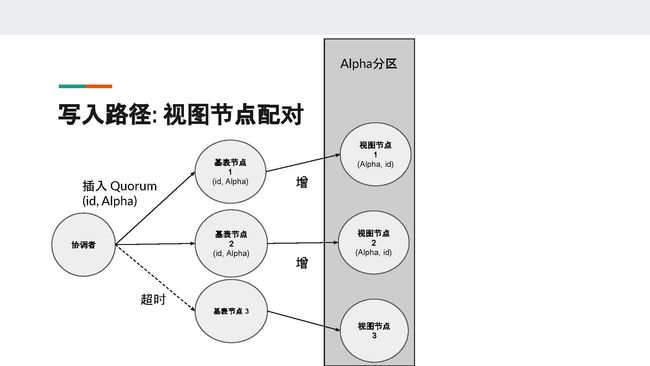
接下来,我们来看看3副本时用Quorum写入副本的情况。
假设一开始,我们什么数据都没有。接着,客户端插入user_id = id, name = "Alpha" 这样的一条记录。假设基表节点1和2收到了这个请求,然后他们会生成相应的物化视图数据,即基表节点1会生成(Alpha, id)并将其发送至视图节点1,基表节点2会生成(Alpha, id)并将其发送至视图节点2(勘误:ppt中视图节点2不应该划掉(Alpha, id))。
基表节点3由于宕机或超时等因素,并没有收到写入请求。由于我们一共有3个副本,只要有2个写成功就满足Quorum的条件,所以即使基表节点3没有写入,此时也可以返回客户端报告成功。
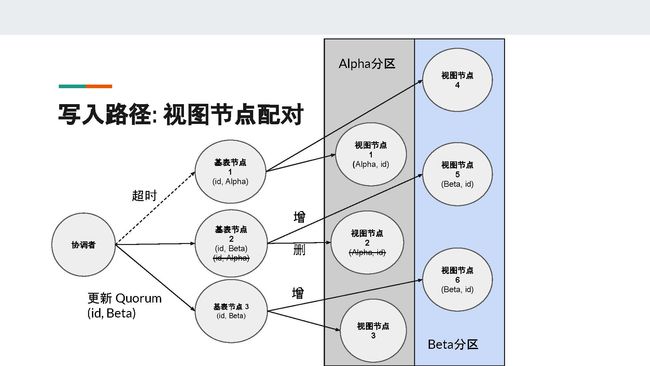
接下来,我们来看看客户端更新将name字段从Alpha改成Beta的过程。这一次,协调者联系到的是与刚才写入时不同的节点,即节点2和3。由于节点2已有旧数据(id, Alpha),所以它需要维护视图数据的更新。节点2需要把旧的(Alpha, id)这条数据删掉,并把新数据(Beta, id)更新到视图节点5。对于基表节点3来说,因为它没有本地数据,所以在它接收到更新之后它会直接创立一个新的视图数据(Beta, id)到视图节点6。
此时,如果我们用Quorum的标准去读数据,在基表节点搜索user_id = id。不论是从哪两个节点返回数据,我们都能得到最新的记录name = Beta。如果我们用Quorum的标准,输入name = Beta搜索物化视图,我们也肯定能得到最新的数据,因为三个节点中的两个已经被修改成功。但是,如果我们用name = Alpha搜索物化视图,就会出现不同的情况。
在这种情况下,假设协调者联系到的是节点1和节点3,由于节点1只有(Alpha, id);节点2有(Alpha, id)这条数据的墓碑;节点3什么都没有,所以协调者就会返回过时数据(Alpha, id)给客户端。(Alpha, id)这个数据其实应该是已经被删除掉的。

这是Cassandra倒排索引的一个通病,这个问题不仅仅发生在物化视图,同时也发生在二级索引(secondary index)。
上个月(2020年6月)Cassandra ticket 8272刚刚修复了二级索引读到过时数据的问题。它的解决方案叫做“二次读”,也就是协调者在读到可能的过时数据时,会再次读基表数据以保证不会返回过时数据给客户端。但是这个二次读方案也导致了非常高的读延迟。
所以在Cassandra materialized view物化视图中,我们可以采用一些不同的设计方案。
因为物化视图本身是为了优化读的性能,所以我们可以考虑由基表节点广播某个视图的墓碑给多个视图节点,而非前面所说的一对一更新。这样就可以保证协调者不会读到过时数据,同时也不会影响读的性能。
另外需要及时修复基表数据,跑repair tool。这也是Cassandra中的物化视图并不能保证读你所写(read-your-write)的另一个例子。
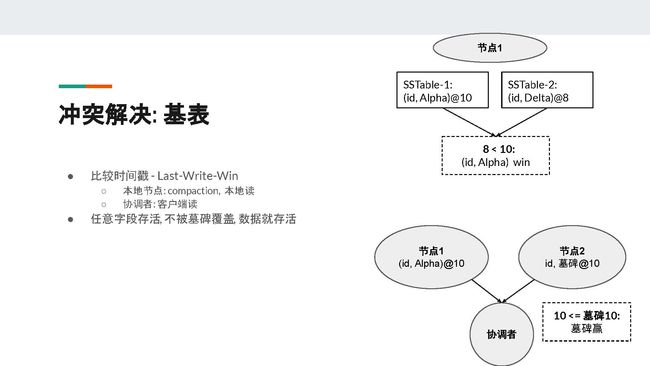
对于一般的表,它的冲突解决方案非常简单,即比较插入的时间戳,最新的数据就会胜出(last-write-win)。
一般来说,冲突解决会发生在两个地方。一是当本地节点有compaction和本地读时,二是当协调者有客户端读时要联系不同节点并把最新数据返回给客户端。所以Cassandra的冲突解决的语义(Semantics)就是:只要数据里面有任意一个字段存活,不被墓碑覆盖,这条数据就能存活。
在PPT中我们可以看到两个例子。
上面的图中,对于节点1有compaction发生,在SSTable-1中有(id, Alpha),它的时间戳是10;在SSTable-2中有(id, Delta),它的时间戳是8。在节点1进行compaction冲突解决时,因为8<10,所以SSTable-1中的(id, Alpha)就是最新的数据。
下面的图中,当协调者读取多个数据的时候,假设节点1返回的是(id, Alpha),它的时间戳是10;节点2返回的是主键id和墓碑,并且时间戳也是10。这时墓碑就会胜出,它会覆盖(id, Alpha)中的Alpha,且协调者不会返回任何数据给客户端。
但是在物化视图中,以上这个冲突解决方案就会变得复杂。
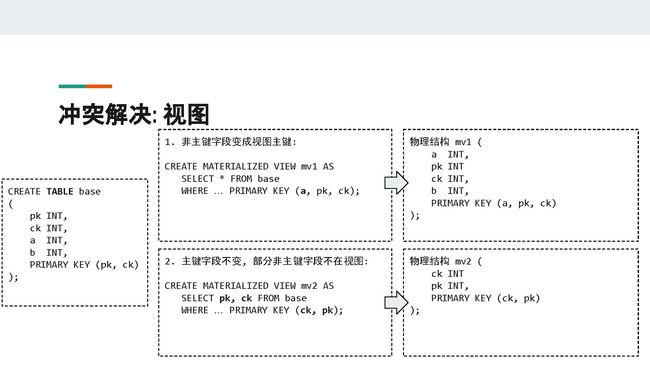
我们先来讲一下物化视图的种类以及其物理结构。一般来说有两种物化视图,第一种就是把基表中的非主键字段变成了物化视图中的主键(例子1);另外一种是主键字段不变,但是字段可能变换顺序且部分非主键的字段不在物化视图里面(例子2)。
PPT中,例子1中基表base中的非主键a在物化视图mv1中变成了主键,它的物理结构是在基表的基础上将a变成了这个分布式表的主键。例子2中物化视图mv2只选取了基表base中的pk和ck,基表中的非主键字段a和b并不在这个物化视图中,它的物理结构是它只有两个元素组成的主键,没有非主键字段。
对于上面提到的第一种物化视图来说,它的语义就是:只要变主键的字段在基表存活,视图数据就存在。如果变主键的字段在基表中不存在或被墓碑覆盖,那么视图数据就不存在。因为该字段是主键的一部分,没有主键就没有数据。
对于上面提到的第二种物化视图来说,它的语义就是:只要有基表数据存在,视图数据就存在。

我们可以从客户端的角度来看一下这个问题。
首先第一个request,找到pk = 1且ck = 2的记录,更新其字段b为4。这时基表中会有(1,2,_,4)这条数据,字段a是没有数据的,所以留空。这时物化视图mv1中是不应该有数据的,因为它的主键a没有数据,整个主键数据并不完整;而物化视图mv2中应该有一条活数据(2,1)。
第二个request中,找到pk = 1且ck = 2的记录,更新其字段a为3。这时基表中的数据会变为(1,2,3,4);物化视图mv1中会有(3,1,2,4),因为它终于有了它所需的所有主键;物化视图mv2还会是和前面一样有(2,1)这条数据。
第三个request中,找到pk = 1且ck = 2的记录,更新其字段a为5。这时基表中的数据会变为(1,2,5,4);在物化视图mv1的储存结构中,它需要把相应的老数据(3,1,2,4)删除,之后再插入一条新数据(5,1,2,4);物化视图mv2不变,有(2,1)这条数据。

但是这造成了一些问题:现有的物化视图的物理结构并不支持这样复杂的语义。所以Cassandra中一共有过三种不同的解决方案,具体请参考Cassandra-11500这个ticket。
第一种方案叫Shadowable tombstone,它是最原始的Cassandra的版本,目前基本属于不可用的状态。因为这种方案导致物化视图的活数据可能会突然读不出来,或是已经被墓碑覆盖的数据突然就可以读出来了。
第二种方案是Cassandra现在采用的机制,叫Strict Liveness。它是一种没有改动储存结构的方法,但是它只支持单一非主键字段变成视图主键的情况,也就是上面提到的第一种物化视图。
最后一种方案,也是今天我想和大家重点分享的一个比较通用的方案,叫做隐藏字段Hidden Columns。我们打算把这个机制开源到Cassandra新的版本里面。
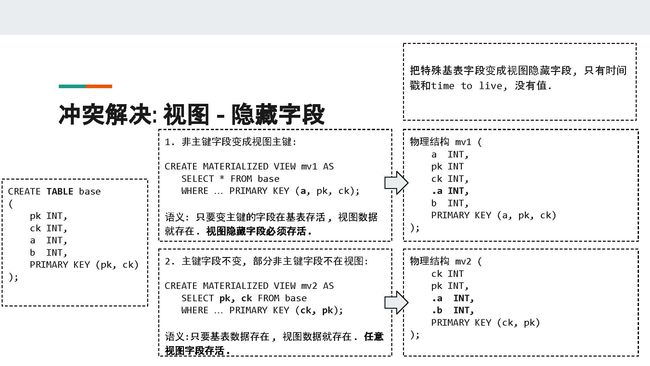
这个方案的原理很简单,就是把所有物化视图需要的时间戳信息从基表中存储到不同的隐藏字段里面。注意,这些特殊字段只包含时间戳和TTL(time to live),并不包含任何值。这样可以减少储存引擎的损耗。
相应地,物化视图的物理结构也有所改变。
对于前面提到的第一种物化视图来说,它的物理结构中出现了一个对应字段a的隐藏字段.a,来承载原本a字段的时间戳信息。因为字段a已经变成视图主键的一部分,所以它是没有单独的时间戳信息的。
对于这种物化视图来说,它解决冲突的语义是:变主键的字段在基表存活,且视图隐藏字段必须存活,视图数据就存在。如果隐藏字段被墓碑覆盖或因为time to live而过期,视图数据会被认为已经死亡,客户端不可以再读取。
对于前面提到的第二种物化视图来说,我们在其中添加了基表中未被选择的字段a和b对应的隐藏字段.a和.b。
对于这种物化视图来说,它解决冲突的语义是:基表数据存在,且任意视图字段存活,视图数据就存在。即.a, .b, ck, pk中的任意一个没有被墓碑覆盖,物化视图都可以返回活的数据。不过隐藏字段是不会返回给客户端的,因为它没有值,只有时间戳。
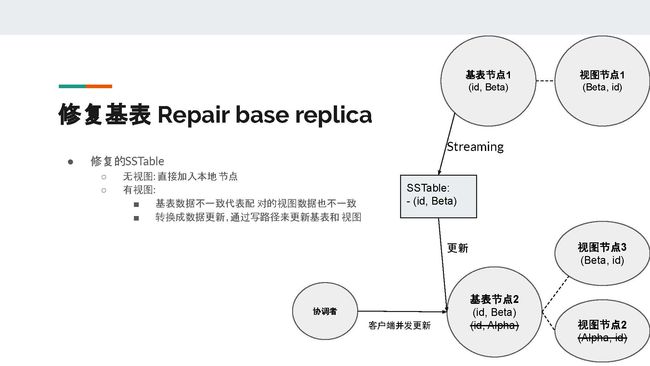
Repair的目的很简单——在Cassandra中,一般为了高可用,我们会使用3副本,读写使用Quorum。这种情况下,某些数据很有可能只存在两个节点。所以为了保证数据的一致性,我们需要定期运行repair。
在Repair的过程中,两个存有副本的节点会比较数据的哈希值,如果不一致,节点就会互相stream不同的SSTable。
在PPT的例子中,基表节点1将它含有(id, Beta)这条数据的SSTable stream给了基表节点2。在没有物化视图的情况下,基表节点2可以把这个SSTable直接并入本地节点。但是在有物化视图的情况下,基表节点的不一致往往也意味着视图的不一致。所以我们需要把收到的SSTable的数据转化为基表的更新,然后通过物化视图的写路径来更新基表和视图。不难想到,这里会出现锁、读后写和batchlog,并且也会和客户端的并发更新来竞争锁。所以Repair的开销是非常大的。
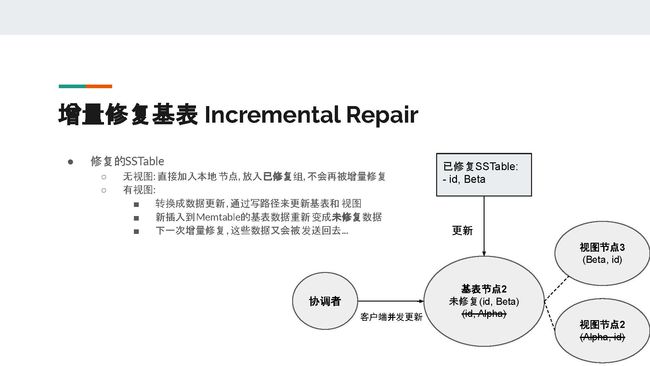
接下来我们来看看Incremental repair增量修复基表。增量修复的概念比较简单,即标记已经修复的SSTable,在增量修复时就可以跳过这些SSTable。
在没有物化视图的情况下,已经修复的SSTable直接并入本地节点,放入已经修复的组里面,在之后的增量修复中不会再被增量修复。但是在有物化视图的情况下,我们需要把增量修复转换成数据更新并通过写路径来更新基表和视图,之后把基表数据插入到memtable。但是新插入基表memtable的数据又会重新变成未修复数据,在下一次修复时,同样的数据又会被传送回去。
所以在有物化视图的基表上面不推荐使用增量修复。
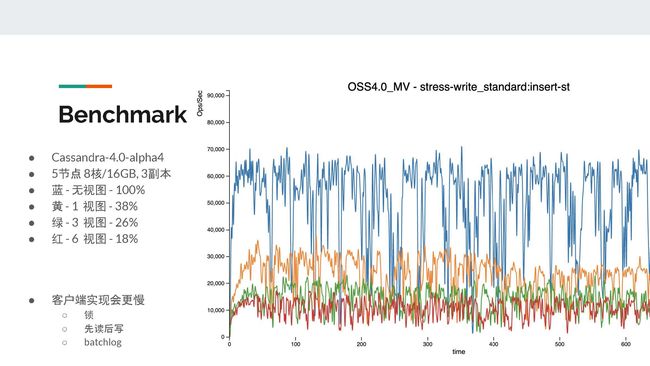
接下来,我们来看一下物化视图为保证一致性所用到的锁、读后写和batchlog对基表写性能的影响。
此处我们使用Cassandra-4.00-alpha版本进行测试,一共5个节点,每个节点是8核/16GB,3副本。图中蓝色部分是在没有物化视图情况下的表现,黄色是1个物化视图,绿色是3个物化视图,红色是6个物化视图。
我们可以看到,添加1个物化视图就已经降低了一半以上的写性能,而6个物化视图时只剩18%左右的throughput。
但是我们要了解,如果由客户端来实现这些物化视图的功能,比如锁、先读后写以及batchlog,客户端的性能只会更慢,而且一致性也会相对更差。所以服务端的物化视图还是有它的优势的。

接下来我分享一下个人对Cassandra物化视图以后的开发的想法。
最重要的一点就是需要更多的一致性的分析和测试来尽可能修复边界情况,继而提高最终一致性。
另外一点就是要尽可能提高写性能。Cassandra现在使用的是写的线程池来进行写的操作,所以不同的线程可能会竞争同一把锁。
我们可以考虑使用DataStax或是Scylla的线程设计,叫Thread Per Core。它使用的是single writer的架构,每个thread会负责一段token range,这样可以减小锁的竞争并提高物化视图的性能。或是利用本地缓存或新的一级索引来加快本地读的性能,这样分区锁所需要的时间也会简短,物化视图的性能也能够提高。
最后一个想法是可以将隐藏字段这个设计加入到开源版本里面,这样我们就可以支持多个基表的字段成为视图的主键,从而能够更灵活地建模。在下面的例子中,我们可以看到名字和年龄同时变成了物化视图的主键。这样在我们query时,我们可以搜索name = "Alpha" AND age = 40。

在使用物化视图时,一定要考虑到分区锁以及read-before-write(读后写)对写入性能的影响,并要做好压力测试。
二是尽量避免大范围删除基表数据(range deletion),因为基表节点需要把所有被影响的物化视图的数据全部读出来从而更新相应的视图节点,这个过程很可能导致内存压力甚至是内存溢出。
第三点,因为视图是异步更新,所以不能保证读你所写(read-your-write)。也就是说当我们向基表插入数据,我们不一定能从视图中读到刚插入的数据。
第四点,要定时修复基表数据,但是注意不要使用增量修复,因为物化视图的写路径破坏了增量修复需要的修复信息。
最后一点,如果你的use case只是插入数据,但从来不更新数据,那么可以考虑通过denormolization(反范式)的方式来建立更多的普通表,从而避免物化视图的锁和读后写之类的开销。
最重要的一点还是要做好压力测试,确保集群能满足你的性能需求,同时最好多留出一些性能空间来避免物化视图相对于基表的更新延迟。由于物化视图的更新是异步的,留有额外的性能空间对于物化视图是有好处的。
希望有更多人参与到Cassandra社区中,不管是分享经验、报告bug还是提出需求,都会让物化视图和整个Cassandra社区越来越好。
以上就是我今天的分享,谢谢大家。